Chapter 4
(auto-generated TOC)
Chapter 5
(auto-generated TOC)
Chapter 6
(auto-generated TOC)
Chapter 7
(auto-generated TOC)
Chapter 8
(auto-generated TOC)
Chapter 10
(auto-generated TOC)
Chapter 11
(auto-generated TOC)
Chapter 12
(auto-generated TOC)
Chapter 15
(auto-generated TOC)
Chapter 17
(auto-generated TOC)
Chapter 18
(auto-generated TOC)
Chapter 19
(auto-generated TOC)
Chapter 20
(auto-generated TOC)
Chapter 21
(auto-generated TOC)
Chapter 23
(auto-generated TOC)

A brief introduction
(automatically generated title slide)
A brief introduction
This was initially written by Jérôme Petazzoni to support in-person, instructor-led workshops and tutorials
Credit is also due to multiple contributors — thank you!
I recommend using the Slack Chat to help you ...
... And be comfortable spending some time reading the Kubernetes documentation ...
... And looking for answers on StackOverflow and other outlets
Hands on, you shall practice
Nobody ever became a Jedi by spending their lives reading Wookiepedia
Likewise, it will take more than merely reading these slides to make you an expert
These slides include tons of exercises and examples
They assume that you have access to a Kubernetes cluster

Pre-requirements
(automatically generated title slide)
Pre-requirements
Be comfortable with the UNIX command line
navigating directories
editing files
a little bit of bash-fu (environment variables, loops)
Some Docker knowledge
docker run,docker ps,docker buildideally, you know how to write a Dockerfile and build it
(even if it's aFROMline and a couple ofRUNcommands)
It's totally OK if you are not a Docker expert!
Tell me and I forget.
Teach me and I remember.
Involve me and I learn.
Misattributed to Benjamin Franklin
(Probably inspired by Chinese Confucian philosopher Xunzi)
Hands-on exercises
The whole workshop is hands-on, with "exercies"
You are invited to reproduce these exercises with me
All exercises are identified with a dashed box plus keyboard icon
This is the stuff you're supposed to do!
Go to https://slides.kubernetesmastery.com to view these slides
Join the chat room: Slack

What and why of orchestration
(automatically generated title slide)
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
We've done this since the dawn of computing: Mainframe schedulers, Puppet, Terraform, AWS, Mesos, Hadoop, etc.
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
We've done this since the dawn of computing: Mainframe schedulers, Puppet, Terraform, AWS, Mesos, Hadoop, etc.
Since 2014 we've had a resurgence of new orchestration projects because:
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
We've done this since the dawn of computing: Mainframe schedulers, Puppet, Terraform, AWS, Mesos, Hadoop, etc.
Since 2014 we've had a resurgence of new orchestration projects because:
- Popularity of distributed computing
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
We've done this since the dawn of computing: Mainframe schedulers, Puppet, Terraform, AWS, Mesos, Hadoop, etc.
Since 2014 we've had a resurgence of new orchestration projects because:
Popularity of distributed computing
Docker containers as a app package and isolated runtime
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
We've done this since the dawn of computing: Mainframe schedulers, Puppet, Terraform, AWS, Mesos, Hadoop, etc.
Since 2014 we've had a resurgence of new orchestration projects because:
Popularity of distributed computing
Docker containers as a app package and isolated runtime
We needed "many servers to act like one, and run many containers"
What and why of orchestration
There are many computing orchestrators
They make decisions about when and where to "do work"
We've done this since the dawn of computing: Mainframe schedulers, Puppet, Terraform, AWS, Mesos, Hadoop, etc.
Since 2014 we've had a resurgence of new orchestration projects because:
Popularity of distributed computing
Docker containers as a app package and isolated runtime
We needed "many servers to act like one, and run many containers"
And the Container Orchestrator was born
Container orchestrator
Many open source projects have been created in the last 5 years to:
- Schedule running of containers on servers
Container orchestrator
Many open source projects have been created in the last 5 years to:
Schedule running of containers on servers
Dispatch them across many nodes
Container orchestrator
Many open source projects have been created in the last 5 years to:
Schedule running of containers on servers
Dispatch them across many nodes
Monitor and react to container and server health
Container orchestrator
Many open source projects have been created in the last 5 years to:
Schedule running of containers on servers
Dispatch them across many nodes
Monitor and react to container and server health
Provide storage, networking, proxy, security, and logging features
Container orchestrator
Many open source projects have been created in the last 5 years to:
Schedule running of containers on servers
Dispatch them across many nodes
Monitor and react to container and server health
Provide storage, networking, proxy, security, and logging features
Do all this in a declarative way, rather than imperative
Container orchestrator
Many open source projects have been created in the last 5 years to:
Schedule running of containers on servers
Dispatch them across many nodes
Monitor and react to container and server health
Provide storage, networking, proxy, security, and logging features
Do all this in a declarative way, rather than imperative
Provide API's to allow extensibility and management
Major container orchestration projects
Kubernetes, aka K8s
Docker Swarm (and Swarm classic)
Apache Mesos/Marathon
Cloud Foundry
Amazon ECS (not OSS, AWS-only)
HashiCorp Nomad
Major container orchestration projects
Kubernetes, aka K8s
Docker Swarm (and Swarm classic)
Apache Mesos/Marathon
Cloud Foundry
Amazon ECS (not OSS, AWS-only)
HashiCorp Nomad
- Many of these tools run on top of Docker Engine
Major container orchestration projects
Kubernetes, aka K8s
Docker Swarm (and Swarm classic)
Apache Mesos/Marathon
Cloud Foundry
Amazon ECS (not OSS, AWS-only)
HashiCorp Nomad
Many of these tools run on top of Docker Engine
Kubernetes is the one orchestrator with many distributions
Kubernetes distributions
- Kubernetes "vanilla upstream" (not a distribution)
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Self-Managed distros: RedHat OpenShift, Docker Enterprise, Rancher, Canonical Charmed, openSUSE Kubic...
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Self-Managed distros: RedHat OpenShift, Docker Enterprise, Rancher, Canonical Charmed, openSUSE Kubic...
Vanilla installers: kubeadm, kops, kubicorn...
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Self-Managed distros: RedHat OpenShift, Docker Enterprise, Rancher, Canonical Charmed, openSUSE Kubic...
Vanilla installers: kubeadm, kops, kubicorn...
Local dev/test: Docker Desktop, minikube, microK8s
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Self-Managed distros: RedHat OpenShift, Docker Enterprise, Rancher, Canonical Charmed, openSUSE Kubic...
Vanilla installers: kubeadm, kops, kubicorn...
Local dev/test: Docker Desktop, minikube, microK8s
CI testing: kind
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Self-Managed distros: RedHat OpenShift, Docker Enterprise, Rancher, Canonical Charmed, openSUSE Kubic...
Vanilla installers: kubeadm, kops, kubicorn...
Local dev/test: Docker Desktop, minikube, microK8s
CI testing: kind
Special builds: Rancher k3s
Kubernetes distributions
Kubernetes "vanilla upstream" (not a distribution)
Cloud-Managed distros: AKS, GKE, EKS, DOK...
Self-Managed distros: RedHat OpenShift, Docker Enterprise, Rancher, Canonical Charmed, openSUSE Kubic...
Vanilla installers: kubeadm, kops, kubicorn...
Local dev/test: Docker Desktop, minikube, microK8s
CI testing: kind
Special builds: Rancher k3s
And Many, many more... (86 as of June 2019)

Kubernetes concepts
(automatically generated title slide)
Kubernetes concepts
Kubernetes is a container management system
It runs and manages containerized applications on a cluster (one or more servers)
Often this is simply called "container orchestration"
Sometimes shortened to Kube or K8s ("Kay-eights" or "Kates")
Basic things we can ask Kubernetes to do
Basic things we can ask Kubernetes to do
- Start 5 containers using image
atseashop/api:v1.3
Basic things we can ask Kubernetes to do
Start 5 containers using image
atseashop/api:v1.3Place an internal load balancer in front of these containers
Basic things we can ask Kubernetes to do
Start 5 containers using image
atseashop/api:v1.3Place an internal load balancer in front of these containers
Start 10 containers using image
atseashop/webfront:v1.3
Basic things we can ask Kubernetes to do
Start 5 containers using image
atseashop/api:v1.3Place an internal load balancer in front of these containers
Start 10 containers using image
atseashop/webfront:v1.3Place a public load balancer in front of these containers
Basic things we can ask Kubernetes to do
Start 5 containers using image
atseashop/api:v1.3Place an internal load balancer in front of these containers
Start 10 containers using image
atseashop/webfront:v1.3Place a public load balancer in front of these containers
It's Black Friday (or Christmas), traffic spikes, grow our cluster and add containers
Basic things we can ask Kubernetes to do
Start 5 containers using image
atseashop/api:v1.3Place an internal load balancer in front of these containers
Start 10 containers using image
atseashop/webfront:v1.3Place a public load balancer in front of these containers
It's Black Friday (or Christmas), traffic spikes, grow our cluster and add containers
New release! Replace my containers with the new image
atseashop/webfront:v1.4
Basic things we can ask Kubernetes to do
Start 5 containers using image
atseashop/api:v1.3Place an internal load balancer in front of these containers
Start 10 containers using image
atseashop/webfront:v1.3Place a public load balancer in front of these containers
It's Black Friday (or Christmas), traffic spikes, grow our cluster and add containers
New release! Replace my containers with the new image
atseashop/webfront:v1.4Keep processing requests during the upgrade; update my containers one at a time
Other things that Kubernetes can do for us
Basic autoscaling
Blue/green deployment, canary deployment
Long running services, but also batch (one-off) and CRON-like jobs
Overcommit our cluster and evict low-priority jobs
Run services with stateful data (databases etc.)
Fine-grained access control defining what can be done by whom on which resources
Integrating third party services (service catalog)
Automating complex tasks (operators)
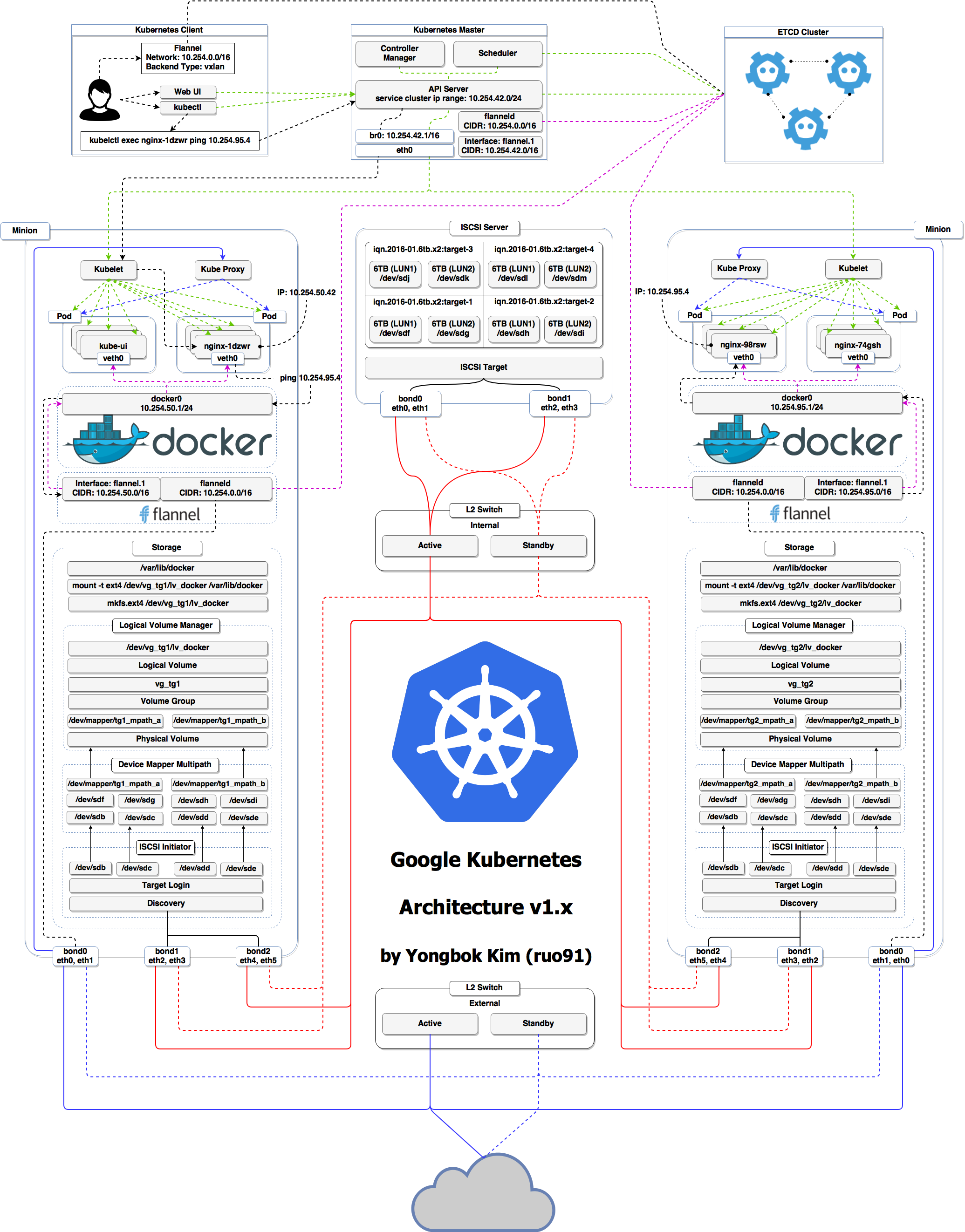
Kubernetes architecture
Ha ha ha ha
OK, I was trying to scare you, it's much simpler than that ❤️
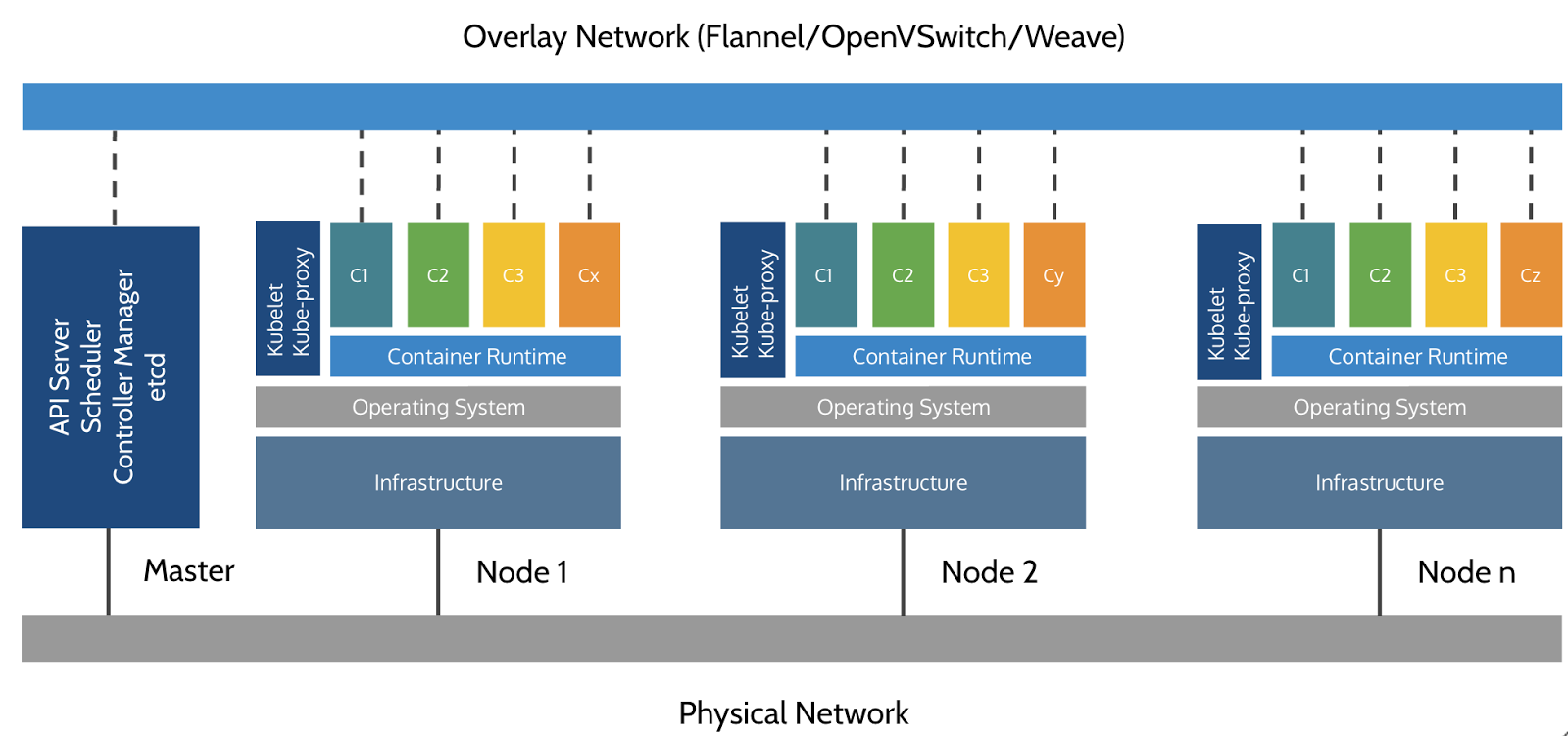
Credits
The first schema is a Kubernetes cluster with storage backed by multi-path iSCSI
(Courtesy of Yongbok Kim)
The second one is a simplified representation of a Kubernetes cluster
(Courtesy of Imesh Gunaratne)
Kubernetes architecture: the nodes
The nodes executing our containers run a collection of services:
a container Engine (typically Docker)
kubelet (the "node agent")
kube-proxy (a necessary but not sufficient network component)
Nodes were formerly called "minions"
(You might see that word in older articles or documentation)
Kubernetes architecture: the control plane
The Kubernetes logic (its "brains") is a collection of services:
the API server (our point of entry to everything!)
core services like the scheduler and controller manager
etcd(a highly available key/value store; the "database" of Kubernetes)
Together, these services form the control plane of our cluster
The control plane is also called the "master"
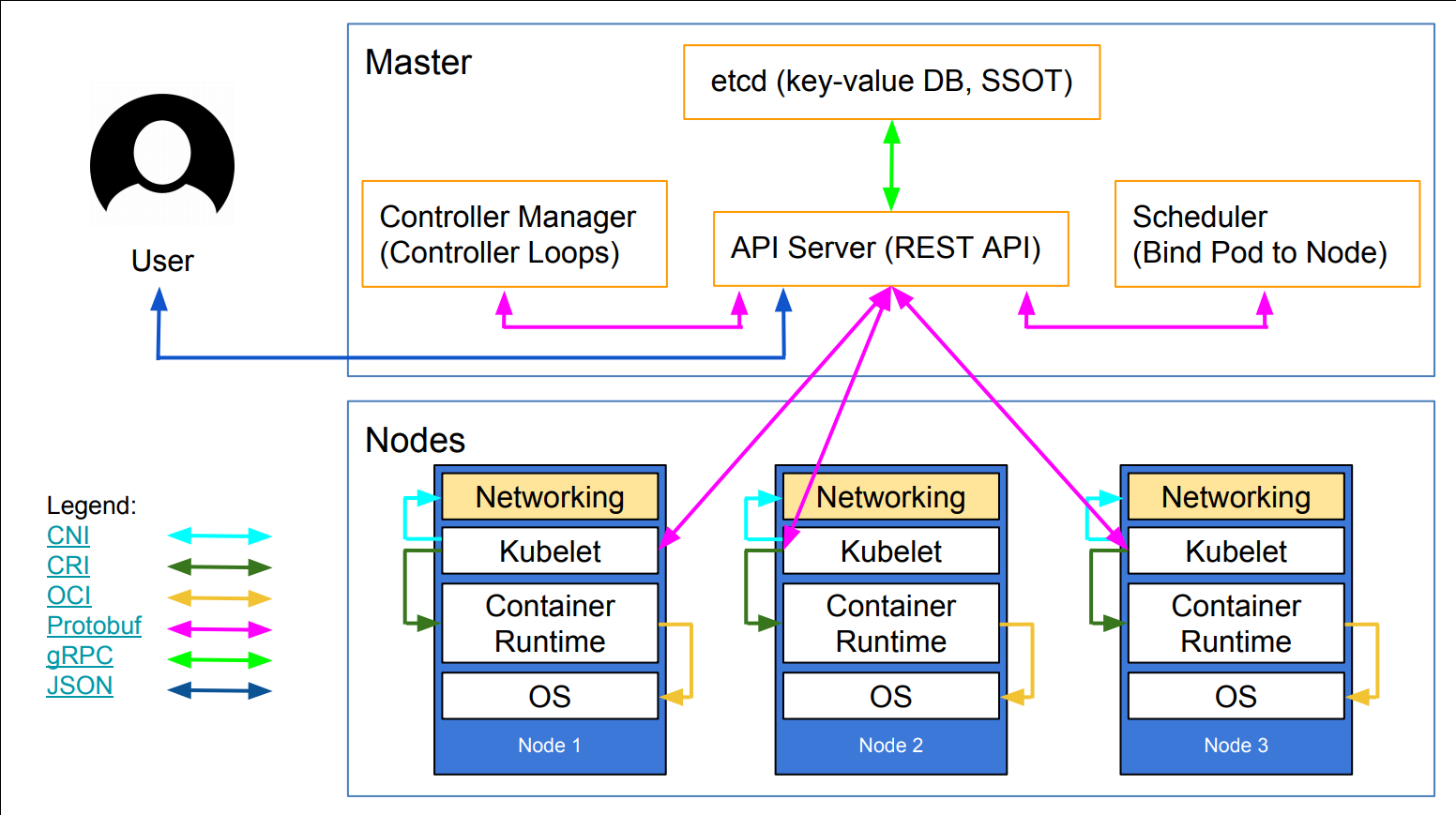
Running the control plane on special nodes
It is common to reserve a dedicated node for the control plane
(Except for single-node development clusters, like when using minikube)
This node is then called a "master"
(Yes, this is ambiguous: is the "master" a node, or the whole control plane?)
Normal applications are restricted from running on this node
(By using a mechanism called "taints")
When high availability is required, each service of the control plane must be resilient
The control plane is then replicated on multiple nodes
(This is sometimes called a "multi-master" setup)
Running the control plane outside containers
The services of the control plane can run in or out of containers
For instance: since
etcdis a critical service, some people deploy it directly on a dedicated cluster (without containers)(This is illustrated on the first "super complicated" schema)
In some hosted Kubernetes offerings (e.g. AKS, GKE, EKS), the control plane is invisible
(We only "see" a Kubernetes API endpoint)
In that case, there is no "master node"
For this reason, it is more accurate to say "control plane" rather than "master."
Do we need to run Docker at all?
No!
Do we need to run Docker at all?
No!
- By default, Kubernetes uses the Docker Engine to run containers
Do we need to run Docker at all?
No!
By default, Kubernetes uses the Docker Engine to run containers
Or leverage other pluggable runtimes through the Container Runtime Interface
Do we need to run Docker at all?
No!
By default, Kubernetes uses the Docker Engine to run containers
Or leverage other pluggable runtimes through the Container Runtime Interface
We could also use(deprecated)rkt("Rocket") from CoreOS
Do we need to run Docker at all?
No!
By default, Kubernetes uses the Docker Engine to run containers
Or leverage other pluggable runtimes through the Container Runtime Interface
We could also use(deprecated)rkt("Rocket") from CoreOScontainerd: maintained by Docker, IBM, and community
Used by Docker Engine, microK8s, k3s, GKE, and standalone; has
ctrCLI
Do we need to run Docker at all?
No!
By default, Kubernetes uses the Docker Engine to run containers
Or leverage other pluggable runtimes through the Container Runtime Interface
We could also use(deprecated)rkt("Rocket") from CoreOScontainerd: maintained by Docker, IBM, and community
Used by Docker Engine, microK8s, k3s, GKE, and standalone; has
ctrCLICRI-O: maintained by Red Hat, SUSE, and community; based on containerd
Used by OpenShift and Kubic, version matched to Kubernetes
Do we need to run Docker at all?
No!
By default, Kubernetes uses the Docker Engine to run containers
Or leverage other pluggable runtimes through the Container Runtime Interface
We could also use(deprecated)rkt("Rocket") from CoreOScontainerd: maintained by Docker, IBM, and community
Used by Docker Engine, microK8s, k3s, GKE, and standalone; has
ctrCLICRI-O: maintained by Red Hat, SUSE, and community; based on containerd
Used by OpenShift and Kubic, version matched to Kubernetes
Do we need to run Docker at all?
Yes!
Do we need to run Docker at all?
Yes!
In this course, we'll run our apps on a single node first
We may need to build images and ship them around
We can do these things without Docker
(and get diagnosed with NIH¹ syndrome)Docker is still the most stable container engine today
(but other options are maturing very quickly)
Do we need to run Docker at all?
On our development environments, CI pipelines ... :
Yes, almost certainly
On our production servers:
Yes (today)
Probably not (in the future)
More information about CRI on the Kubernetes blog
Interacting with Kubernetes
We will interact with our Kubernetes cluster through the Kubernetes API
The Kubernetes API is (mostly) RESTful
It allows us to create, read, update, delete resources
A few common resource types are:
node (a machine — physical or virtual — in our cluster)
pod (group of containers running together on a node)
service (stable network endpoint to connect to one or multiple containers)
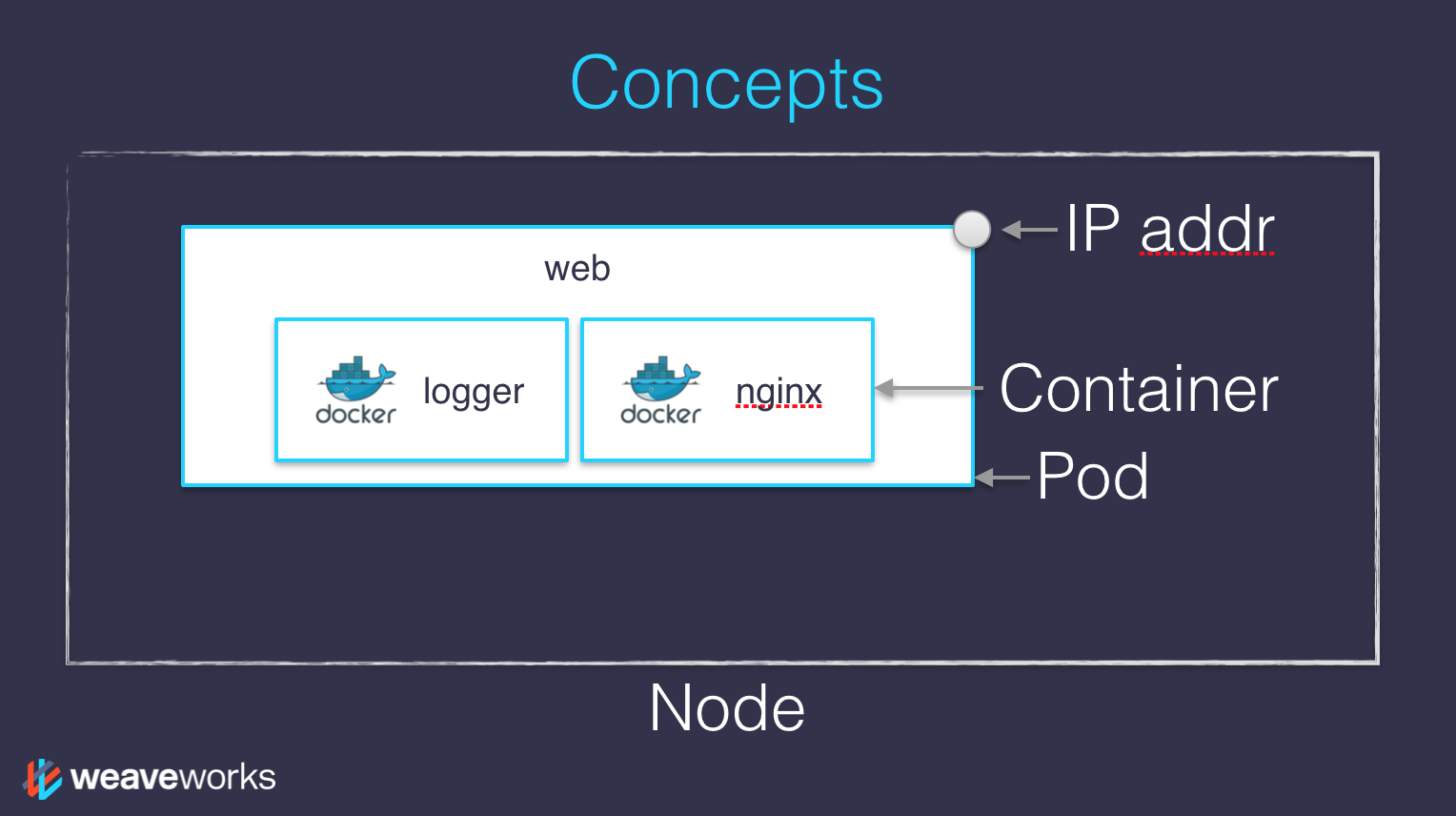
Pods
- Pods are a new abstraction!
Pods
Pods are a new abstraction!
A pod can have multiple containers working together
(But you usually only have on container per pod)
Pods
Pods are a new abstraction!
A pod can have multiple containers working together
(But you usually only have on container per pod)
Pod is our smallest deployable unit; Kubernetes can't mange containers directly
Pods
Pods are a new abstraction!
A pod can have multiple containers working together
(But you usually only have on container per pod)
Pod is our smallest deployable unit; Kubernetes can't mange containers directly
IP addresses are associated with pods, not with individual containers
Containers in a pod share
localhost, and can share volumes
Pods
Pods are a new abstraction!
A pod can have multiple containers working together
(But you usually only have on container per pod)
Pod is our smallest deployable unit; Kubernetes can't mange containers directly
IP addresses are associated with pods, not with individual containers
Containers in a pod share
localhost, and can share volumesMultiple containers in a pod are deployed together
In reality, Docker doesn't know a pod, only containers/namespaces/volumes k8smastery/concepts-k8s.md
Credits
The first diagram is courtesy of Lucas Käldström, in this presentation
- it's one of the best Kubernetes architecture diagrams available!
The second diagram is courtesy of Weaveworks
a pod can have multiple containers working together
IP addresses are associated with pods, not with individual containers
Both diagrams used with permission.

Getting a Kubernetes cluster for learning
(automatically generated title slide)
Getting a Kubernetes cluster for learning
Best: Get a environment locally
- Docker Desktop (Win/macOS/Linux), Rancher Desktop (Win/macOS/Linux), or microk8s (Linux)
- Small setup effort; free; flexible environments
- Requires 2GB+ of memory
Getting a Kubernetes cluster for learning
Best: Get a environment locally
- Docker Desktop (Win/macOS/Linux), Rancher Desktop (Win/macOS/Linux), or microk8s (Linux)
- Small setup effort; free; flexible environments
- Requires 2GB+ of memory
Good: Setup a cloud Linux host to run microk8s
- Great if you don't have the local resources to run Kubernetes
- Small setup effort; only free for a while
- My $50 DigitalOcean coupon lets you run Kubernetes free for a month
Getting a Kubernetes cluster for learning
Best: Get a environment locally
- Docker Desktop (Win/macOS/Linux), Rancher Desktop (Win/macOS/Linux), or microk8s (Linux)
- Small setup effort; free; flexible environments
- Requires 2GB+ of memory
Good: Setup a cloud Linux host to run microk8s
- Great if you don't have the local resources to run Kubernetes
- Small setup effort; only free for a while
- My $50 DigitalOcean coupon lets you run Kubernetes free for a month
Last choice: Use a browser-based solution
- Low setup effort; but host is short-lived and has limited resources
- Not all hands-on examples will work in the browser sandbox
Getting a Kubernetes cluster for learning
Best: Get a environment locally
- Docker Desktop (Win/macOS/Linux), Rancher Desktop (Win/macOS/Linux), or microk8s (Linux)
- Small setup effort; free; flexible environments
- Requires 2GB+ of memory
Good: Setup a cloud Linux host to run microk8s
- Great if you don't have the local resources to run Kubernetes
- Small setup effort; only free for a while
- My $50 DigitalOcean coupon lets you run Kubernetes free for a month
Last choice: Use a browser-based solution
- Low setup effort; but host is short-lived and has limited resources
- Not all hands-on examples will work in the browser sandbox
For all environments, we'll use
shpodcontainer for tools

Docker Desktop (Windows 10/macOS)
(automatically generated title slide)
Docker Desktop (Windows 10/macOS)
- Docker Desktop (DD) is great for a local dev/test setup
Docker Desktop (Windows 10/macOS)
Docker Desktop (DD) is great for a local dev/test setup
Requires modern macOS or Windows 10 Pro/Ent/Edu (no Home)
- Requires Hyper-V, and disables VirtualBox
Docker Desktop (Windows 10/macOS)
Docker Desktop (DD) is great for a local dev/test setup
Requires modern macOS or Windows 10 Pro/Ent/Edu (no Home)
- Requires Hyper-V, and disables VirtualBox
Download Windows or macOS versions and install
For Windows, ensure you pick "Linux Containers" mode
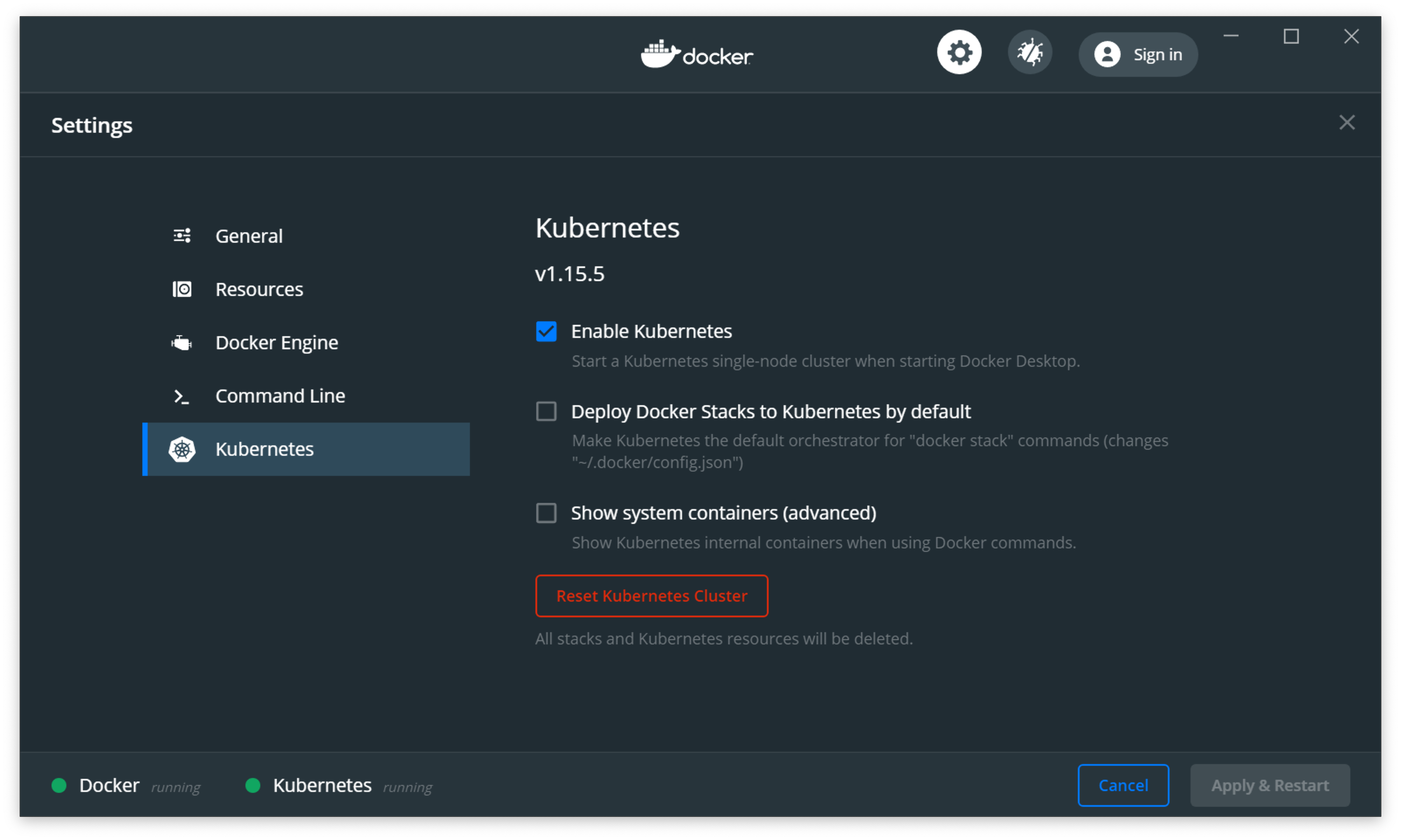
Once running, enabled Kubernetes in Settings/Preferences
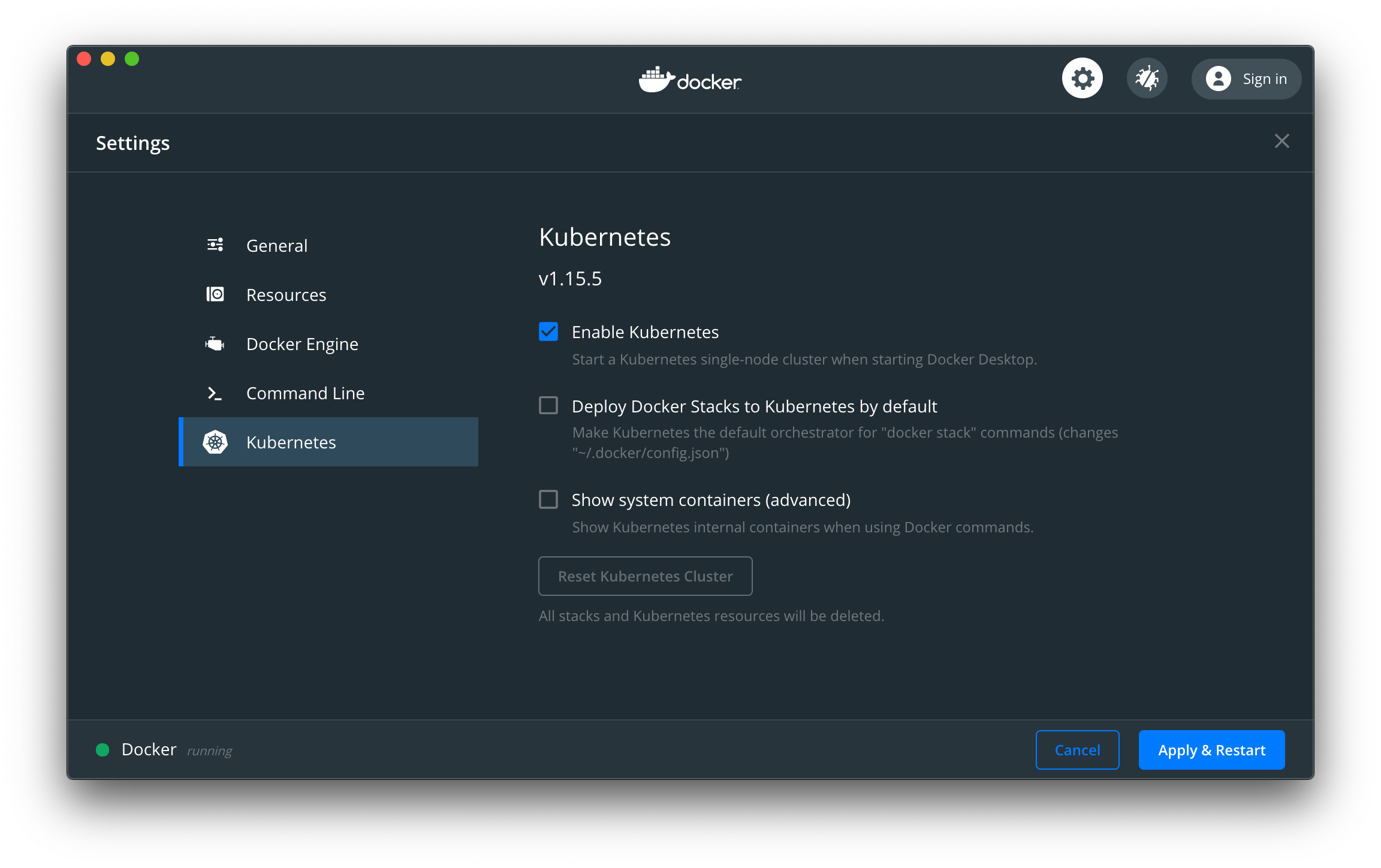

minikube (Windows 10 Home)
(automatically generated title slide)
minikube (Windows 10 Home)
- A good local install option if you can't run Docker Desktop
minikube (Windows 10 Home)
A good local install option if you can't run Docker Desktop
Inspired by Docker Toolbox
- Will create a local VM and configure latest Kubernetes
- Has lots of other features with its
minikubeCLI
minikube (Windows 10 Home)
A good local install option if you can't run Docker Desktop
Inspired by Docker Toolbox
- Will create a local VM and configure latest Kubernetes
Has lots of other features with its
minikubeCLIBut, requires separate install of VirtualBox and kubectl
- May not work with older Windows versions (YMMV)
minikube (Windows 10 Home)
A good local install option if you can't run Docker Desktop
Inspired by Docker Toolbox
- Will create a local VM and configure latest Kubernetes
Has lots of other features with its
minikubeCLIBut, requires separate install of VirtualBox and kubectl
- May not work with older Windows versions (YMMV)
- Download and install VirtualBox
- Download kubectl, and add to $PATH
- Download and install minikube
- Run
minikube startto create and run a Kubernetes VM - Run
minikube stopwhen you're done
minikube (Windows 10 Home)
A good local install option if you can't run Docker Desktop
Inspired by Docker Toolbox
- Will create a local VM and configure latest Kubernetes
Has lots of other features with its
minikubeCLIBut, requires separate install of VirtualBox and kubectl
- May not work with older Windows versions (YMMV)
- Download and install VirtualBox
- Download kubectl, and add to $PATH
- Download and install minikube
- Run
minikube startto create and run a Kubernetes VM - Run
minikube stopwhen you're done
If you get an error about "This computer doesn't have VT-X/AMD-v enabled", you need to enable virtualization in your computer BIOS.
k8smastery/install-minikube.md

MicroK8s (Linux)
(automatically generated title slide)
MicroK8s (Linux)
Easy install and management of local Kubernetes
Made by Canonical (Ubuntu). Installs using
snap. Works nearly everywhere- Has lots of other features with its
microk8sCLI
MicroK8s (Linux)
Easy install and management of local Kubernetes
Made by Canonical (Ubuntu). Installs using
snap. Works nearly everywhereHas lots of other features with its
microk8sCLIBut, requires you install
snapif not on Ubuntu- Runs on containerd rather than Docker, no biggie
- Needs alias setup for
microk8s kubectl
MicroK8s (Linux)
Easy install and management of local Kubernetes
Made by Canonical (Ubuntu). Installs using
snap. Works nearly everywhereHas lots of other features with its
microk8sCLIBut, requires you install
snapif not on Ubuntu- Runs on containerd rather than Docker, no biggie
- Needs alias setup for
microk8s kubectl
- Install
microk8s,change group permissions, then set alias in bashrcsudo snap install microk8s --classicsudo usermod -a -G microk8s <username>echo "alias kubectl='microk8s kubectl'" >> ~/.bashrc# log out and back in if using a non-root user
k8smastery/install-microk8s.md
MicroK8s Additional Info
- We'll need these later (these are done for us in Docker Desktop and minikube):
Create kubectl config file
microk8s kubectl config view --raw > $HOME/.kube/configInstall CoreDNS in Kubernetes
sudo microk8s enable dns
- You can also install other plugins this way like
microk8s enable dashboardormicrok8s enable ingress
k8smastery/install-microk8s.md
MicroK8s Troubleshooting
- Run a check for any config problems
- Test MicroK8s config for any potental problemssudo microk8s inspect
If you also have Docker installed, you can ignore warnings about iptables and registries
See troubleshooting site if you have issues
k8smastery/install-microk8s.md

Web-based options
(automatically generated title slide)
Web-based options
Last choice: Use a browser-based solution
Web-based options
Last choice: Use a browser-based solution
- Low setup effort; but host is short-lived and has limited resources
Web-based options
Last choice: Use a browser-based solution
Low setup effort; but host is short-lived and has limited resources
Services are not always working right, and may not be up to date
Web-based options
Last choice: Use a browser-based solution
Low setup effort; but host is short-lived and has limited resources
Services are not always working right, and may not be up to date
Not all hands-on examples will work in the browser sandbox
- Use a prebuilt Kubernetes server at Katacoda
- Or setup a Kubernetes node at play-with-k8s.com
- Maybe try the latest OpenShift at learn.openshift.com
- See if instruqt works for a Kubernetes playground

shpod: For a consistent Kubernetes experience ...
(automatically generated title slide)
shpod: For a consistent Kubernetes experience ...
You can use shpod for examples
shpodprovides a shell running in a pod on the clusterIt comes with many tools pre-installed (helm, stern, curl, jq...)
These tools are used in many exercises in these slides
shpodalso gives you shell completion and a fancy promptCreate it with
kubectl apply -f https://k8smastery.com/shpod.yamlAttach to shell with
kubectl attach --namespace=shpod -ti shpodAfter finishing course
kubectl delete -f https://k8smastery.com/shpod.yaml

First contact with kubectl
(automatically generated title slide)
First contact with kubectl
kubectlis (almost) the only tool we'll need to talk to KubernetesIt is a rich CLI tool around the Kubernetes API
(Everything you can do with
kubectl, you can do directly with the API)
First contact with kubectl
kubectlis (almost) the only tool we'll need to talk to KubernetesIt is a rich CLI tool around the Kubernetes API
(Everything you can do with
kubectl, you can do directly with the API)On our machines, there is a
~/.kube/configfile with:the Kubernetes API address
the path to our TLS certificates used to authenticate
You can also use the
--kubeconfigflag to pass a config fileOr directly
--server,--user, etc.
First contact with kubectl
kubectlis (almost) the only tool we'll need to talk to KubernetesIt is a rich CLI tool around the Kubernetes API
(Everything you can do with
kubectl, you can do directly with the API)On our machines, there is a
~/.kube/configfile with:the Kubernetes API address
the path to our TLS certificates used to authenticate
You can also use the
--kubeconfigflag to pass a config fileOr directly
--server,--user, etc.kubectlcan be pronounced "Cube C T L", "Cube cuttle", "Cube cuddle"...I'll be using the official name "Cube Control" 😎
kubectl is the new SSH
We often start managing servers with SSH
(installing packages, troubleshooting ...)
At scale, it becomes tedious, repetitive, error-prone
Instead, we use config management, central logging, etc.
In many cases, we still need SSH:
as the underlying access method (e.g. Ansible)
to debug tricky scenarios
to inspect and poke at things
The parallel with kubectl
We often start managing Kubernetes clusters with
kubectl(deploying applications, troubleshooting ...)
At scale (with many applications or clusters), it becomes tedious, repetitive, error-prone
Instead, we use automated pipelines, observability tooling, etc.
In many cases, we still need
kubectl:to debug tricky scenarios
to inspect and poke at things
The Kubernetes API is always the underlying access method
kubectl get
- Let's look at our
Noderesources withkubectl get!
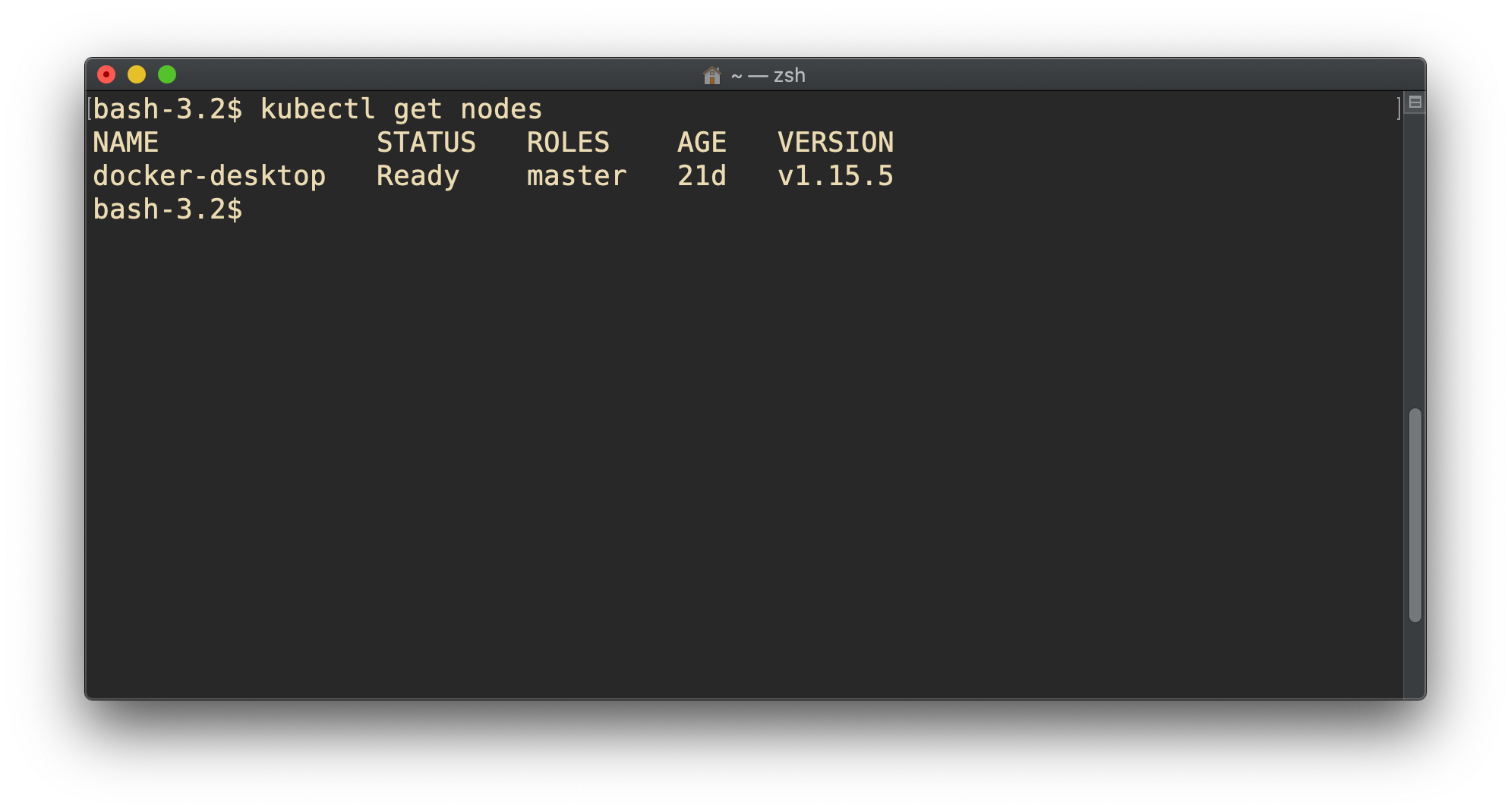
Look at the composition of our cluster:
kubectl get nodeThese commands are equivalent:
kubectl get nokubectl get nodekubectl get nodes
Obtaining machine-readable output
kubectl getcan output JSON, YAML, or be directly formatted
Give us more info about the nodes:
kubectl get nodes -o wideLet's have some YAML:
kubectl get no -o yamlSee that
kind: Listat the end? It's the type of our result!
(Ab)using kubectl and jq
- It's super easy to build custom reports
- Show the capacity of all our nodes as a stream of JSON objects:kubectl get nodes -o json |jq ".items[] | {name:.metadata.name} + .status.capacity"
Viewing details
We can use
kubectl get -o yamlto see all available detailsHowever, YAML output is often simultaneously too much and not enough
For instance,
kubectl get node node1 -o yamlis:too much information (e.g.: list of images available on this node)
not enough information (e.g.: doesn't show pods running on this node)
difficult to read for a human operator
For a comprehensive overview, we can use
kubectl describeinstead
kubectl describe
kubectl describeneeds a resource type and (optionally) a resource nameIt is possible to provide a resource name prefix
(all matching objects will be displayed)
kubectl describewill retrieve some extra information about the resource
- Look at the information available for your node name with one of the following:kubectl describe node/<node>kubectl describe node <node>
(We should notice a bunch of control plane pods.)
Exploring types and definitions
We can list all available resource types by running
kubectl api-resources
(In Kubernetes 1.10 and prior, this command used to bekubectl get)We can view the definition for a resource type with:
kubectl explain typeWe can view the definition of a field in a resource, for instance:
kubectl explain node.specOr get the list of all fields and sub-fields:
kubectl explain node --recursive
Introspection vs. documentation
We can access the same information by reading the API documentation
The API documentation is usually easier to read, but:
it won't show custom types (like Custom Resource Definitions)
we need to make sure that we look at the correct version
kubectl api-resourcesandkubectl explainperform introspection(they communicate with the API server and obtain the exact type definitions)
Type names
The most common resource names have three forms:
singular (e.g.
node,service,deployment)plural (e.g.
nodes,services,deployments)short (e.g.
no,svc,deploy)
Some resources do not have a short name
Endpointsonly have a plural form(because even a single
Endpointsresource is actually a list of endpoints)
More get commands: Services
A service is a stable endpoint to connect to "something"
(In the initial proposal, they were called "portals")
- List the services on our cluster with one of these commands:kubectl get serviceskubectl get svc
More get commands: Services
A service is a stable endpoint to connect to "something"
(In the initial proposal, they were called "portals")
- List the services on our cluster with one of these commands:kubectl get serviceskubectl get svc
There is already one service on our cluster: the Kubernetes API itself.
More get commands: Listing running containers
Containers are manipulated through pods
A pod is a group of containers:
running together (on the same node)
sharing resources (RAM, CPU; but also network, volumes)
- List pods on our cluster:kubectl get pods
More get commands: Listing running containers
Containers are manipulated through pods
A pod is a group of containers:
running together (on the same node)
sharing resources (RAM, CPU; but also network, volumes)
- List pods on our cluster:kubectl get pods
Where are the pods that we saw just a moment earlier?!?
Namespaces
- Namespaces allow us to segregate resources
- List the namespaces on our cluster with one of these commands:kubectl get namespaceskubectl get namespacekubectl get ns
Namespaces
- Namespaces allow us to segregate resources
- List the namespaces on our cluster with one of these commands:kubectl get namespaceskubectl get namespacekubectl get ns
You know what ... This kube-system thing looks suspicious.
In fact, I'm pretty sure it showed up earlier, when we did:
kubectl describe node <node-name>
Accessing namespaces
By default,
kubectluses thedefaultnamespaceWe can see resources in all namespaces with
--all-namespaces
List the pods in all namespaces:
kubectl get pods --all-namespacesSince Kubernetes 1.14, we can also use
-Aas a shorter version:kubectl get pods -A
Here are our system pods!
What are all these control plane pods?
etcdis our etcd serverkube-apiserveris the API serverkube-controller-managerandkube-schedulerare other control plane componentscorednsprovides DNS-based service discovery (replacing kube-dns as of 1.11)kube-proxyis the (per-node) component managing port mappings and such<net name>is the optional (per-node) component managing the network overlaythe
READYcolumn indicates the number of containers in each podNote: this only shows containers, you won't see host svcs (e.g. microk8s)
Also Note: you may see different namespaces depending on setup
Scoping another namespace
- We can also look at a different namespace (other than
default)
- List only the pods in the
kube-systemnamespace:kubectl get pods --namespace=kube-systemkubectl get pods -n kube-system
Namespaces and other kubectl commands
We can use
-n/--namespacewith almost everykubectlcommandExample:
kubectl create --namespace=Xto create something in namespace X
We can use
-A/--all-namespaceswith most commands that manipulate multiple objectsExamples:
kubectl deletecan delete resources across multiple namespaceskubectl labelcan add/remove/update labels across multiple namespaces
What about kube-public?
- List the pods in the
kube-publicnamespace:kubectl -n kube-public get pods
Nothing!
kube-public is created by our installer & used for security bootstrapping.
Exploring kube-public
- The only interesting object in
kube-publicis a ConfigMap namedcluster-info
List ConfigMap objects:
kubectl -n kube-public get configmapsInspect
cluster-info:kubectl -n kube-public get configmap cluster-info -o yaml
Note the selfLink URI: /api/v1/namespaces/kube-public/configmaps/cluster-info
We can use that (later in kubectl context lectures)!
What about kube-node-lease?
Starting with Kubernetes 1.14, there is a
kube-node-leasenamespace(or in Kubernetes 1.13 if the NodeLease feature gate is enabled)
That namespace contains one Lease object per node
Node leases are a new way to implement node heartbeats
(i.e. node regularly pinging the control plane to say "I'm alive!")
For more details, see KEP-0009 or the node controller documentation k8s/kubectlget.md
Services
A service is a stable endpoint to connect to "something"
(In the initial proposal, they were called "portals")
- List the services on our cluster with one of these commands:kubectl get serviceskubectl get svc
Services
A service is a stable endpoint to connect to "something"
(In the initial proposal, they were called "portals")
- List the services on our cluster with one of these commands:kubectl get serviceskubectl get svc
There is already one service on our cluster: the Kubernetes API itself.
ClusterIP services
A
ClusterIPservice is internal, available from the cluster onlyThis is useful for introspection from within containers
Try to connect to the API:
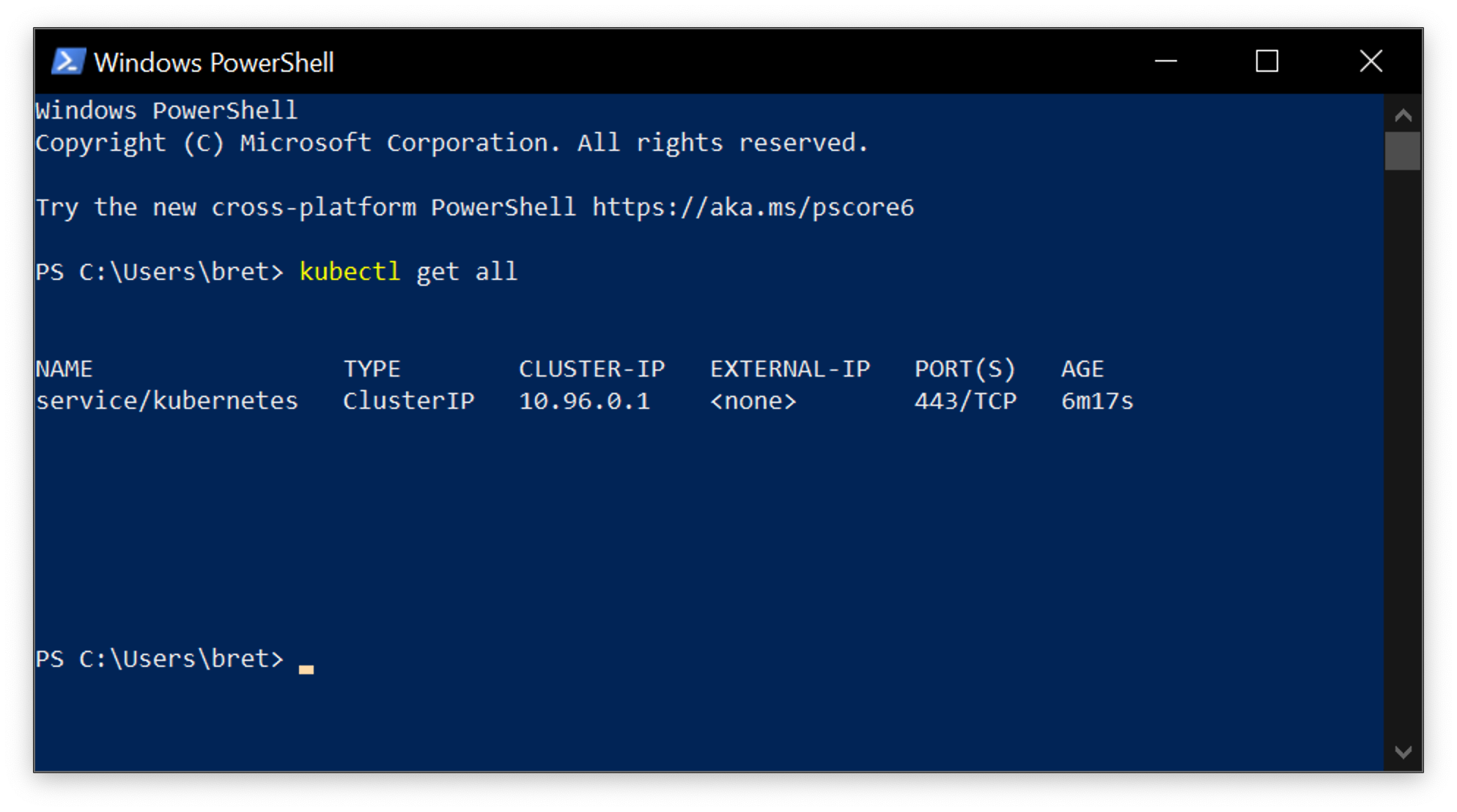
curl -k https://10.96.0.1-kis used to skip certificate verificationMake sure to replace 10.96.0.1 with the CLUSTER-IP shown by
kubectl get svc
The command above should either time out, or show an authentication error. Why?
Time out
Connections to ClusterIP services only work from within the cluster
If we are outside the cluster, the
curlcommand will probably time out(Because the IP address, e.g. 10.96.0.1, isn't routed properly outside the cluster)
This is the case with most "real" Kubernetes clusters
To try the connection from within the cluster, we can use shpod
Authentication error
This is what we should see when connecting from within the cluster:
$ curl -k https://10.96.0.1{ "kind": "Status", "apiVersion": "v1", "metadata": { }, "status": "Failure", "message": "forbidden: User \"system:anonymous\" cannot get path \"/\"", "reason": "Forbidden", "details": { }, "code": 403}Explanations
We can see
kind,apiVersion,metadataThese are typical of a Kubernetes API reply
Because we are talking to the Kubernetes API
The Kubernetes API tells us "Forbidden"
(because it requires authentication)
The Kubernetes API is reachable from within the cluster
(many apps integrating with Kubernetes will use this)
DNS integration
Each service also gets a DNS record
The Kubernetes DNS resolver is available from within pods
(and sometimes, from within nodes, depending on configuration)
Code running in pods can connect to services using their name
(e.g. https://kubernetes/...)

Running our first containers on Kubernetes
(automatically generated title slide)
Running our first containers on Kubernetes
- First things first: we cannot run a container
Running our first containers on Kubernetes
First things first: we cannot run a container
We are going to run a pod, and in that pod there will be a single container
Running our first containers on Kubernetes
First things first: we cannot run a container
We are going to run a pod, and in that pod there will be a single container
In that container in the pod, we are going to run a simple
pingcommandThen we are going to start additional copies of the pod
Starting a simple pod with kubectl run
- We need to specify at least a name and the image we want to use
- Let's ping the address of
localhost, the loopback interface:kubectl run pingpong --image alpine ping 127.0.0.1
Starting a simple pod with kubectl run
- We need to specify at least a name and the image we want to use
- Let's ping the address of
localhost, the loopback interface:kubectl run pingpong --image alpine ping 127.0.0.1
(Starting with Kubernetes 1.12, we get a message telling us that
kubectl run is deprecated. Let's ignore it for now.)
Behind the scenes of kubectl run
- Let's look at the resources that were created by
kubectl run
- List most resource types:kubectl get all
Behind the scenes of kubectl run
- Let's look at the resources that were created by
kubectl run
- List most resource types:kubectl get all
We should see the following things:
deployment.apps/pingpong(the deployment that we just created)replicaset.apps/pingpong-xxxxxxxxxx(a replica set created by the deployment)pod/pingpong-xxxxxxxxxx-yyyyy(a pod created by the replica set)
Note: as of 1.10.1, resource types are displayed in more detail.
What are these different things?
A deployment is a high-level construct
allows scaling, rolling updates, rollbacks
multiple deployments can be used together to implement a canary deployment
delegates pods management to replica sets
A replica set is a low-level construct
makes sure that a given number of identical pods are running
allows scaling
rarely used directly
Note: A replication controller is the deprecated predecessor of a replica set
Our pingpong deployment
kubectl runcreated a deployment,deployment.apps/pingpong
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEdeployment.apps/pingpong 1 1 1 1 10m- That deployment created a replica set,
replicaset.apps/pingpong-xxxxxxxxxx
NAME DESIRED CURRENT READY AGEreplicaset.apps/pingpong-7c8bbcd9bc 1 1 1 10m- That replica set created a pod,
pod/pingpong-xxxxxxxxxx-yyyyy
NAME READY STATUS RESTARTS AGEpod/pingpong-7c8bbcd9bc-6c9qz 1/1 Running 0 10mWe'll see later how these folks play together for:
- scaling, high availability, rolling updates
Viewing container output
Let's use the
kubectl logscommandWe will pass either a pod name, or a type/name
(E.g. if we specify a deployment or replica set, it will get the first pod in it)
Unless specified otherwise, it will only show logs of the first container in the pod
(Good thing there's only one in ours!)
- View the result of our
pingcommand:kubectl logs deploy/pingpong
Streaming logs in real time
Just like
docker logs,kubectl logssupports convenient options:-f/--followto stream logs in real time (à latail -f)--tailto indicate how many lines you want to see (from the end)--sinceto get logs only after a given timestamp
View the latest logs of our
pingcommand:kubectl logs deploy/pingpong --tail 1 --followLeave that command running, so that we can keep an eye on these logs
Scaling our application
- We can create additional copies of our container (I mean, our pod) with
kubectl scale
Scale our
pingpongdeployment:kubectl scale deploy/pingpong --replicas 3Note that this command does exactly the same thing:
kubectl scale deployment pingpong --replicas 3
Note: what if we tried to scale replicaset.apps/pingpong-xxxxxxxxxx?
We could! But the deployment would notice it right away, and scale back to the initial level.
Log streaming
Let's look again at the output of
kubectl logs(the one we started before scaling up)
kubectl logsshows us one line per secondWe could expect 3 lines per second
(since we should now have 3 pods running
ping)Let's try to figure out what's happening!
Streaming logs of multiple pods
- What happens if we restart
kubectl logs?
- Interrupt
kubectl logs(with Ctrl-C)
- Restart it:kubectl logs deploy/pingpong --tail 1 --follow
kubectl logs will warn us that multiple pods were found, and that it's showing us only one of them.
Let's leave kubectl logs running while we keep exploring.
Resilience
The deployment
pingpongwatches its replica setThe replica set ensures that the right number of pods are running
What happens if pods disappear?
- In a separate window, watch the list of pods:watch kubectl get pods
- Destroy the pod currently shown by
kubectl logs:kubectl delete pod pingpong-xxxxxxxxxx-yyyyy
What happened?
kubectl delete podterminates the pod gracefully(sending it the TERM signal and waiting for it to shutdown)
As soon as the pod is in "Terminating" state, the Replica Set replaces it
But we can still see the output of the "Terminating" pod in
kubectl logsUntil 30 seconds later, when the grace period expires
The pod is then killed, and
kubectl logsexits
What if we wanted something different?
What if we wanted to start a "one-shot" container that doesn't get restarted?
We could use
kubectl run --restart=OnFailureorkubectl run --restart=NeverThese commands would create jobs or pods instead of deployments
Under the hood,
kubectl runinvokes "generators" to create resource descriptionsWe could also write these resource descriptions ourselves (typically in YAML),
and create them on the cluster withkubectl apply -f(discussed later)With
kubectl run --schedule=..., we can also create cronjobs
Scheduling periodic background work
A Cron Job is a job that will be executed at specific intervals
(the name comes from the traditional cronjobs executed by the UNIX crond)
It requires a schedule, represented as five space-separated fields:
- minute [0,59]
- hour [0,23]
- day of the month [1,31]
- month of the year [1,12]
- day of the week ([0,6] with 0=Sunday)
*means "all valid values";/Nmeans "every N"Example:
*/3 * * * *means "every three minutes"
Creating a Cron Job
Let's create a simple job to be executed every three minutes
Cron Jobs need to terminate, otherwise they'd run forever
Create the Cron Job:
kubectl run every3mins --schedule="*/3 * * * *" --restart=OnFailure \--image=alpine sleep 10Check the resource that was created:
kubectl get cronjobs
Cron Jobs in action
At the specified schedule, the Cron Job will create a Job
The Job will create a Pod
The Job will make sure that the Pod completes
(re-creating another one if it fails, for instance if its node fails)
- Check the Jobs that are created:kubectl get jobs
(It will take a few minutes before the first job is scheduled.)
What about that deprecation warning?
As we can see from the previous slide,
kubectl runcan do many thingsThe exact type of resource created is not obvious
To make things more explicit, it is better to use
kubectl create:kubectl create deploymentto create a deploymentkubectl create jobto create a jobkubectl create cronjobto run a job periodically
(since Kubernetes 1.14)
Eventually,
kubectl runwill be used only to start one-shot pods
Various ways of creating resources
kubectl run- easy way to get started
- versatile
kubectl create <resource>- explicit, but lacks some features
- can't create a CronJob before Kubernetes 1.14
- can't pass command-line arguments to deployments
kubectl create -f foo.yamlorkubectl apply -f foo.yaml- all features are available
- requires writing YAML
Viewing logs of multiple pods
When we specify a deployment name, only one single pod's logs are shown
We can view the logs of multiple pods by specifying a selector
A selector is a logic expression using labels
Conveniently, when you
kubectl run somename, the associated objects have arun=somenamelabel
- View the last line of log from all pods with the
run=pingponglabel:kubectl logs -l run=pingpong --tail 1
Streaming logs of multiple pods
- Can we stream the logs of all our
pingpongpods?
- Combine
-land-fflags:kubectl logs -l run=pingpong --tail 1 -f
Note: combining -l and -f is only possible since Kubernetes 1.14!
Let's try to understand why ...
Streaming logs of many pods
- Let's see what happens if we try to stream the logs for more than 5 pods
Scale up our deployment:
kubectl scale deployment pingpong --replicas=8Stream the logs:
kubectl logs -l run=pingpong --tail 1 -f
We see a message like the following one:
error: you are attempting to follow 8 log streams,but maximum allowed concurency is 5,use --max-log-requests to increase the limitWhy can't we stream the logs of many pods?
kubectlopens one connection to the API server per podFor each pod, the API server opens one extra connection to the corresponding kubelet
If there are 1000 pods in our deployment, that's 1000 inbound + 1000 outbound connections on the API server
This could easily put a lot of stress on the API server
Prior Kubernetes 1.14, it was decided to not allow multiple connections
From Kubernetes 1.14, it is allowed, but limited to 5 connections
(this can be changed with
--max-log-requests)For more details about the rationale, see PR #67573
Shortcomings of kubectl logs
We don't see which pod sent which log line
If pods are restarted / replaced, the log stream stops
If new pods are added, we don't see their logs
To stream the logs of multiple pods, we need to write a selector
There are external tools to address these shortcomings
(e.g.: Stern)
kubectl logs -l ... --tail N
If we run this with Kubernetes 1.12, the last command shows multiple lines
This is a regression when
--tailis used together with-l/--selectorIt always shows the last 10 lines of output for each container
(instead of the number of lines specified on the command line)
The problem was fixed in Kubernetes 1.13
See #70554 for details.
Party tricks involving IP addresses
It is possible to specify an IP address with less than 4 bytes
(example:
127.1)Zeroes are then inserted in the middle
As a result,
127.1expands to127.0.0.1So we can
ping 127.1to pinglocalhost!
(See this blog post for more details.)
More party tricks with IP addresses
We can also ping
1.11.1will expand to1.0.0.1This is one of the addresses of Cloudflare's public DNS resolver
This is a quick way to check connectivity
(if we can reach 1.1, we probably have internet access)

Accessing logs from the CLI
(automatically generated title slide)
Accessing logs from the CLI
The
kubectl logscommand has limitations:it cannot stream logs from multiple pods at a time
when showing logs from multiple pods, it mixes them all together
We are going to see how to do it better
Doing it manually
We could (if we were so inclined) write a program or script that would:
take a selector as an argument
enumerate all pods matching that selector (with
kubectl get -l ...)fork one
kubectl logs --follow ...command per containerannotate the logs (the output of each
kubectl logs ...process) with their originpreserve ordering by using
kubectl logs --timestamps ...and merge the output
Doing it manually
We could (if we were so inclined) write a program or script that would:
take a selector as an argument
enumerate all pods matching that selector (with
kubectl get -l ...)fork one
kubectl logs --follow ...command per containerannotate the logs (the output of each
kubectl logs ...process) with their originpreserve ordering by using
kubectl logs --timestamps ...and merge the output
We could do it, but thankfully, others did it for us already!
Stern
Stern is an open source project originally by Wercker.
From the README:
Stern allows you to tail multiple pods on Kubernetes and multiple containers within the pod. Each result is color coded for quicker debugging.
The query is a regular expression so the pod name can easily be filtered and you don't need to specify the exact id (for instance omitting the deployment id). If a pod is deleted it gets removed from tail and if a new pod is added it automatically gets tailed.
Exactly what we need!
Checking if Stern is installed
Run
stern(without arguments) to check if it's installed:$ sternTail multiple pods and containers from KubernetesUsage:stern pod-query [flags]If it's missing, let's see how to install it
Installing Stern
Stern is written in Go
Go programs are usually very easy to install
(no dependencies, extra libraries to install, etc)
Binary releases are available on GitHub
Stern is also available through most package managers
(e.g. on macOS, we can
brew install sternorsudo port install stern) k8s/logs-cli.md
Using Stern
There are two ways to specify the pods whose logs we want to see:
-lfollowed by a selector expression (like with manykubectlcommands)with a "pod query," i.e. a regex used to match pod names
These two ways can be combined if necessary
- View the logs for all the pingpong containers:stern pingpong
Stern convenient options
The
--tail Nflag shows the lastNlines for each container(Instead of showing the logs since the creation of the container)
The
-t/--timestampsflag shows timestampsThe
--all-namespacesflag is self-explanatory
- View what's up with the
weavesystem containers:stern --tail 1 --timestamps --all-namespaces weave
Using Stern with a selector
When specifying a selector, we can omit the value for a label
This will match all objects having that label (regardless of the value)
Everything created with
kubectl runhas a labelrunEverything created with
kubectl create deploymenthas a labelappWe can use that property to view the logs of all the pods created with
kubectl create deployment
- View the logs for all the things started with
kubectl create deployment:stern -l app
:EN:- Viewing pod logs from the CLI :FR:- Consulter les logs des pods depuis la CLI k8s/logs-cli.md
Cleanup
Let's cleanup before we start the next lecture!
- remove our deployment and cronjob:kubectl delete deployment/pingpong cronjob/sleep
k8smastery/cleanup-pingpong-sleep.md

Assignment 1: first steps
(automatically generated title slide)
Assignment 1: first steps
Answer these questions with the kubectl command you'd use to get the answer:
Cluster inventory
1.1. How many nodes does your cluster have?
1.2. What kernel version and what container engine is each node running?
(answers on next slide)
Answers
1.1. We can get a list of nodes with kubectl get nodes.
1.2. kubectl get nodes -o wide will list extra information for each node.
This will include kernel version and container engine.
Assignment 1: first steps
Control plane examination
2.1. List only the pods in the kube-system namespace.
2.2. Explain the role of some of these pods.
2.3. If there are few or no pods in kube-system, why could that be?
(answers on next slide)
Answers
2.1. kubectl get pods --namespace=kube-system
2.2. This depends on how our cluster was set up.
On some clusters, we might see pods named etcd-XXX, kube-apiserver-XXX: these correspond to control plane components.
It's also common to see kubedns-XXX or coredns-XXX: these implement the DNS service that lets us resolve service names into their ClusterIP address.
2.3. On some clusters, the control plane is located outside the cluster itself.
In that case, the control plane won't show up in kube-system, but you can find on host with ps aux | grep kube.
Assignment 1: first steps
Running containers
3.1. Create a deployment using kubectl create that runs the image bretfisher/clock and name it ticktock.
3.2. Start 2 more containers of that image in the ticktock deployment.
3.3. Use a selector to output only the last line of logs of each container.
(answers on next slide)
Answers
3.1. kubectl create deployment ticktock --image=bretfisher/clock
By default, it will have one replica, translating to one container.
3.2. kubectl scale deployment ticktock --replicas=3
This will scale the deployment to three replicas (two more containers).
3.3. kubectl logs --selector=app=ticktock --tail=1
All the resources created with kubectl create deployment xxx will have the label app=xxx.
If you needed to use a pod selector, you can see them in the resource that created them.
In this case that's the ReplicaSet, so kubectl describe replicaset ticktock-xxxxx would help.
Therefore, we use the selector app=ticktock here to match all the pods belonging to this deployment.
19,000 words
They say, "a picture is worth one thousand words."
The following 19 slides show what really happens when we run:
kubectl run web --image=nginx --replicas=3



















Exposing containers
(automatically generated title slide)
Exposing containers
We can connect to our pods using their IP address
Then we need to figure out a lot of things:
how do we look up the IP address of the pod(s)?
how do we connect from outside the cluster?
how do we load balance traffic?
what if a pod fails?
Kubernetes has a resource type named Service
Services address all these questions!
Services in a nutshell
Services give us a stable endpoint to connect to a pod or a group of pods
An easy way to create a service is to use
kubectl exposeIf we have a deployment named
my-little-deploy, we can run:kubectl expose deployment my-little-deploy --port=80... and this will create a service with the same name (
my-little-deploy)Services are automatically added to an internal DNS zone
(in the example above, our code can now connect to http://my-little-deploy/)
Advantages of services
We don't need to look up the IP address of the pod(s)
(we resolve the IP address of the service using DNS)
There are multiple service types; some of them allow external traffic
(e.g.
LoadBalancerandNodePort)Services provide load balancing
(for both internal and external traffic)
Service addresses are independent from pods' addresses
(when a pod fails, the service seamlessly sends traffic to its replacement)
Many kinds and flavors of service
There are different types of services:
ClusterIP,NodePort,LoadBalancer,ExternalNameThere are also headless services
Services can also have optional external IPs
There is also another resource type called Ingress
(specifically for HTTP services)
Wow, that's a lot! Let's start with the basics ...
ClusterIP
It's the default service type
A virtual IP address is allocated for the service
(in an internal, private range; e.g. 10.96.0.0/12)
This IP address is reachable only from within the cluster (nodes and pods)
Our code can connect to the service using the original port number
Perfect for internal communication, within the cluster
LoadBalancer
An external load balancer is allocated for the service
(typically a cloud load balancer, e.g. ELB on AWS, GLB on GCE ...)
This is available only when the underlying infrastructure provides some kind of "load balancer as a service"
Each service of that type will typically cost a little bit of money
(e.g. a few cents per hour on AWS or GCE)
Ideally, traffic would flow directly from the load balancer to the pods
In practice, it will often flow through a
NodePortfirst
NodePort
A port number is allocated for the service
(by default, in the 30000-32767 range)
That port is made available on all our nodes and anybody can connect to it
(we can connect to any node on that port to reach the service)
Our code needs to be changed to connect to that new port number
Under the hood:
kube-proxysets up a bunch ofiptablesrules on our nodesSometimes, it's the only available option for external traffic
(e.g. most clusters deployed with kubeadm or on-premises)
Running containers with open ports
Since
pingdoesn't have anything to connect to, we'll have to run something elseWe could use the
nginxofficial image, but ...... we wouldn't be able to tell the backends from each other!
We are going to use
bretfisher/httpenv, a tiny HTTP server written in Gobretfisher/httpenvlistens on port 8888It serves its environment variables in JSON format
The environment variables will include
HOSTNAME, which will be the pod name(and therefore, will be different on each backend)
Creating a deployment for our HTTP server
We could do
kubectl run httpenv --image=bretfisher/httpenv...But since
kubectl runis changing, let's see how to usekubectl createinstead
- In another window, watch the pods (to see when they are created):kubectl get pods -w
Create a deployment for this very lightweight HTTP server:
kubectl create deployment httpenv --image=bretfisher/httpenvScale it to 10 replicas:
kubectl scale deployment httpenv --replicas=10
Exposing our deployment
- We'll create a default
ClusterIPservice
Expose the HTTP port of our server:
kubectl expose deployment httpenv --port 8888Look up which IP address was allocated:
kubectl get service
Services are layer 4 constructs
You can assign IP addresses to services, but they are still layer 4
(i.e. a service is not an IP address; it's an IP address + protocol + port)
This is caused by the current implementation of
kube-proxy(it relies on mechanisms that don't support layer 3)
As a result: you have to indicate the port number for your service
(with some exceptions, like
ExternalNameor headless services, covered later)
Testing our service
- We will now send a few HTTP requests to our pods
Run
shpodif not on Linux host so we can access internal ClusterIPkubectl attach --namespace=shpod -ti shpodLet's obtain the IP address that was allocated for our service, programmatically:
IP=$(kubectl get svc httpenv -o go-template --template '{{ .spec.clusterIP }}')
Send a few requests:
curl http://$IP:8888/Too much output? Filter it with
jq:curl -s http://$IP:8888/ | jq .HOSTNAME
ExternalName
Services of type
ExternalNameare quite differentNo load balancer (internal or external) is created
Only a DNS entry gets added to the DNS managed by Kubernetes
That DNS entry will just be a
CNAMEto a provided record
Example:
kubectl create service externalname k8s --external-name kubernetes.ioCreates a CNAME k8s pointing to kubernetes.io
External IPs
We can add an External IP to a service, e.g.:
kubectl expose deploy my-little-deploy --port=80 --external-ip=1.2.3.41.2.3.4should be the address of one of our nodes(it could also be a virtual address, service address, or VIP, shared by multiple nodes)
Connections to
1.2.3.4:80will be sent to our serviceExternal IPs will also show up on services of type
LoadBalancer(they will be added automatically by the process provisioning the load balancer)
Headless services
Sometimes, we want to access our scaled services directly:
if we want to save a tiny little bit of latency (typically less than 1ms)
if we need to connect over arbitrary ports (instead of a few fixed ones)
if we need to communicate over another protocol than UDP or TCP
if we want to decide how to balance the requests client-side
...
In that case, we can use a "headless service"
Creating a headless services
A headless service is obtained by setting the
clusterIPfield toNone(Either with
--cluster-ip=None, or by providing a custom YAML)As a result, the service doesn't have a virtual IP address
Since there is no virtual IP address, there is no load balancer either
CoreDNS will return the pods' IP addresses as multiple
ArecordsThis gives us an easy way to discover all the replicas for a deployment
Services and endpoints
A service has a number of "endpoints"
Each endpoint is a host + port where the service is available
The endpoints are maintained and updated automatically by Kubernetes
- Check the endpoints that Kubernetes has associated with our
httpenvservice:kubectl describe service httpenv
In the output, there will be a line starting with Endpoints:.
That line will list a bunch of addresses in host:port format.
Viewing endpoint details
When we have many endpoints, our display commands truncate the list
kubectl get endpointsIf we want to see the full list, we can use a different output:
kubectl get endpoints httpenv -o yamlThese IP addresses should match the addresses of the corresponding pods:
kubectl get pods -l app=httpenv -o wide
endpoints not endpoint
endpointsis the only resource that cannot be singular
$ kubectl get endpointerror: the server doesn't have a resource type "endpoint"This is because the type itself is plural (unlike every other resource)
There is no
endpointobject:type Endpoints structThe type doesn't represent a single endpoint, but a list of endpoints
The DNS zone
In the
kube-systemnamespace, there should be a service namedkube-dnsThis is the internal DNS server that can resolve service names
The default domain name for the service we created is
default.svc.cluster.local
Get the IP address of the internal DNS server:
IP=$(kubectl -n kube-system get svc kube-dns -o jsonpath={.spec.clusterIP})Resolve the cluster IP for the
httpenvservice:host httpenv.default.svc.cluster.local $IP
Ingress
Ingresses are another type (kind) of resource
They are specifically for HTTP services
(not TCP or UDP)
They can also handle TLS certificates, URL rewriting ...
They require an Ingress Controller to function
Cleanup
Let's cleanup before we start the next lecture!
- remove our httpenv resources:kubectl delete deployment/httpenv service/httpenv
Kubernetes network model
(automatically generated title slide)
Kubernetes network model
TL,DR:
Our cluster (nodes and pods) is one big flat IP network.
Kubernetes network model
TL,DR:
Our cluster (nodes and pods) is one big flat IP network.
In detail:
all nodes must be able to reach each other, without NAT
all pods must be able to reach each other, without NAT
pods and nodes must be able to reach each other, without NAT
each pod is aware of its IP address (no NAT)
pod IP addresses are assigned by the network implementation
Kubernetes doesn't mandate any particular implementation
Kubernetes network model: the good
Everything can reach everything
No address translation
No port translation
No new protocol
The network implementation can decide how to allocate addresses
IP addresses don't have to be "portable" from a node to another
(For example, We can use a subnet per node and use a simple routed topology)
The specification is simple enough to allow many various implementations
Kubernetes network model: the less good
Everything can reach everything
if you want security, you need to add network policies
the network implementation you use needs to support them
There are literally dozens of implementations out there
(15 are listed in the Kubernetes documentation)
Pods have level 3 (IP) connectivity, but services are level 4 (TCP or UDP)
(Services map to a single UDP or TCP port; no port ranges or arbitrary IP packets)
kube-proxyis on the data path when connecting to a pod or container,
and it's not particularly fast (relies on userland proxying or iptables)
Kubernetes network model: in practice
The nodes we are using have been set up to use kubenet, Calico, or something else
Don't worry about the warning about
kube-proxyperformanceUnless you:
- routinely saturate 10G network interfaces
- count packet rates in millions per second
- run high-traffic VOIP or gaming platforms
- do weird things that involve millions of simultaneous connections
(in which case you're already familiar with kernel tuning)
If necessary, there are alternatives to
kube-proxy; e.g.kube-router
The Container Network Interface (CNI)
Most Kubernetes clusters use CNI "plugins" to implement networking
When a pod is created, Kubernetes delegates the network setup to these plugins
(it can be a single plugin, or a combination of plugins, each doing one task)
Typically, CNI plugins will:
allocate an IP address (by calling an IPAM plugin)
add a network interface into the pod's network namespace
configure the interface as well as required routes, etc.
Multiple moving parts
The "pod-to-pod network" or "pod network":
provides communication between pods and nodes
is generally implemented with CNI plugins
The "pod-to-service network":
provides internal communication and load balancing
is generally implemented with kube-proxy (or maybe kube-router)
Network policies:
provide firewalling and isolation
can be bundled with the "pod network" or provided by another component
Even more moving parts
Inbound traffic can be handled by multiple components:
something like kube-proxy or kube-router (for NodePort services)
load balancers (ideally, connected to the pod network)
It is possible to use multiple pod networks in parallel
(with "meta-plugins" like CNI-Genie or Multus)
Some solutions can fill multiple roles
(e.g. kube-router can be set up to provide the pod network and/or network policies and/or replace kube-proxy)
Assignment 2: more about deployments
(automatically generated title slide)
Assignment 2: more about deployments
Create a deployment called
littletomcatusing thetomcatimage.What command will help you get the IP address of that Tomcat server?
What steps would you take to ping it from another container?
(Use the
shpodenvironment if necessary.)What command would delete the running pod inside that deployment?
What happens if we delete the pod that holds Tomcat, while the ping is running?
(answers on next two slides)
assignments/02kubectlexpose.md
Answers
kubectl create deployment littletomcat --image=tomcatList all pods with label
app=littletomcat, with extra details including IP address:kubectl get pods --selector=app=littletomcat -o wide. You could also describe the pod:kubectl describe pod littletomcat-XXX-XXXStart a shell inside the cluster: One way to start a shell inside the cluster:
kubectl apply -f https://k8smastery.com/shpod.yamlthenkubectl attach --namespace=shpod -ti shpod
A easier way is to use a special domain we created
curl https://shpod.sh | shThen the IP address of the pod should ping correctly. You could also start a deployment or pod temporarily (like nginx), then exec in, install ping, and ping the IP.
assignments/02kubectlexpose.md
Answers
We can delete the pod with:
kubectl delete pods --selector=app=littletomcator copy/paste the exact pod name and delete it.If we delete the pod, the following things will happen:
the pod will be gracefully terminated,
the ping command that we left running will fail,
the replica set will notice that it doens't have the right count of pods and create a replacement pod,
that new pod will have a different IP address (so the
pingcommand won't recover).
assignments/02kubectlexpose.md
Assignment 2: first service
What command can give our Tomcat server a stable DNS name and IP address?
(An address that doesn't change when something bad happens to the container.)
What commands would you run to curl Tomcat with that DNS address?
(Use the
shpodenvironment if necessary.)If we delete the pod that holds Tomcat, does the IP address still work?
(answers on next slide)
assignments/02kubectlexpose.md
Answers
We need to create a Service for our deployment, which will have a ClusterIP that is usable from within the cluster. One way is with
kubectl expose deployment littletomcat --port=8080(The Tomcat image is listening on port 8080 according to Docker Hub). Another way is withkubectl create service clusterip littletomcat --tcp 8080In the
shpodenvironment that we started earlier:# Install curlapk add curl# Make a request to the littletomcat service (in a different namespace)curl http://littletomcat.default:8080Note that shpod runs in the shpod namespace, so to find a DNS name of a different namespace in the same cluster, you should use
<hostname>.<namespace>syntax. That was a little advanced, so A+ if you got it on the first try!Yes. If we delete the pod, another will be created to replace it. The ClusterIP will still work.
(Except during a short period while the replacement container is being started.)
assignments/02kubectlexpose.md
Our sample application
(automatically generated title slide)
What's this application?
What's this application?
- It is a DockerCoin miner! 💰🐳📦🚢
What's this application?
It is a DockerCoin miner! 💰🐳📦🚢
No, you can't buy coffee with DockerCoins
What's this application?
It is a DockerCoin miner! 💰🐳📦🚢
No, you can't buy coffee with DockerCoins
How DockerCoins works:
generate a few random bytes
hash these bytes
increment a counter (to keep track of speed)
repeat forever!
What's this application?
It is a DockerCoin miner! 💰🐳📦🚢
No, you can't buy coffee with DockerCoins
How DockerCoins works:
generate a few random bytes
hash these bytes
increment a counter (to keep track of speed)
repeat forever!
DockerCoins is not a cryptocurrency
(the only common points are "randomness," "hashing," and "coins" in the name)
DockerCoins in the microservices era
DockerCoins is made of 5 services:
rng= web service generating random byteshasher= web service computing hash of POSTed dataworker= background process callingrngandhasherwebui= web interface to watch progressredis= data store (holds a counter updated byworker)
These 5 services are visible in the application's Compose file, dockercoins-compose.yml
How DockerCoins works
workerinvokes web servicerngto generate random bytesworkerinvokes web servicehasherto hash these bytesworkerdoes this in an infinite loopEvery second,
workerupdatesredisto indicate how many loops were donewebuiqueriesredis, and computes and exposes "hashing speed" in our browser
(See diagram on next slide!)
Service discovery in container-land
How does each service find out the address of the other ones?
Service discovery in container-land
How does each service find out the address of the other ones?
We do not hard-code IP addresses in the code
We do not hard-code FQDNs in the code, either
We just connect to a service name, and container-magic does the rest
(And by container-magic, we mean "a crafty, dynamic, embedded DNS server")
Example in worker/worker.py
redis = Redis("redis")def get_random_bytes(): r = requests.get("http://rng/32") return r.contentdef hash_bytes(data): r = requests.post("http://hasher/", data=data, headers={"Content-Type": "application/octet-stream"})(Full source code available here)
DockerCoins at work
workerwill log HTTP requests torngandhasherrngandhasherwill log incoming HTTP requestswebuiwill give us a graph on coins mined per second
Check out the app in Docker Compose
Compose is (still) great for local development
You can test this app if you have Docker and Compose installed
If not, remember play-with-docker.com
- Download the compose file somewhere and run itcurl -o docker-compose.yml https://k8smastery.com/dockercoins-compose.ymldocker-compose up
- View the
webuionlocalhost:8000or click the8080link in PWD shared/sampleapp.md
Why does the speed seem irregular?
It looks like the speed is approximately 4 hashes/second
Or more precisely: 4 hashes/second, with regular dips down to zero
Why?
Why does the speed seem irregular?
It looks like the speed is approximately 4 hashes/second
Or more precisely: 4 hashes/second, with regular dips down to zero
Why?
The app actually has a constant, steady speed: 3.33 hashes/second
(which corresponds to 1 hash every 0.3 seconds, for reasons)Yes, and?
The reason why this graph is not awesome
The worker doesn't update the counter after every loop, but up to once per second
The speed is computed by the browser, checking the counter about once per second
Between two consecutive updates, the counter will increase either by 4, or by 0
The perceived speed will therefore be 4 - 4 - 4 - 0 - 4 - 4 - 0 etc.
What can we conclude from this?
The reason why this graph is not awesome
The worker doesn't update the counter after every loop, but up to once per second
The speed is computed by the browser, checking the counter about once per second
Between two consecutive updates, the counter will increase either by 4, or by 0
The perceived speed will therefore be 4 - 4 - 4 - 0 - 4 - 4 - 0 etc.
What can we conclude from this?
- "I'm clearly incapable of writing good frontend code!" 😀 — Jérôme
Stopping the application
If we interrupt Compose (with
^C), it will politely ask the Docker Engine to stop the appThe Docker Engine will send a
TERMsignal to the containersIf the containers do not exit in a timely manner, the Engine sends a
KILLsignal
- Stop the application by hitting
^C
Stopping the application
If we interrupt Compose (with
^C), it will politely ask the Docker Engine to stop the appThe Docker Engine will send a
TERMsignal to the containersIf the containers do not exit in a timely manner, the Engine sends a
KILLsignal
- Stop the application by hitting
^C
Some containers exit immediately, others take longer.
The containers that do not handle SIGTERM end up being killed after a 10s timeout. If we are very impatient, we can hit ^C a second time!
Clean up
Before moving on, let's remove those containers
Or if using PWD for compose, just hit "close session" button
- Tell Compose to remove everything:docker-compose down
Shipping images with a registry
(automatically generated title slide)
Shipping images with a registry
For development using Docker, it has build, ship, and run features
Now that we want to run on a cluster, things are different
Kubernetes doesn't have a build feature built-in
The way to ship (pull) images to Kubernetes is to use a registry
How Docker registries work (a reminder)
What happens when we execute
docker run alpine?If the Engine needs to pull the
alpineimage, it expands it intolibrary/alpinelibrary/alpineis expanded intoindex.docker.io/library/alpineThe Engine communicates with
index.docker.ioto retrievelibrary/alpine:latestTo use something else than
index.docker.io, we specify it in the image nameExamples:
docker pull gcr.io/google-containers/alpine-with-bash:1.0docker build -t registry.mycompany.io:5000/myimage:awesome .docker push registry.mycompany.io:5000/myimage:awesome
Building and shipping images
There are many options!
Manually:
build locally (with
docker buildor otherwise)push to the registry
Automatically:
build and test locally
when ready, commit and push a code repository
the code repository notifies an automated build system
that system gets the code, builds it, pushes the image to the registry
Which registry do we want to use?
There are SAAS products like Docker Hub, Quay, GitLab ...
Each major cloud provider has an option as well
(ACR on Azure, ECR on AWS, GCR on Google Cloud...)
Which registry do we want to use?
There are SAAS products like Docker Hub, Quay, GitLab ...
Each major cloud provider has an option as well
(ACR on Azure, ECR on AWS, GCR on Google Cloud...)
There are also commercial products to run our own registry
(Docker Enterprise DTR, Quay, GitLab, JFrog Artifactory...)
Which registry do we want to use?
There are SAAS products like Docker Hub, Quay, GitLab ...
Each major cloud provider has an option as well
(ACR on Azure, ECR on AWS, GCR on Google Cloud...)
There are also commercial products to run our own registry
(Docker Enterprise DTR, Quay, GitLab, JFrog Artifactory...)
And open source options, too!
(Quay, Portus, OpenShift OCR, GitLab, Harbor, Kraken...)
(I don't mention Docker Distribution here because it's too basic)
Which registry do we want to use?
There are SAAS products like Docker Hub, Quay, GitLab ...
Each major cloud provider has an option as well
(ACR on Azure, ECR on AWS, GCR on Google Cloud...)
There are also commercial products to run our own registry
(Docker Enterprise DTR, Quay, GitLab, JFrog Artifactory...)
And open source options, too!
(Quay, Portus, OpenShift OCR, GitLab, Harbor, Kraken...)
(I don't mention Docker Distribution here because it's too basic)
When picking a registry, pay attention to:
- Its build system
- Multi-user auth and mgmt (RBAC)
- Storage features (replication, caching, garbage collection)
Running DockerCoins on Kubernetes
Create one deployment for each component
(hasher, redis, rng, webui, worker)
Expose deployments that need to accept connections
(hasher, redis, rng, webui)
For redis, we can use the official redis image
For the 4 others, we need to build images and push them to some registry
Using images from the Docker Hub
For everyone's convenience, we took care of building DockerCoins images
We pushed these images to the DockerHub, under the dockercoins user
These images are tagged with a version number,
v0.1The full image names are therefore:
dockercoins/hasher:v0.1dockercoins/rng:v0.1dockercoins/webui:v0.1dockercoins/worker:v0.1
Running DockerCoins on Kubernetes
(automatically generated title slide)
Running DockerCoins on Kubernetes
- We can now deploy our code (as well as a redis instance)
Deploy
redis:kubectl create deployment redis --image=redisDeploy everything else:
kubectl create deployment hasher --image=dockercoins/hasher:v0.1kubectl create deployment rng --image=dockercoins/rng:v0.1kubectl create deployment webui --image=dockercoins/webui:v0.1kubectl create deployment worker --image=dockercoins/worker:v0.1
Is this working?
After waiting for the deployment to complete, let's look at the logs!
(Hint: use
kubectl get deploy -wto watch deployment events)
- Look at some logs:kubectl logs deploy/rngkubectl logs deploy/worker
Is this working?
After waiting for the deployment to complete, let's look at the logs!
(Hint: use
kubectl get deploy -wto watch deployment events)
- Look at some logs:kubectl logs deploy/rngkubectl logs deploy/worker
🤔 rng is fine ... But not worker.
Is this working?
After waiting for the deployment to complete, let's look at the logs!
(Hint: use
kubectl get deploy -wto watch deployment events)
- Look at some logs:kubectl logs deploy/rngkubectl logs deploy/worker
🤔 rng is fine ... But not worker.
💡 Oh right! We forgot to expose.
Connecting containers together
Three deployments need to be reachable by others:
hasher,redis,rngworkerdoesn't need to be exposedwebuiwill be dealt with later
- Expose each deployment, specifying the right port:kubectl expose deployment redis --port 6379kubectl expose deployment rng --port 80kubectl expose deployment hasher --port 80
Is this working yet?
- The
workerhas an infinite loop, that retries 10 seconds after an error
Stream the worker's logs:
kubectl logs deploy/worker --follow(Give it about 10 seconds to recover)
Is this working yet?
- The
workerhas an infinite loop, that retries 10 seconds after an error
Stream the worker's logs:
kubectl logs deploy/worker --follow(Give it about 10 seconds to recover)
We should now see the worker, well, working happily.
Exposing services for external access
Now we would like to access the Web UI
We will expose it with a
NodePort(just like we did for the registry)
Create a
NodePortservice for the Web UI:kubectl expose deploy/webui --type=NodePort --port=80Check the port that was allocated:
kubectl get svc
Accessing the web UI
- We can now connect to any node, on the allocated node port, to view the web UI
- Open the web UI in your browser (http://localhost:3xxxx/)
Accessing the web UI
- We can now connect to any node, on the allocated node port, to view the web UI
- Open the web UI in your browser (http://localhost:3xxxx/)
Yes, this may take a little while to update. (Narrator: it was DNS.)
Accessing the web UI
- We can now connect to any node, on the allocated node port, to view the web UI
- Open the web UI in your browser (http://localhost:3xxxx/)
Yes, this may take a little while to update. (Narrator: it was DNS.)
Alright, we're back to where we started, when we were running on a single node!
Assignment 3: deploy wordsmith
(automatically generated title slide)
Assignment 3: deploy wordsmith
Let's deploy another application called wordsmith
Wordsmith has 3 components:
a web frontend:
bretfisher/wordsmith-weba API backend:
bretfisher/wordsmith-words(NOTE: won't run on Raspberry Pi's arm/v7 yet GH Issue)a postgres database:
bretfisher/wordsmith-db
We have built images for these components, and pushed them on the Docker Hub
We want to deploy all 3 components on Kubernetes
We want to be able to connect to the web frontend with our browser
assignments/03deploywordsmith.md
Wordsmith details
Here are all the network flows in the app:
the web frontend listens on port 80
the web frontend connects to the API at the address http://words:8080
the API backend listens on port 8080
the API connects to the database with the connection string pgsql://db:5432
the database listens on port 5432
assignments/03deploywordsmith.md
Winning conditions
After deploying and connecting everything together, open the web frontend
This is what we should see:
(You will probably see a different sentence, though.)
If you see empty LEGO bricks, something's wrong ...
assignments/03deploywordsmith.md
Scaling things up
If we reload that page, we get the same sentence
And that sentence repeats the same adjective and noun anyway
Can we do better?
Yes, if we scale up the API backend!
Try to scale up the API backend and see what happens
Wondering what this app is all about?
It was a demo app showecased at DockerCon
assignments/03deploywordsmith.md
Answers
First, we need to create deployments for all three components:
kubectl create deployment db --image=bretfisher/wordsmith-dbkubectl create deployment web --image=bretfisher/wordsmith-webkubectl create deployment words --image=bretfisher/wordsmith-wordsNote: we need to use these exact names, because these names will be used for the service that we will create and their DNS entries as well. To put it differently: if our code connects to words then the service should be named words and the deployment should also be named words (unless we want to write our own service YAML manifest by hand; but we won't do that yet).
assignments/03deploywordsmith.md
Answers
Then, we need to create the services for these deployments:
kubectl expose deployment db --port=5432kubectl expose deployment web --port=80 --type=NodePortkubectl expose deployment words --port=8080or
kubectl create service clusterip db --tcp=5432kubectl create service nodeport web --tcp=80kubectl create service clusterip words --tcp=8080Find out the node port allocated to web: kubectl get service web
Open it in your browser. If you hit "reload", you always see the same sentence.
assignments/03deploywordsmith.md
Answers
Finally, scale up the API for more words on refresh:
kubectl scale deployment words --replicas=5If you hit "reload", you should now see different sentences each time.
assignments/03deploywordsmith.md
Scaling our demo app
(automatically generated title slide)
Scaling our demo app
Our ultimate goal is to get more DockerCoins
(i.e. increase the number of loops per second shown on the web UI)
Let's look at the architecture again:

Scaling our demo app
Our ultimate goal is to get more DockerCoins
(i.e. increase the number of loops per second shown on the web UI)
Let's look at the architecture again:
We're at 4 hashes a second. Let's ramp this up!
The loop is done in the worker; perhaps we could try adding more workers?
Adding another worker
- All we have to do is scale the
workerDeployment
- Open a new terminal to keep an eye on our pods:kubectl get pods -w
- Now, create more
workerreplicas:kubectl scale deployment worker --replicas=2
Adding another worker
- All we have to do is scale the
workerDeployment
- Open a new terminal to keep an eye on our pods:kubectl get pods -w
- Now, create more
workerreplicas:kubectl scale deployment worker --replicas=2
After a few seconds, the graph in the web UI should show up.
Adding more workers
- If 2 workers give us 2x speed, what about 3 workers?
- Scale the
workerDeployment further:kubectl scale deployment worker --replicas=3
Adding more workers
- If 2 workers give us 2x speed, what about 3 workers?
- Scale the
workerDeployment further:kubectl scale deployment worker --replicas=3
The graph in the web UI should go up again.
(This is looking great! We're gonna be RICH!)
Adding even more workers
- Let's see if 10 workers give us 10x speed!
- Scale the
workerDeployment to a bigger number:kubectl scale deployment worker --replicas=10
Adding even more workers
- Let's see if 10 workers give us 10x speed!
- Scale the
workerDeployment to a bigger number:kubectl scale deployment worker --replicas=10
The graph will peak at 10-12 hashes/second.
(We can add as many workers as we want: we will never go past 10-12 hashes/second.)
Didn't we briefly exceed 10 hashes/second?
It may look like it, because the web UI shows instant speed
The instant speed can briefly exceed 10 hashes/second
The average speed cannot
The instant speed can be biased because of how it's computed
Why are we stuck at 10-12 hashes per second?
If this was high-quality, production code, we would have instrumentation
(Datadog, Honeycomb, New Relic, statsd, Sumologic, ...)
It's not!
Perhaps we could benchmark our web services?
(with tools like
ab, or even simpler,httping)
Benchmarking our web services
We want to check
hasherandrngWe are going to use
httpingIt's just like
ping, but using HTTPGETrequests(it measures how long it takes to perform one
GETrequest)It's used like this:
httping [-c count] http://host:port/pathOr even simpler:
httping ip.ad.dr.essWe will use
httpingon the ClusterIP addresses of our services
Obtaining ClusterIP addresses
We can simply check the output of
kubectl get servicesOr do it programmatically, as in the example below
- Retrieve the IP addresses:HASHER=$(kubectl get svc hasher -o go-template={{.spec.clusterIP}})RNG=$(kubectl get svc rng -o go-template={{.spec.clusterIP}})
Now we can access the IP addresses of our services through $HASHER and $RNG.
Checking hasher and rng response times
Remember to use
shpodon macOS and Windows:kubectl attach --namespace=shpod -ti shpodCheck the response times for both services:
httping -c 3 $HASHERhttping -c 3 $RNG
Checking hasher and rng response times
Remember to use
shpodon macOS and Windows:kubectl attach --namespace=shpod -ti shpodCheck the response times for both services:
httping -c 3 $HASHERhttping -c 3 $RNG
hasheris fine (it should take a few milliseconds to reply)rngis not (it should take about 700 milliseconds if there are 10 workers)Something is wrong with
rng, but ... what?
Let's draw hasty conclusions
The bottleneck seems to be
rngWhat if we don't have enough entropy and can't generate enough random numbers?
We need to scale out the
rngservice on multiple machines!
Note: this is a fiction! We have enough entropy. But we need a pretext to scale out.
(In fact, the code of rng uses /dev/urandom, which never runs out of entropy...
...and is just as good as /dev/random.)
Let's draw hasty conclusions
The bottleneck seems to be
rngWhat if we don't have enough entropy and can't generate enough random numbers?
We need to scale out the
rngservice on multiple machines!
Note: this is a fiction! We have enough entropy. But we need a pretext to scale out.
(In fact, the code of rng uses /dev/urandom, which never runs out of entropy...
...and is just as good as /dev/random.)
- Oops we only have one node for learning. 🤔
Let's draw hasty conclusions
The bottleneck seems to be
rngWhat if we don't have enough entropy and can't generate enough random numbers?
We need to scale out the
rngservice on multiple machines!
Note: this is a fiction! We have enough entropy. But we need a pretext to scale out.
(In fact, the code of rng uses /dev/urandom, which never runs out of entropy...
...and is just as good as /dev/random.)
Oops we only have one node for learning. 🤔
Let's pretend and I'll explain along the way
Deploying with YAML
(automatically generated title slide)
Deploying with YAML
So far, we created resources with the following commands:
kubectl runkubectl create deploymentkubectl expose
We can also create resources directly with YAML manifests
kubectl apply vs create
kubectl create -f whatever.yamlcreates resources if they don't exist
if resources already exist, don't alter them
(and display error message)
kubectl apply -f whatever.yamlcreates resources if they don't exist
if resources already exist, update them
(to match the definition provided by the YAML file)stores the manifest as an annotation in the resource
Creating multiple resources
- The manifest can contain multiple resources separated by
---
kind: ... apiVersion: ... metadata: name: ... ... spec: ... --- kind: ... apiVersion: ... metadata: name: ... ... spec: ...Creating multiple resources
- The manifest can also contain a list of resources
apiVersion: v1 kind: List items: - kind: ... apiVersion: ... ... - kind: ... apiVersion: ... ...Deploying DockerCoins with YAML
Here's a YAML manifest with all the resources for DockerCoins
(Deployments and Services)
We can use it if we need to deploy or redeploy DockerCoins
Yes YAML file commands can use URL's!
- Deploy or redeploy DockerCoins:kubectl apply -f https://k8smastery.com/dockercoins.yaml
Apply errors for create or run resources
Note the warnings if you already had the resources created
This is because we didn't use
applybeforeThis is OK for us learning, so ignore the warnings
Generally in production you want to stick with one method or the other
Deleting resources
We can also use a YAML file to delete resources
kubectl delete -f ...will delete all the resources mentioned in a YAML file(useful to clean up everything that was created by
kubectl apply -f ...)The definitions of the resources don't matter
(just their
kind,apiVersion, andname)
Pruning¹ resources
We can also tell
kubectlto remove old resourcesThis is done with
kubectl apply -f ... --pruneIt will remove resources that don't exist in the YAML file(s)
But only if they were created with
kubectl applyin the first place(technically, if they have an annotation
kubectl.kubernetes.io/last-applied-configuration)
¹If English is not your first language: to prune means to remove dead or overgrown branches in a tree, to help it to grow.
YAML as source of truth
Imagine the following workflow:
do not use
kubectl run,kubectl create deployment,kubectl expose...define everything with YAML
kubectl apply -f ... --prune --allthat YAMLkeep that YAML under version control
enforce all changes to go through that YAML (e.g. with pull requests)
Our version control system now has a full history of what we deploy
Compares to "Infrastructure-as-Code", but for app deployments
Specifying the namespace
When creating resources from YAML manifests, the namespace is optional
If we specify a namespace:
resources are created in the specified namespace
this is typical for things deployed only once per cluster
example: system components, cluster add-ons ...
If we don't specify a namespace:
resources are created in the current namespace
this is typical for things that may be deployed multiple times
example: applications (production, staging, feature branches ...)
The Kubernetes Dashboard
(automatically generated title slide)
The Kubernetes Dashboard
Kubernetes resources can also be viewed with an official web UI
That dashboard is usually exposed over HTTPS
(this requires obtaining a proper TLS certificate)
Dashboard users need to authenticate
We are going to take a dangerous shortcut
The insecure method
We could (and should) use Let's Encrypt ...
... but we don't want to deal with TLS certificates
We could (and should) learn how authentication and authorization work ...
... but we will use a guest account with admin access instead
Yes, this will open our cluster to all kinds of shenanigans. Don't do this at home.
Running a very insecure dashboard
We are going to deploy that dashboard with one single command
This command will create all the necessary resources
(the dashboard itself, the HTTP wrapper, the admin/guest account)
All these resources are defined in a YAML file
All we have to do is load that YAML file with with
kubectl apply -f
- Create all the dashboard resources, with the following command:kubectl apply -f https://k8smastery.com/insecure-dashboard.yaml
Connecting to the dashboard
- Check which port the dashboard is on:kubectl get svc dashboard
You'll want the 3xxxx port.
- Connect to http://localhost:3xxxx/
The dashboard will then ask you which authentication you want to use.
Dashboard authentication
We have three authentication options at this point:
token (associated with a role that has appropriate permissions)
kubeconfig (e.g. using the
~/.kube/configfile)"skip" (use the dashboard "service account")
Let's use "skip": we're logged in!
Dashboard authentication
We have three authentication options at this point:
token (associated with a role that has appropriate permissions)
kubeconfig (e.g. using the
~/.kube/configfile)"skip" (use the dashboard "service account")
Let's use "skip": we're logged in!
By the way, we just added a backdoor to our Kubernetes cluster!
Running the Kubernetes Dashboard securely
The steps that we just showed you are for educational purposes only!
If you do that on your production cluster, people can and will abuse it
For an in-depth discussion about securing the dashboard,
check this excellent post on Heptio's blog
Running the Kubernetes Dashboard securely
The steps that we just showed you are for educational purposes only!
If you do that on your production cluster, people can and will abuse it
For an in-depth discussion about securing the dashboard,
check this excellent post on Heptio's blogMinikube/microK8s can be enabled with easy commands
minikube dashboardandmicrok8s enable dashboardk8s/dashboard.md
Other dashboards
-
read-only dashboard
optimized for "troubleshooting and incident response"
see vision and goals for details
-
- "provides a common operational picture for multiple Kubernetes clusters"
Other dashboards
-
read-only dashboard
optimized for "troubleshooting and incident response"
see vision and goals for details
-
- "provides a common operational picture for multiple Kubernetes clusters"
Your Kubernetes distro comes with one!
Other dashboards
-
read-only dashboard
optimized for "troubleshooting and incident response"
see vision and goals for details
-
- "provides a common operational picture for multiple Kubernetes clusters"
Your Kubernetes distro comes with one!
Cloud-provided control-planes often don't come with one
Security implications of kubectl apply
(automatically generated title slide)
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...- starts bitcoin miners on the whole cluster
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...starts bitcoin miners on the whole cluster
hides in a non-default namespace
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...starts bitcoin miners on the whole cluster
hides in a non-default namespace
bind-mounts our nodes' filesystem
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...starts bitcoin miners on the whole cluster
hides in a non-default namespace
bind-mounts our nodes' filesystem
inserts SSH keys in the root account (on the node)
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...starts bitcoin miners on the whole cluster
hides in a non-default namespace
bind-mounts our nodes' filesystem
inserts SSH keys in the root account (on the node)
encrypts our data and ransoms it
Security implications of kubectl apply
When we do
kubectl apply -f <URL>, we create arbitrary resourcesResources can be evil; imagine a
deploymentthat ...starts bitcoin miners on the whole cluster
hides in a non-default namespace
bind-mounts our nodes' filesystem
inserts SSH keys in the root account (on the node)
encrypts our data and ransoms it
☠️☠️☠️
kubectl apply is the new curl | sh
curl | shis convenientIt's safe if you use HTTPS URLs from trusted sources
kubectl apply is the new curl | sh
curl | shis convenientIt's safe if you use HTTPS URLs from trusted sources
kubectl apply -fis convenientIt's safe if you use HTTPS URLs from trusted sources
Example: the official setup instructions for most pod networks
kubectl apply is the new curl | sh
curl | shis convenientIt's safe if you use HTTPS URLs from trusted sources
kubectl apply -fis convenientIt's safe if you use HTTPS URLs from trusted sources
Example: the official setup instructions for most pod networks
It introduces new failure modes
(for instance, if you try to apply YAML from a link that's no longer valid)
Daemon sets
(automatically generated title slide)
Daemon sets
We want to scale
rngin a way that is different from how we scaledworkerWe want one (and exactly one) instance of
rngper nodeWe do not want two instances of
rngon the same nodeWe will do that with a daemon set
Why not a deployment?
- Can't we just do
kubectl scale deployment rng --replicas=...?
Why not a deployment?
Can't we just do
kubectl scale deployment rng --replicas=...?Nothing guarantees that the
rngcontainers will be distributed evenly
Why not a deployment?
Can't we just do
kubectl scale deployment rng --replicas=...?Nothing guarantees that the
rngcontainers will be distributed evenlyIf we add nodes later, they will not automatically run a copy of
rng
Why not a deployment?
Can't we just do
kubectl scale deployment rng --replicas=...?Nothing guarantees that the
rngcontainers will be distributed evenlyIf we add nodes later, they will not automatically run a copy of
rngIf we remove (or reboot) a node, one
rngcontainer will restart elsewhere(and we will end up with two instances
rngon the same node)
Why not a deployment?
Can't we just do
kubectl scale deployment rng --replicas=...?Nothing guarantees that the
rngcontainers will be distributed evenlyIf we add nodes later, they will not automatically run a copy of
rngIf we remove (or reboot) a node, one
rngcontainer will restart elsewhere(and we will end up with two instances
rngon the same node)By contrast, a daemon set will start one pod per node and keep it that way
(as nodes are added or removed)
Daemon sets in practice
Daemon sets are great for cluster-wide, per-node processes:
kube-proxyCNI network plugins
monitoring agents
hardware management tools (e.g. SCSI/FC HBA agents)
etc.
They can also be restricted to run only on some nodes
Creating a daemon set
- Unfortunately, as of Kubernetes 1.17, the CLI cannot create daemon sets
Creating a daemon set
Unfortunately, as of Kubernetes 1.17, the CLI cannot create daemon sets
More precisely: it doesn't have a subcommand to create a daemon set
Creating a daemon set
Unfortunately, as of Kubernetes 1.17, the CLI cannot create daemon sets
More precisely: it doesn't have a subcommand to create a daemon set
But any kind of resource can always be created by providing a YAML description:
kubectl apply -f foo.yaml
Creating a daemon set
Unfortunately, as of Kubernetes 1.17, the CLI cannot create daemon sets
More precisely: it doesn't have a subcommand to create a daemon set
But any kind of resource can always be created by providing a YAML description:
kubectl apply -f foo.yaml
- How do we create the YAML file for our daemon set?
Creating a daemon set
Unfortunately, as of Kubernetes 1.17, the CLI cannot create daemon sets
More precisely: it doesn't have a subcommand to create a daemon set
But any kind of resource can always be created by providing a YAML description:
kubectl apply -f foo.yaml
How do we create the YAML file for our daemon set?
- option 1: read the docs
Creating a daemon set
Unfortunately, as of Kubernetes 1.17, the CLI cannot create daemon sets
More precisely: it doesn't have a subcommand to create a daemon set
But any kind of resource can always be created by providing a YAML description:
kubectl apply -f foo.yaml
How do we create the YAML file for our daemon set?
option 1: read the docs
option 2:
viour way out of it
Creating the YAML file for our daemon set
- Let's start with the YAML file for the current
rngresource
Dump the
rngresource in YAML:kubectl get deploy/rng -o yaml >rng.ymlEdit
rng.yml
"Casting" a resource to another
What if we just changed the
kindfield?(It can't be that easy, right?)
- Change
kind: Deploymenttokind: DaemonSet
Save, quit
Try to create our new resource:
kubectl apply -f rng.yml
"Casting" a resource to another
What if we just changed the
kindfield?(It can't be that easy, right?)
- Change
kind: Deploymenttokind: DaemonSet
Save, quit
Try to create our new resource:
kubectl apply -f rng.yml
We all knew this couldn't be that easy, right!
Understanding the problem
- The core of the error is:error validating data:[ValidationError(DaemonSet.spec):unknown field "replicas" in io.k8s.api.extensions.v1beta1.DaemonSetSpec,...
Understanding the problem
- The core of the error is:error validating data:[ValidationError(DaemonSet.spec):unknown field "replicas" in io.k8s.api.extensions.v1beta1.DaemonSetSpec,...
- Obviously, it doesn't make sense to specify a number of replicas for a daemon set
Understanding the problem
- The core of the error is:error validating data:[ValidationError(DaemonSet.spec):unknown field "replicas" in io.k8s.api.extensions.v1beta1.DaemonSetSpec,...
Obviously, it doesn't make sense to specify a number of replicas for a daemon set
Workaround: fix the YAML
- remove the
replicasfield - remove the
strategyfield (which defines the rollout mechanism for a deployment) - remove the
progressDeadlineSecondsfield (also used by the rollout mechanism) - remove the
status: {}line at the end
- remove the
Understanding the problem
- The core of the error is:error validating data:[ValidationError(DaemonSet.spec):unknown field "replicas" in io.k8s.api.extensions.v1beta1.DaemonSetSpec,...
Obviously, it doesn't make sense to specify a number of replicas for a daemon set
Workaround: fix the YAML
- remove the
replicasfield - remove the
strategyfield (which defines the rollout mechanism for a deployment) - remove the
progressDeadlineSecondsfield (also used by the rollout mechanism) - remove the
status: {}line at the end
- remove the
Or, we could also ...
Use the --force, Luke
We could also tell Kubernetes to ignore these errors and try anyway
The
--forceflag's actual name is--validate=false
- Try to load our YAML file and ignore errors:kubectl apply -f rng.yml --validate=false
Use the --force, Luke
We could also tell Kubernetes to ignore these errors and try anyway
The
--forceflag's actual name is--validate=false
- Try to load our YAML file and ignore errors:kubectl apply -f rng.yml --validate=false
🎩✨🐇
Use the --force, Luke
We could also tell Kubernetes to ignore these errors and try anyway
The
--forceflag's actual name is--validate=false
- Try to load our YAML file and ignore errors:kubectl apply -f rng.yml --validate=false
🎩✨🐇
Wait ... Now, can it be that easy?
Checking what we've done
- Did we transform our
deploymentinto adaemonset?
- Look at the resources that we have now:kubectl get all
Checking what we've done
- Did we transform our
deploymentinto adaemonset?
- Look at the resources that we have now:kubectl get all
We have two resources called rng:
the deployment that was existing before
the daemon set that we just created
We also have one too many pods.
(The pod corresponding to the deployment still exists.)
deploy/rng and ds/rng
You can have different resource types with the same name
(i.e. a deployment and a daemon set both named
rng)We still have the old
rngdeploymentNAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGEdeployment.apps/rng 1 1 1 1 18mBut now we have the new
rngdaemon set as wellNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGEdaemonset.apps/rng 2 2 2 2 2 <none> 9s
Too many pods
If we check with
kubectl get pods, we see:one pod for the deployment (named
rng-xxxxxxxxxx-yyyyy)one pod per node for the daemon set (named
rng-zzzzz)
NAME READY STATUS RESTARTS AGErng-54f57d4d49-7pt82 1/1 Running 0 11mrng-b85tm 1/1 Running 0 25srng-hfbrr 1/1 Running 0 25s[...]
Too many pods
If we check with
kubectl get pods, we see:one pod for the deployment (named
rng-xxxxxxxxxx-yyyyy)one pod per node for the daemon set (named
rng-zzzzz)
NAME READY STATUS RESTARTS AGErng-54f57d4d49-7pt82 1/1 Running 0 11mrng-b85tm 1/1 Running 0 25srng-hfbrr 1/1 Running 0 25s[...]
The daemon set created one pod per node.
In a multi-node setup, masters usually have taints preventing pods from running there.
(To schedule a pod on this node anyway, the pod will require appropriate tolerations.)
Is this working?
- Look at the web UI
Is this working?
Look at the web UI
The graph should now go above 10 hashes per second!
Is this working?
Look at the web UI
The graph should now go above 10 hashes per second!
It looks like the newly created pods are serving traffic correctly
How and why did this happen?
(We didn't do anything special to add them to the
rngservice load balancer!)
Labels and selectors
(automatically generated title slide)
Labels and selectors
The
rngservice is load balancing requests to a set of podsThat set of pods is defined by the selector of the
rngservice
- Check the selector in the
rngservice definition:kubectl describe service rng
The selector is
app=rngIt means "all the pods having the label
app=rng"(They can have additional labels as well, that's OK!)
Selector evaluation
We can use selectors with many
kubectlcommandsFor instance, with
kubectl get,kubectl logs,kubectl delete... and more
- Get the list of pods matching selector
app=rng:kubectl get pods -l app=rngkubectl get pods --selector app=rng
But ... why do these pods (in particular, the new ones) have this app=rng label?
Where do labels come from?
When we create a deployment with
kubectl create deployment rng,
this deployment gets the labelapp=rngThe replica sets created by this deployment also get the label
app=rngThe pods created by these replica sets also get the label
app=rngWhen we created the daemon set from the deployment, we re-used the same spec
Therefore, the pods created by the daemon set get the same labels
When we use
kubectl run stuff, the label isrun=stuffinstead
Updating load balancer configuration
We would like to remove a pod from the load balancer
What would happen if we removed that pod, with
kubectl delete pod ...?
Updating load balancer configuration
We would like to remove a pod from the load balancer
What would happen if we removed that pod, with
kubectl delete pod ...?It would be re-created immediately (by the replica set or the daemon set)
Updating load balancer configuration
We would like to remove a pod from the load balancer
What would happen if we removed that pod, with
kubectl delete pod ...?It would be re-created immediately (by the replica set or the daemon set)
What would happen if we removed the
app=rnglabel from that pod?
Updating load balancer configuration
We would like to remove a pod from the load balancer
What would happen if we removed that pod, with
kubectl delete pod ...?It would be re-created immediately (by the replica set or the daemon set)
What would happen if we removed the
app=rnglabel from that pod?It would also be re-created immediately
Updating load balancer configuration
We would like to remove a pod from the load balancer
What would happen if we removed that pod, with
kubectl delete pod ...?It would be re-created immediately (by the replica set or the daemon set)
What would happen if we removed the
app=rnglabel from that pod?It would also be re-created immediately
Why?!?
Selectors for replica sets and daemon sets
The "mission" of a replica set is:
"Make sure that there is the right number of pods matching this spec!"
The "mission" of a daemon set is:
"Make sure that there is a pod matching this spec on each node!"
Selectors for replica sets and daemon sets
The "mission" of a replica set is:
"Make sure that there is the right number of pods matching this spec!"
The "mission" of a daemon set is:
"Make sure that there is a pod matching this spec on each node!"
In fact, replica sets and daemon sets do not check pod specifications
They merely have a selector, and they look for pods matching that selector
Yes, we can fool them by manually creating pods with the "right" labels
Bottom line: if we remove our
app=rnglabel ...... The pod "disappears" for its parent, which re-creates another pod to replace it
Isolation of replica sets and daemon sets
Since both the
rngdaemon set and therngreplica set useapp=rng...... Why don't they "find" each other's pods?
Isolation of replica sets and daemon sets
Since both the
rngdaemon set and therngreplica set useapp=rng...... Why don't they "find" each other's pods?
Replica sets have a more specific selector, visible with
kubectl describe(It looks like
app=rng,pod-template-hash=abcd1234)Daemon sets also have a more specific selector, but it's invisible
(It looks like
app=rng,controller-revision-hash=abcd1234)As a result, each controller only "sees" the pods it manages
Removing a pod from the load balancer
Currently, the
rngservice is defined by theapp=rngselectorThe only way to remove a pod is to remove or change the
applabel... But that will cause another pod to be created instead!
What's the solution?
Removing a pod from the load balancer
Currently, the
rngservice is defined by theapp=rngselectorThe only way to remove a pod is to remove or change the
applabel... But that will cause another pod to be created instead!
What's the solution?
We need to change the selector of the
rngservice!Let's add another label to that selector (e.g.
active=yes)
Complex selectors
If a selector specifies multiple labels, they are understood as a logical AND
(In other words: the pods must match all the labels)
Kubernetes has support for advanced, set-based selectors
(But these cannot be used with services, at least not yet!)
The plan
Add the label
active=yesto all ourrngpodsUpdate the selector for the
rngservice to also includeactive=yesToggle traffic to a pod by manually adding/removing the
activelabelProfit!
Note: if we swap steps 1 and 2, it will cause a short service disruption, because there will be a period of time during which the service selector won't match any pod. During that time, requests to the service will time out. By doing things in the order above, we guarantee that there won't be any interruption.
Adding labels to pods
We want to add the label
active=yesto all pods that haveapp=rngWe could edit each pod one by one with
kubectl edit...... Or we could use
kubectl labelto label them allkubectl labelcan use selectors itself
- Add
active=yesto all pods that haveapp=rng:kubectl label pods -l app=rng active=yes
Updating the service selector
We need to edit the service specification
Reminder: in the service definition, we will see
app: rngin two placesthe label of the service itself (we don't need to touch that one)
the selector of the service (that's the one we want to change)
- Update the service to add
active: yesto its selector:kubectl edit service rng
Updating the service selector
We need to edit the service specification
Reminder: in the service definition, we will see
app: rngin two placesthe label of the service itself (we don't need to touch that one)
the selector of the service (that's the one we want to change)
- Update the service to add
active: yesto its selector:kubectl edit service rng
... And then we get the weirdest error ever. Why?
When the YAML parser is being too smart
YAML parsers try to help us:
xyzis the string"xyz"42is the integer42yesis the boolean valuetrue
If we want the string
"42"or the string"yes", we have to quote themSo we have to use
active: "yes"
For a good laugh: if we had used "ja", "oui", "si" ... as the value, it would have worked!
Updating the service selector, take 2
Update the YAML manifest of the service
Add
active: "yes"to its selector
This time it should work!
If we did everything correctly, the web UI shouldn't show any change.
Updating labels
We want to disable the pod that was created by the deployment
All we have to do, is remove the
activelabel from that podTo identify that pod, we can use its name
... Or rely on the fact that it's the only one with a
pod-template-hashlabelGood to know:
kubectl label ... foo=doesn't remove a label (it sets it to an empty string)to remove label
foo, usekubectl label ... foo-to change an existing label, we would need to add
--overwrite
Removing a pod from the load balancer
- In one window, check the logs of that pod:
- In another window, remove the label from the pod:
There might be a slight change in the web UI (since we removed a bit
of capacity from the rng service). If we remove more pods,
the effect should be more visible.
Updating the daemon set
If we scale up our cluster by adding new nodes, the daemon set will create more pods
These pods won't have the
active=yeslabelIf we want these pods to have that label, we need to edit the daemon set spec
We can do that with e.g.
kubectl edit daemonset rng
We've put resources in your resources
Reminder: a daemon set is a resource that creates more resources!
There is a difference between:
the label(s) of a resource (in the
metadatablock in the beginning)the selector of a resource (in the
specblock)the label(s) of the resource(s) created by the first resource (in the
templateblock)
We would need to update the selector and the template
(metadata labels are not mandatory)
The template must match the selector
(i.e. the resource will refuse to create resources that it will not select)
Labels and debugging
When a pod is misbehaving, we can delete it: another one will be recreated
But we can also change its labels
It will be removed from the load balancer (it won't receive traffic anymore)
Another pod will be recreated immediately
But the problematic pod is still here, and we can inspect and debug it
We can even re-add it to the rotation if necessary
(Very useful to troubleshoot intermittent and elusive bugs)
Labels and advanced rollout control
Conversely, we can add pods matching a service's selector
These pods will then receive requests and serve traffic
Examples:
one-shot pod with all debug flags enabled, to collect logs
pods created automatically, but added to rotation in a second step
(by setting their label accordingly)
This gives us building blocks for canary and blue/green deployments
Cleanup
Let's cleanup before we start the next lecture!
- remove our DockerCoin resources (for now):kubectl delete -f https://k8smastery.com/dockercoins.yamlkubectl delete daemonset/rng
k8smastery/cleanup-dockercoins-daemonset.md
Assignment 4: custom load balancing
(automatically generated title slide)
Assignment 4: custom load balancing
Our goal here will be to create a service that load balances connections to two different deployments. You might use this as a simplistic way to run two versions of your apps in parallel.
In the real world, you'll likely use a 3rd party load balancer to provide advanced blue/green or canary-style deployments, but this assignment will help further your understanding of how service selectors are used to find pods to use as service endpoints.
For simplicity, version 1 of our application will be using the NGINX image, and version 2 of our application will be using the Apache image. They both listen on port 80 by default.
When we connect to the service, we expect to see some requests being served by NGINX, and some requests being served by Apache.
Hints
We need to create two deployments: one for v1 (NGINX), another for v2 (Apache).
Hints
We need to create two deployments: one for v1 (NGINX), another for v2 (Apache).
They will be exposed through a single service.
Hints
We need to create two deployments: one for v1 (NGINX), another for v2 (Apache).
They will be exposed through a single service.
The selector of that service will need to match the pods created by both deployments.
Hints
We need to create two deployments: one for v1 (NGINX), another for v2 (Apache).
They will be exposed through a single service.
The selector of that service will need to match the pods created by both deployments.
For that, we will need to change the deployment specification to add an extra label, to be used solely by the service.
Hints
We need to create two deployments: one for v1 (NGINX), another for v2 (Apache).
They will be exposed through a single service.
The selector of that service will need to match the pods created by both deployments.
For that, we will need to change the deployment specification to add an extra label, to be used solely by the service.
That label should be different from the pre-existing labels of our deployments, otherwise our deployments will step on each other's toes.
Hints
We need to create two deployments: one for v1 (NGINX), another for v2 (Apache).
They will be exposed through a single service.
The selector of that service will need to match the pods created by both deployments.
For that, we will need to change the deployment specification to add an extra label, to be used solely by the service.
That label should be different from the pre-existing labels of our deployments, otherwise our deployments will step on each other's toes.
We're not at the point of writing our own YAML from scratch, so you'll
need to use the kubectl edit command to modify existing resources.
Deploying version 1
1.1. Create a deployment running one pod using the official NGINX image.
1.2. Expose that deployment.
1.3. Check that you can successfully connect to the exposed service.
Setting up the service
2.1. Use a custom label/value to be used by the service. How about myapp: web.
2.2. Change (edit) the service definition to use that label/value.
2.3. Check that you cannot connect to the exposed service anymore.
2.4. Change (edit) the deployment definition to add that label/value to the pods.
2.5. Check that you can connect to the exposed service again.
Deploying version 2
3.1. Create a deployment running one pod using the official Apache image.
3.2. Change (edit) the deployment definition to add the label/value picked previously.
3.3. Connect to the exposed service again.
(It should now yield responses from both Apache and NGINX.)
Answers
1.1. kubectl create deployment v1-nginx --image=nginx
1.2. kubectl expose deployment v1-nginx --port=80 or kubectl create service v1-nginx --tcp=80
1.3.A If you are using shpod, or if you are running directly on the cluster:
### Obtain the ClusterIP that was allocated to the servicekubectl get svc v1-nginxcurl http://A.B.C.D1.3.B You can also run a program like curl in a container:
kubectl run --restart=Never --image=alpine -ti --rm testcontainer### Then, once you get a prompt, install curlapk add curl### Then, connect to the servicecurl v1-nginxAnswers
2.1. Edit the YAML manifest of the service with kubectl edit service v1-nginx. Look for the selector: section, and change app: v1-nginx to myapp: web. Make sure to change the selector: section, not the labels: section! After making the change, save and quit.
2.2. The curl command (see previous slide) should now time out.
2.3. Edit the YAML manifest of the deployment with kubectl edit deployment v1-nginx. Look for the labels: section within the template: section, as we want to change the labels of the pods created by the deployment, not of the deployment itself. Make sure to change the labels: section, not the matchLabels: one. Add myapp: web just below app: v1-nginx, with the same indentation level. After making the change, save and quit. We need both labels here, unlike the service selector. The app label keeps the pod "linked" to the deployment/replicaset, and the new one will cause the service to match to this pod.
2.4. The curl command should now work again. (It might need a minute, since changing the label will trigger a rolling update and create a new pod.)
Answers
3.1. kubectl create deployment v2-apache --image=httpd
3.2. Same as previously: kubectl edit deployment v2-apache, then add the label myapp: web below app: v2-apache. Again, make sure to change the labels in the pod template, not of the deployment itself.
3.3. The curl command show now yield responses from NGINX and Apache.
(Note: you won't see a perfect round-robin, i.e. NGINX/Apache/NGINX/Apache etc., but on average, Apache and NGINX should serve approximately 50% of the requests each.)
Authoring YAML
(automatically generated title slide)
Authoring YAML
To use Kubernetes is to "live in YAML"!
It's more important to learn the foundations then to memorize all YAML keys (hundreds+)
Authoring YAML
To use Kubernetes is to "live in YAML"!
It's more important to learn the foundations then to memorize all YAML keys (hundreds+)
There are various ways to generate YAML with Kubernetes, e.g.:
kubectl runkubectl create deployment(and a few otherkubectl createvariants)kubectl expose
Authoring YAML
To use Kubernetes is to "live in YAML"!
It's more important to learn the foundations then to memorize all YAML keys (hundreds+)
There are various ways to generate YAML with Kubernetes, e.g.:
kubectl runkubectl create deployment(and a few otherkubectl createvariants)kubectl expose
These commands use "generators" because the API only accepts YAML (actually JSON)
Authoring YAML
To use Kubernetes is to "live in YAML"!
It's more important to learn the foundations then to memorize all YAML keys (hundreds+)
There are various ways to generate YAML with Kubernetes, e.g.:
kubectl runkubectl create deployment(and a few otherkubectl createvariants)kubectl expose
These commands use "generators" because the API only accepts YAML (actually JSON)
Pro: They are easy to use
Con: They have limits
Authoring YAML
To use Kubernetes is to "live in YAML"!
It's more important to learn the foundations then to memorize all YAML keys (hundreds+)
There are various ways to generate YAML with Kubernetes, e.g.:
kubectl runkubectl create deployment(and a few otherkubectl createvariants)kubectl expose
These commands use "generators" because the API only accepts YAML (actually JSON)
Pro: They are easy to use
Con: They have limits
When and why do we need to write our own YAML?
How do we write YAML from scratch?
And maybe, what is YAML?
YAML Basics (just in case you need a refresher)
It's technically a superset of JSON, designed for humans
JSON was good for machines, but not for humans
Spaces set the structure. One space off and game over
Remember spaces not tabs, Ever!
Two spaces is standard, but four spaces works too
You don't have to learn all YAML features, but key concepts you need:
- Key/Value Pairs
- Array/Lists
- Dictionary/Maps
Good online tutorials exist here, here, here, and YouTube here
Basic parts of any Kubernetes resource manifest
- Can be in YAML or JSON, but YAML is 💯
Basic parts of any Kubernetes resource manifest
Can be in YAML or JSON, but YAML is 💯
Each file contains one or more manifests
Basic parts of any Kubernetes resource manifest
Can be in YAML or JSON, but YAML is 💯
Each file contains one or more manifests
Each manifest describes an API object (deployment, service, etc.)
Basic parts of any Kubernetes resource manifest
Can be in YAML or JSON, but YAML is 💯
Each file contains one or more manifests
Each manifest describes an API object (deployment, service, etc.)
Each manifest needs four parts (root key:values in the file)
apiVersion:kind:metadata:spec:A simple Pod in YAML
- This is a single manifest that creates one Pod
apiVersion: v1 kind: Pod metadata: name: nginxspec: containers: - name: nginx image: nginx:1.17.3Deployment and Service manifests in one YAML file
apiVersion: v1 kind: Service metadata: name: mynginx spec: type: NodePort ports: - port: 80 selector: app: mynginx --- apiVersion: apps/v1 kind: Deployment metadata: name: mynginx spec: replicas: 3 selector: matchLabels: app: mynginx template: metadata: labels: app: mynginx spec: containers: - name: nginx image: nginx:1.17.3The limits of generated YAML
Advanced (and even not-so-advanced) features require us to write YAML:
pods with multiple containers
resource limits
healthchecks
many other resource options
The limits of generated YAML
Advanced (and even not-so-advanced) features require us to write YAML:
pods with multiple containers
resource limits
healthchecks
many other resource options
Other resource types don't have their own commands!
DaemonSets
StatefulSets
and more!
How do we access these features?
We don't have to start from scratch
Output YAML from existing resources
Create a resource (e.g. Deployment)
Dump its YAML with
kubectl get -o yaml ...Edit the YAML
Use
kubectl apply -f ...with the YAML file to:update the resource (if it's the same kind)
create a new resource (if it's a different kind)
We don't have to start from scratch
Output YAML from existing resources
Create a resource (e.g. Deployment)
Dump its YAML with
kubectl get -o yaml ...Edit the YAML
Use
kubectl apply -f ...with the YAML file to:update the resource (if it's the same kind)
create a new resource (if it's a different kind)
Or... we have the docs, with good starter YAML
We don't have to start from scratch
Output YAML from existing resources
Create a resource (e.g. Deployment)
Dump its YAML with
kubectl get -o yaml ...Edit the YAML
Use
kubectl apply -f ...with the YAML file to:update the resource (if it's the same kind)
create a new resource (if it's a different kind)
Or... we have the docs, with good starter YAML
Or... we can use
-o yaml --dry-run
Generating YAML without creating resources
- We can use the
-o yaml --dry-runoption combo withrunandcreate
Generate the YAML for a Deployment without creating it:
kubectl create deployment web --image nginx -o yaml --dry-runGenerate the YAML for a Namespace without creating it:
kubectl create namespace awesome-app -o yaml --dry-run
We can clean up the YAML even more if we want
(for instance, we can remove the
creationTimestampand empty dicts)
Try -o yaml --dry-run with other create commands
clusterrole # Create a ClusterRole. clusterrolebinding # Create a ClusterRoleBinding for a particular ClusterRole. configmap # Create a configmap from a local file, directory or literal. cronjob # Create a cronjob with the specified name. deployment # Create a deployment with the specified name. job # Create a job with the specified name. namespace # Create a namespace with the specified name. poddisruptionbudget # Create a pod disruption budget with the specified name. priorityclass # Create a priorityclass with the specified name. quota # Create a quota with the specified name. role # Create a role with single rule. rolebinding # Create a RoleBinding for a particular Role or ClusterRole. secret # Create a secret using specified subcommand. service # Create a service using specified subcommand. serviceaccount # Create a service account with the specified name.- Ensure you use valid
createcommands with required options for each
Writing YAML from scratch, "YAML The Hard Way"
- Paying homage to Kelsey Hightower's "Kubernetes The Hard Way"
Writing YAML from scratch, "YAML The Hard Way"
Paying homage to Kelsey Hightower's "Kubernetes The Hard Way"
A reminder about manifests:
Each file contains one or more manifests
Each manifest describes an API object (deployment, service, etc.)
Each manifest needs four parts (root key:values in the file)
apiVersion: # find with "kubectl api-versions" kind: # find with "kubectl api-resources" metadata: spec: # find with "kubectl describe pod"Writing YAML from scratch, "YAML The Hard Way"
Paying homage to Kelsey Hightower's "Kubernetes The Hard Way"
A reminder about manifests:
Each file contains one or more manifests
Each manifest describes an API object (deployment, service, etc.)
Each manifest needs four parts (root key:values in the file)
apiVersion: # find with "kubectl api-versions" kind: # find with "kubectl api-resources" metadata: spec: # find with "kubectl describe pod"- Those three
kubectlcommands, plus the API docs, is all we'll need
General workflow of YAML from scratch
- Find the resource
kindyou want to create (api-resources)
General workflow of YAML from scratch
Find the resource
kindyou want to create (api-resources)Find the latest
apiVersionyour cluster supports forkind(api-versions)
General workflow of YAML from scratch
Find the resource
kindyou want to create (api-resources)Find the latest
apiVersionyour cluster supports forkind(api-versions)Give it a
namein metadata (minimum)
General workflow of YAML from scratch
Find the resource
kindyou want to create (api-resources)Find the latest
apiVersionyour cluster supports forkind(api-versions)Give it a
namein metadata (minimum)Dive into the
specof thatkindkubectl explain <kind>.speckubectl explain <kind> --recursive
General workflow of YAML from scratch
Find the resource
kindyou want to create (api-resources)Find the latest
apiVersionyour cluster supports forkind(api-versions)Give it a
namein metadata (minimum)Dive into the
specof thatkindkubectl explain <kind>.speckubectl explain <kind> --recursive
Browse the docs API Reference for your cluster version to supplement
General workflow of YAML from scratch
Find the resource
kindyou want to create (api-resources)Find the latest
apiVersionyour cluster supports forkind(api-versions)Give it a
namein metadata (minimum)Dive into the
specof thatkindkubectl explain <kind>.speckubectl explain <kind> --recursive
Browse the docs API Reference for your cluster version to supplement
Use
--dry-runand--server-dry-runfor testingkubectl createanddeleteuntil you get it right k8smastery/authoringyaml.md
Advantage of YAML
Using YAML (instead of
kubectl run/create/etc.) allows to be declarativeThe YAML describes the desired state of our cluster and applications
YAML can be stored, versioned, archived (e.g. in git repositories)
To change resources, change the YAML files
(instead of using
kubectl edit/scale/label/etc.)Changes can be reviewed before being applied
(with code reviews, pull requests ...)
This workflow is sometimes called "GitOps"
(there are tools like Weave Flux or GitKube to facilitate it)
YAML in practice
Get started with
kubectl run/create/expose/etc.Dump the YAML with
kubectl get -o yamlTweak that YAML and
kubectl applyit backStore that YAML for reference (for further deployments)
Feel free to clean up the YAML:
remove fields you don't know
check that it still works!
That YAML will be useful later when using e.g. Kustomize or Helm
YAML linting and validation
Use generic linters to check proper YAML formatting
For humans without kubectl, use a web Kubernetes YAML validator: kubeyaml.com
In CI, you might use CLI tools
- YAML linter:
pip install yamllintgithub.com/adrienverge/yamllint - Kuberentes validator:
kubevalgithub.com/instrumenta/kubeval
- YAML linter:
We'll learn about Kubernetes cluster-specific validation with kubectl later
Using server-dry-run and diff
(automatically generated title slide)
Using server-dry-run and diff
We already talked about using
--dry-runfor building YAMLLet's talk more about options for testing YAML
Including testing against the live cluster API!
Using --dry-run with kubectl apply
The
--dry-runoption can also be used withkubectl applyHowever, it can be misleading (it doesn't do a "real" dry run)
Let's see what happens in the following scenario:
generate the YAML for a Deployment
tweak the YAML to transform it into a DaemonSet
apply that YAML to see what would actually be created
The limits of kubectl apply --dry-run
Generate the YAML for a deployment:
kubectl create deployment web --image=nginx -o yaml > web.yamlChange the
kindin the YAML to make it aDaemonSetAsk
kubectlwhat would be applied:kubectl apply -f web.yaml --dry-run --validate=false -o yaml
The resulting YAML doesn't represent a valid DaemonSet.
Server-side dry run
Since Kubernetes 1.13, we can use server-side dry run and diffs
Server-side dry run will do all the work, but not persist to etcd
(all validation and mutation hooks will be executed)
- Try the same YAML file as earlier, with server-side dry run:kubectl apply -f web.yaml --server-dry-run --validate=false -o yaml
The resulting YAML doesn't have the replicas field anymore.
Instead, it has the fields expected in a DaemonSet.
Advantages of server-side dry run
The YAML is verified much more extensively
The only step that is skipped is "write to etcd"
YAML that passes server-side dry run should apply successfully
(unless the cluster state changes by the time the YAML is actually applied)
Validating or mutating hooks that have side effects can also be an issue
kubectl diff
Kubernetes 1.13 also introduced
kubectl diffkubectl diffdoes a server-side dry run, and shows differences
- Try
kubectl diffon a simple Pod YAML:curl -O https://k8smastery.com/just-a-pod.yamlkubectl apply -f just-a-pod.yaml# edit the image tag to :1.17kubectl diff -f just-a-pod.yaml
Note: we don't need to specify --validate=false here.
Cleanup
Let's cleanup before we start the next lecture!
- remove our "hello" pod:kubectl delete -f just-a-pod.yaml
Re-deploying DockerCoins with YAML
- OK back to DockerCoins! Let's deploy all the resources:
- Deploy or redeploy DockerCoins:kubectl apply -f https://k8smastery.com/dockercoins.yaml
k8smastery/dockercoins-apply.md
Rolling updates
(automatically generated title slide)
Rolling updates
By default (without rolling updates), when a scaled resource is updated:
new pods are created
old pods are terminated
... all at the same time
if something goes wrong, ¯\_(ツ)_/¯
Rolling updates
With rolling updates, when a Deployment is updated, it happens progressively
The Deployment controls multiple ReplicaSets
Rolling updates
With rolling updates, when a Deployment is updated, it happens progressively
The Deployment controls multiple ReplicaSets
Each ReplicaSet is a group of identical Pods
(with the same image, arguments, parameters ...)
Rolling updates
With rolling updates, when a Deployment is updated, it happens progressively
The Deployment controls multiple ReplicaSets
Each ReplicaSet is a group of identical Pods
(with the same image, arguments, parameters ...)
During the rolling update, we have at least two ReplicaSets:
the "new" set (corresponding to the "target" version)
at least one "old" set
Rolling updates
With rolling updates, when a Deployment is updated, it happens progressively
The Deployment controls multiple ReplicaSets
Each ReplicaSet is a group of identical Pods
(with the same image, arguments, parameters ...)
During the rolling update, we have at least two ReplicaSets:
the "new" set (corresponding to the "target" version)
at least one "old" set
We can have multiple "old" sets
(if we start another update before the first one is done)
Update strategy
- Two parameters determine the pace of the rollout:
maxUnavailableandmaxSurge
Update strategy
Two parameters determine the pace of the rollout:
maxUnavailableandmaxSurgeThey can be specified in absolute number of pods, or percentage of the
replicascount
Update strategy
Two parameters determine the pace of the rollout:
maxUnavailableandmaxSurgeThey can be specified in absolute number of pods, or percentage of the
replicascountAt any given time ...
there will always be at least
replicas-maxUnavailablepods availablethere will never be more than
replicas+maxSurgepods in totalthere will therefore be up to
maxUnavailable+maxSurgepods being updated
Update strategy
Two parameters determine the pace of the rollout:
maxUnavailableandmaxSurgeThey can be specified in absolute number of pods, or percentage of the
replicascountAt any given time ...
there will always be at least
replicas-maxUnavailablepods availablethere will never be more than
replicas+maxSurgepods in totalthere will therefore be up to
maxUnavailable+maxSurgepods being updated
We have the possibility of rolling back to the previous version
(if the update fails or is unsatisfactory in any way)
Checking current rollout parameters
- Recall how we build custom reports with
kubectlandjq:
- Show the rollout plan for our deployments:kubectl get deploy -o json |jq ".items[] | {name:.metadata.name} + .spec.strategy.rollingUpdate"
Rolling updates in practice
As of Kubernetes 1.8, we can do rolling updates with:
deployments,daemonsets,statefulsetsEditing one of these resources will automatically result in a rolling update
Rolling updates can be monitored with the
kubectl rolloutsubcommand
Rolling out the new worker service
- Let's monitor what's going on by opening a few terminals, and run:kubectl get pods -wkubectl get replicasets -wkubectl get deployments -w
- Update
workereither withkubectl edit, or by running:kubectl set image deploy worker worker=dockercoins/worker:v0.2
Rolling out the new worker service
- Let's monitor what's going on by opening a few terminals, and run:kubectl get pods -wkubectl get replicasets -wkubectl get deployments -w
- Update
workereither withkubectl edit, or by running:kubectl set image deploy worker worker=dockercoins/worker:v0.2
That rollout should be pretty quick. What shows in the web UI?
Give it some time
At first, it looks like nothing is happening (the graph remains at the same level)
According to
kubectl get deploy -w, thedeploymentwas updated really quicklyBut
kubectl get pods -wtells a different storyThe old
podsare still here, and they stay inTerminatingstate for a whileEventually, they are terminated; and then the graph decreases significantly
This delay is due to the fact that our worker doesn't handle signals
Kubernetes sends a "polite" shutdown request to the worker, which ignores it
After a grace period, Kubernetes gets impatient and kills the container
(The grace period is 30 seconds, but can be changed if needed)
Rolling out something invalid
- What happens if we make a mistake?
Update
workerby specifying a non-existent image:kubectl set image deploy worker worker=dockercoins/worker:v0.3Check what's going on:
kubectl rollout status deploy worker
Rolling out something invalid
- What happens if we make a mistake?
Update
workerby specifying a non-existent image:kubectl set image deploy worker worker=dockercoins/worker:v0.3Check what's going on:
kubectl rollout status deploy worker
Our rollout is stuck. However, the app is not dead.
(After a minute, it will stabilize to be 20-25% slower.)
What's going on with our rollout?
Why is our app a bit slower?
Because
MaxUnavailable=25%... So the rollout terminated 2 replicas out of 10 available
Okay, but why do we see 5 new replicas being rolled out?
Because
MaxSurge=25%... So in addition to replacing 2 replicas, the rollout is also starting 3 more
It rounded down the number of MaxUnavailable pods conservatively,
but the total number of pods being rolled out is allowed to be 25+25=50%
The nitty-gritty details
We start with 10 pods running for the
workerdeploymentCurrent settings: MaxUnavailable=25% and MaxSurge=25%
When we start the rollout:
- two replicas are taken down (as per MaxUnavailable=25%)
- two others are created (with the new version) to replace them
- three others are created (with the new version) per MaxSurge=25%)
Now we have 8 replicas up and running, and 5 being deployed
Our rollout is stuck at this point!
Checking the dashboard during the bad rollout
If you didn't deploy the Kubernetes dashboard earlier, just skip this slide.
Connect to the dashboard that we deployed earlier
Check that we have failures in Deployments, Pods, and Replica Sets
Can we see the reason for the failure?
Recovering from a bad rollout
We could push some
v0.3image(the pod retry logic will eventually catch it and the rollout will proceed)
Or we could invoke a manual rollback
- Cancel the deployment and wait for the dust to settle:kubectl rollout undo deploy workerkubectl rollout status deploy worker
Rolling back to an older version
We reverted to
v0.2But this version still has a performance problem
How can we get back to the previous version?
Multiple "undos"
- What happens if we try
kubectl rollout undoagain?
Try it:
kubectl rollout undo deployment workerCheck the web UI, the list of pods ...
🤔 That didn't work.
Multiple "undos" don't work
If we see successive versions as a stack:
kubectl rollout undodoesn't "pop" the last element from the stackit copies the N-1th element to the top
Multiple "undos" just swap back and forth between the last two versions!
- Go back to v0.2 again:kubectl rollout undo deployment worker
In this specific scenario
Our version numbers are easy to guess
What if we had used git hashes?
What if we had changed other parameters in the Pod spec?
Listing versions
- We can list successive versions of a Deployment with
kubectl rollout history
- Look at our successive versions:kubectl rollout history deployment worker
We don't see all revisions.
We might see something like 1, 4, 5.
(Depending on how many "undos" we did before.)
Explaining deployment revisions
These revisions correspond to our ReplicaSets
This information is stored in the ReplicaSet annotations
- Check the annotations for our replica sets:kubectl describe replicasets -l app=worker | grep -A3 ^Annotations
What about the missing revisions?
The missing revisions are stored in another annotation:
deployment.kubernetes.io/revision-historyThese are not shown in
kubectl rollout historyWe could easily reconstruct the full list with a script
(if we wanted to!)
Rolling back to an older version
kubectl rollout undocan work with a revision number
Roll back to the "known good" deployment version:
kubectl rollout undo deployment worker --to-revision=1Check the web UI or the list of pods
Changing rollout parameters
What if we wanted to, all at once:
- change image to
v0.1 - be conservative on availability (always have desired number of available workers)
- go slow on rollout speed (update only one pod at a time)
- give some time to our workers to "warm up" before starting more
- change image to
The corresponding changes can be expressed in the following YAML snippet:
spec: template: spec: containers: - name: worker image: dockercoins/worker:v0.1 strategy: rollingUpdate: maxUnavailable: 0 maxSurge: 1 minReadySeconds: 10Applying changes through a YAML patch
We could use
kubectl edit deployment workerBut we could also use
kubectl patchwith the exact YAML shown before
- Apply all our changes and wait for them to take effect:kubectl patch deployment worker -p "spec:template:spec:containers:- name: workerimage: dockercoins/worker:v0.1strategy:rollingUpdate:maxUnavailable: 0maxSurge: 1minReadySeconds: 10"kubectl rollout status deployment workerkubectl get deploy -o json worker |jq "{name:.metadata.name} + .spec.strategy.rollingUpdate"
Healthchecks
(automatically generated title slide)
Healthchecks
- Healthchecks are key to providing built-in lifecycle automation
Healthchecks
Healthchecks are key to providing built-in lifecycle automation
Healthchecks are probes that apply to containers (not to pods)
Kubernetes will take action on containers that fail healthchecks
Healthchecks
Healthchecks are key to providing built-in lifecycle automation
Healthchecks are probes that apply to containers (not to pods)
Kubernetes will take action on containers that fail healthchecks
Each container can have three (optional) probes:
liveness = is this container dead or alive? (most important probe)
readiness = is this container ready to serve traffic? (only needed if a service)
startup = is this container still starting up? (alpha in 1.16)
Healthchecks
Healthchecks are key to providing built-in lifecycle automation
Healthchecks are probes that apply to containers (not to pods)
Kubernetes will take action on containers that fail healthchecks
Each container can have three (optional) probes:
liveness = is this container dead or alive? (most important probe)
readiness = is this container ready to serve traffic? (only needed if a service)
startup = is this container still starting up? (alpha in 1.16)
Different probe handlers are available (HTTP, TCP, program execution)
Healthchecks
Healthchecks are key to providing built-in lifecycle automation
Healthchecks are probes that apply to containers (not to pods)
Kubernetes will take action on containers that fail healthchecks
Each container can have three (optional) probes:
liveness = is this container dead or alive? (most important probe)
readiness = is this container ready to serve traffic? (only needed if a service)
startup = is this container still starting up? (alpha in 1.16)
Different probe handlers are available (HTTP, TCP, program execution)
They don't replace a full monitoring solution
Let's see the difference and how to use them!
Liveness probe
Indicates if the container is dead or alive
A dead container cannot come back to life
If the liveness probe fails, the container is killed
(to make really sure that it's really dead; no zombies or undeads!)
What happens next depends on the pod's
restartPolicy:Never: the container is not restartedOnFailureorAlways: the container is restarted
When to use a liveness probe
To indicate failures that can't be recovered
deadlocks (causing all requests to time out)
internal corruption (causing all requests to error)
Anything where our incident response would be "just restart/reboot it"
Do not use liveness probes for problems that can't be fixed by a restart
- Otherwise we just restart our pods for no reason, creating useless load
Readiness probe
Indicates if the container is ready to serve traffic
If a container becomes "unready" it might be ready again soon
If the readiness probe fails:
the container is not killed
if the pod is a member of a service, it is temporarily removed
it is re-added as soon as the readiness probe passes again
When to use a readiness probe
To indicate failure due to an external cause
database is down or unreachable
mandatory auth or other backend service unavailable
To indicate temporary failure or unavailability
application can only service N parallel connections
runtime is busy doing garbage collection or initial data load
Startup probe
Kubernetes 1.16 introduces a third type of probe:
startupProbe(it is in
alphain Kubernetes 1.16)It can be used to indicate "container not ready yet"
process is still starting
loading external data, priming caches
Before Kubernetes 1.16, we had to use the
initialDelaySecondsparameter(available for both liveness and readiness probes)
initialDelaySecondsis a rigid delay (always wait X before running probes)startupProbeworks better when a container start time can vary a lot
Benefits of using probes
Rolling updates proceed when containers are actually ready
(as opposed to merely started)
Containers in a broken state get killed and restarted
(instead of serving errors or timeouts)
Unavailable backends get removed from load balancer rotation
(thus improving response times across the board)
If a probe is not defined, it's as if there was an "always successful" probe
Different types of probe handlers
HTTP request
specify URL of the request (and optional headers)
any status code between 200 and 399 indicates success
TCP connection
- the probe succeeds if the TCP port is open
arbitrary exec
a command is executed in the container
exit status of zero indicates success
Timing and thresholds
Probes are executed at intervals of
periodSeconds(default: 10)The timeout for a probe is set with
timeoutSeconds(default: 1)
If a probe takes longer than that, it is considered as a FAIL
A probe is considered successful after
successThresholdsuccesses (default: 1)A probe is considered failing after
failureThresholdfailures (default: 3)A probe can have an
initialDelaySecondsparameter (default: 0)Kubernetes will wait that amount of time before running the probe for the first time
(this is important to avoid killing services that take a long time to start)
Example: HTTP probe
Here is a pod template for the rng web service of the DockerCoins app:
apiVersion: v1kind: Podmetadata: name: rng-with-livenessspec: containers: - name: rng image: dockercoins/rng:v0.1 livenessProbe: httpGet: path: / port: 80 initialDelaySeconds: 10 periodSeconds: 1If the backend serves an error, or takes longer than 1s, 3 times in a row, it gets killed.
Example: exec probe
Here is a pod template for a Redis server:
apiVersion: v1kind: Podmetadata: name: redis-with-livenessspec: containers: - name: redis image: redis livenessProbe: exec: command: ["redis-cli", "ping"]If the Redis process becomes unresponsive, it will be killed.
Should probes check container Dependencies?
- A HTTP/TCP probe can't check an external dependency
Should probes check container Dependencies?
A HTTP/TCP probe can't check an external dependency
But a HTTP URL could kick off code to validate a remote dependency
Should probes check container Dependencies?
A HTTP/TCP probe can't check an external dependency
But a HTTP URL could kick off code to validate a remote dependency
If a web server depends on a database to function, and the database is down:
the web server's liveness probe should succeed
the web server's readiness probe should fail
Should probes check container Dependencies?
A HTTP/TCP probe can't check an external dependency
But a HTTP URL could kick off code to validate a remote dependency
If a web server depends on a database to function, and the database is down:
the web server's liveness probe should succeed
the web server's readiness probe should fail
Same thing for any hard dependency (without which the container can't work)
Should probes check container Dependencies?
A HTTP/TCP probe can't check an external dependency
But a HTTP URL could kick off code to validate a remote dependency
If a web server depends on a database to function, and the database is down:
the web server's liveness probe should succeed
the web server's readiness probe should fail
Same thing for any hard dependency (without which the container can't work)
Do not fail liveness probes for problems that are external to the container
Healthchecks for workers
(In that context, worker = process that doesn't accept connections)
Readiness isn't useful
(because workers aren't backends for a service)
Healthchecks for workers
(In that context, worker = process that doesn't accept connections)
Readiness isn't useful
(because workers aren't backends for a service)
Liveness may help us restart a broken worker, but how can we check it?
Embedding an HTTP server is a (potentially expensive) option
Healthchecks for workers
(In that context, worker = process that doesn't accept connections)
Readiness isn't useful
(because workers aren't backends for a service)
Liveness may help us restart a broken worker, but how can we check it?
Embedding an HTTP server is a (potentially expensive) option
Using a "lease" file can be relatively easy:
touch a file during each iteration of the main loop
check the timestamp of that file from an exec probe
Writing logs (and checking them from the probe) also works
Questions to ask before adding healthchecks
Do we want liveness, readiness, both?
(sometimes, we can use the same check, but with different failure thresholds)
Questions to ask before adding healthchecks
Do we want liveness, readiness, both?
(sometimes, we can use the same check, but with different failure thresholds)
Do we have existing HTTP endpoints that we can use?
Do we need to add new endpoints, or perhaps use something else?
Questions to ask before adding healthchecks
Do we want liveness, readiness, both?
(sometimes, we can use the same check, but with different failure thresholds)
Do we have existing HTTP endpoints that we can use?
Do we need to add new endpoints, or perhaps use something else?
Are our healthchecks likely to use resources and/or slow down the app?
Questions to ask before adding healthchecks
Do we want liveness, readiness, both?
(sometimes, we can use the same check, but with different failure thresholds)
Do we have existing HTTP endpoints that we can use?
Do we need to add new endpoints, or perhaps use something else?
Are our healthchecks likely to use resources and/or slow down the app?
Do they depend on additional services?
(this can be particularly tricky)
Adding healthchecks to an app
Let's add healthchecks to DockerCoins!
We will examine the questions of the previous slide
Then we will review each component individually to add healthchecks
Liveness, readiness, or both?
To answer that question, we need to see the app run for a while
Do we get temporary, recoverable glitches?
→ then use readiness
Or do we get hard lock-ups requiring a restart?
→ then use liveness
In the case of DockerCoins, we don't know yet!
Let's pick liveness
Do we have HTTP endpoints that we can use?
Each of the 3 web services (hasher, rng, webui) has a trivial route on
/These routes:
don't seem to perform anything complex or expensive
don't seem to call other services
Perfect!
(See next slides for individual details)
-
get '/' do"HASHER running on #{Socket.gethostname}\n"end
-
@app.route("/")def index():return "RNG running on {}\n".format(hostname)
-
app.get('/', function (req, res) {res.redirect('/index.html');});
Retrieving DockerCoins manifests
I've split up the previous
dockercoins.yamlinto one-resource-per-fileThis works with the
applycommand, and is easier for humans to manageClone them locally so we can add healthchecks and re-apply
Clone that repository:
git clone https://github.com/bretfisher/kubercoinsChange directory to the repository:
cd kubercoins
A simple HTTP liveness probe
This is what our liveness probe should look like:
containers:- name: ... image: ... livenessProbe: httpGet: path: / port: 80 initialDelaySeconds: 30 periodSeconds: 5This will give 30 seconds to the service to start. (Way more than necessary!)
It will run the probe every 5 seconds.
It will use the default timeout (1 second).
It will use the default failure threshold (3 failed attempts = dead).
It will use the default success threshold (1 successful attempt = alive).
Adding the liveness probe
Let's add the liveness probe, then deploy DockerCoins
Remember if you don't have DockerCoins running, this will create
If you already have DockerCoins running, this will update
rng
Edit
rng-deployment.yamland add the liveness probevim rng-deployment.yamlLoad the YAML for all the resources of DockerCoins
kubectl apply -f .
Testing the liveness probe
The rng service needs 100ms to process a request
(because it is single-threaded and sleeps 0.1s in each request)
The probe timeout is set to 1 second
If we send more than 10 requests per second per backend, it will break
Let's generate traffic and see what happens!
- Get the ClusterIP address of the rng service:kubectl get svc rng
Monitoring the rng service
- Each command below will show us what's happening on a different level
In one window, monitor cluster events:
kubectl get events -wIn another window, monitor pods status:
kubectl get pods -w
Generating traffic
- Let's use
ab(Apache Bench) to send concurrent requests to rng
In yet another window, generate traffic using
shpod:kubectl attach --namespace=shpod -ti shpodab -c 10 -n 1000 http://<ClusterIP>/1Experiment with higher values of
-cand see what happens
The
-cparameter indicates the number of concurrent requestsThe final
/1is important to generate actual traffic(otherwise we would use the ping endpoint, which doesn't sleep 0.1s per request)
Discussion
Above a given threshold, the liveness probe starts failing
(about 10 concurrent requests per backend should be plenty enough)
When the liveness probe fails 3 times in a row, the container is restarted
During the restart, there is less capacity available
... Meaning that the other backends are likely to timeout as well
... Eventually causing all backends to be restarted
... And each fresh backend gets restarted, too
This goes on until the load goes down, or we add capacity
This wouldn't be a good healthcheck in a real application!
Better healthchecks
We need to make sure that the healthcheck doesn't trip when performance degrades due to external pressure
Using a readiness check would have fewer effects
(but it would still be an imperfect solution)
A possible combination:
readiness check with a short timeout / low failure threshold
liveness check with a longer timeout / higher failure threshold
Healthchecks for redis
A liveness probe is enough
(it's not useful to remove a backend from rotation when it's the only one)
We could use an exec probe running
redis-cli ping
Exec probes and zombies
When using exec probes, we should make sure that we have a zombie reaper
🤔🧐🧟 Wait, what?
When a process terminates, its parent must call
wait()/waitpid()(this is how the parent process retrieves the child's exit status)
In the meantime, the process is in zombie state
(the process state will show as
Zinps,top...)When a process is killed, its children are orphaned and attached to PID 1
PID 1 has the responsibility of reaping these processes when they terminate
OK, but how does that affect us?
PID 1 in containers
On ordinary systems, PID 1 (
/sbin/init) has logic to reap processesIn containers, PID 1 is typically our application process
(e.g. Apache, the JVM, NGINX, Redis ...)
These do not take care of reaping orphans
If we use exec probes, we need to add a process reaper
We can add tini to our images
Or share the PID namespace between containers of a pod
(and have gcr.io/pause take care of the reaping)
Discussion of this in Video - 10 Ways to Shoot Yourself in the Foot with Kubernetes, #9 Will Surprise You
Tini and redis ping in a liveness probe
Add tini to your own custom redis image
Change the kubercoins YAML to use your own image
Create a liveness probe in kubercoins YAML
Use
exechandeler and runtini -s -- redis-cli pingExample repo here: github.com/BretFisher/redis-tini
containers:- name: redis image: custom-redis-image livenessProbe: exec: command: - /tini - -s - -- - redis-cli - ping initialDelaySeconds: 30 periodSeconds: 5Cleanup
Let's cleanup before we start the next lecture!
- remove our DockerCoin resources (for now):kubectl delete -f https://k8smastery.com/dockercoins.yaml
k8smastery/cleanup-dockercoins.md
Managing configuration
(automatically generated title slide)
Managing configuration
Some applications need to be configured (obviously!)
There are many ways for our code to pick up configuration:
command-line arguments
environment variables
configuration files
configuration servers (getting configuration from a database, an API...)
... and more (because programmers can be very creative!)
How can we do these things with containers and Kubernetes?
Passing configuration to containers
There are many ways to pass configuration to code running in a container:
baking it into a custom image
command-line arguments
environment variables
injecting configuration files
exposing it over the Kubernetes API
configuration servers
Let's review these different strategies!
Baking custom images
Put the configuration in the image
(it can be in a configuration file, but also
ENVorCMDactions)It's easy! It's simple!
Unfortunately, it also has downsides:
multiplication of images
different images for dev, staging, prod ...
minor reconfigurations require a whole build/push/pull cycle
Avoid doing it unless you don't have the time to figure out other options
Command-line arguments
Pass options to
argsarray in the container specificationExample (source):
args:- "--data-dir=/var/lib/etcd"- "--advertise-client-urls=http://127.0.0.1:2379"- "--listen-client-urls=http://127.0.0.1:2379"- "--listen-peer-urls=http://127.0.0.1:2380"- "--name=etcd"The options can be passed directly to the program that we run ...
... or to a wrapper script that will use them to e.g. generate a config file
Command-line arguments, pros & cons
Works great when options are passed directly to the running program
(otherwise, a wrapper script can work around the issue)
Works great when there aren't too many parameters
(to avoid a 20-lines
argsarray)Requires documentation and/or understanding of the underlying program
("which parameters and flags do I need, again?")
Well-suited for mandatory parameters (without default values)
Not ideal when we need to pass a real configuration file anyway
Environment variables
Pass options through the
envmap in the container specificationExample:
env:- name: ADMIN_PORTvalue: "8080"- name: ADMIN_AUTHvalue: Basic- name: ADMIN_CREDvalue: "admin:0pensesame!"
value must be a string! Make sure that numbers and fancy strings are quoted.
🤔 Why this weird {name: xxx, value: yyy} scheme? It will be revealed soon!
The Downward API
In the previous example, environment variables have fixed values
We can also use a mechanism called the Downward API
The Downward API allows exposing pod or container information
either through special files (we won't show that for now)
or through environment variables
The value of these environment variables is computed when the container is started
Remember: environment variables won't (can't) change after container start
Let's see a few concrete examples!
Exposing the pod's namespace
- name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespaceUseful to generate FQDN of services
(in some contexts, a short name is not enough)
For instance, the two commands should be equivalent:
curl api-backendcurl api-backend.$MY_POD_NAMESPACE.svc.cluster.local
Exposing the pod's IP address
- name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIPUseful if we need to know our IP address
(we could also read it from
eth0, but this is more solid)
Exposing the container's resource limits
- name: MY_MEM_LIMIT valueFrom: resourceFieldRef: containerName: test-container resource: limits.memoryUseful for runtimes where memory is garbage collected
Example: the JVM
(the memory available to the JVM should be set with the
-Xmxflag)Best practice: set a memory limit, and pass it to the runtime
Note: recent versions of the JVM can do this automatically
(see JDK-8146115) and this blog post for detailed examples)
More about the Downward API
This documentation page tells more about these environment variables
And this one explains the other way to use the Downward API
(through files that get created in the container filesystem)
Environment variables, pros and cons
Works great when the running program expects these variables
Works great for optional parameters with reasonable defaults
(since the container image can provide these defaults)
Sort of auto-documented
(we can see which environment variables are defined in the image, and their values)
Can be (ab)used with longer values ...
... You can put an entire Tomcat configuration file in an environment ...
... But should you?
(Do it if you really need to, we're not judging! But we'll see better ways.)
Injecting configuration files with ConfigMaps
Sometimes, there is no way around it: we need to inject a full config file
Kubernetes provides a mechanism for that purpose:
ConfigMapsA ConfigMap is a Kubernetes resource that exists in a namespace
Conceptually, it's a key/value map
(values are arbitrary strings)
We can think about them in (at least) two different ways:
as holding entire configuration file(s)
as holding individual configuration parameters
Note: to hold sensitive information, we can use "Secrets", which are another type of resource behaving very much like ConfigMaps. We'll cover them just after!
ConfigMaps storing entire files
In this case, each key/value pair corresponds to a configuration file
Key = name of the file
Value = content of the file
There can be one key/value pair, or as many as necessary
(for complex apps with multiple configuration files)
Examples:
# Create a ConfigMap with a single key, "app.conf"kubectl create configmap my-app-config --from-file=app.conf# Create a ConfigMap with a single key, "app.conf" but another filekubectl create configmap my-app-config --from-file=app.conf=app-prod.conf# Create a ConfigMap with multiple keys (one per file in the config.d directory)kubectl create configmap my-app-config --from-file=config.d/
ConfigMaps storing individual parameters
In this case, each key/value pair corresponds to a parameter
Key = name of the parameter
Value = value of the parameter
Examples:
# Create a ConfigMap with two keyskubectl create cm my-app-config \--from-literal=foreground=red \--from-literal=background=blue# Create a ConfigMap from a file containing key=val pairskubectl create cm my-app-config \--from-env-file=app.conf
Exposing ConfigMaps to containers
ConfigMaps can be exposed as plain files in the filesystem of a container
this is achieved by declaring a volume and mounting it in the container
this is particularly effective for ConfigMaps containing whole files
ConfigMaps can be exposed as environment variables in the container
this is achieved with the Downward API
this is particularly effective for ConfigMaps containing individual parameters
Let's see how to do both!
Passing a configuration file with a ConfigMap
We will start a load balancer powered by HAProxy
We will use the official
haproxyimageIt expects to find its configuration in
/usr/local/etc/haproxy/haproxy.cfgWe will provide a simple HAProxy configuration
It listens on port 80, and load balances connections between IBM and Google
Creating the ConfigMap
Download our simple HAProxy config:
curl -O https://k8smastery.com/haproxy.cfgCreate a ConfigMap named
haproxyand holding the configuration file:kubectl create configmap haproxy --from-file=haproxy.cfgCheck what our ConfigMap looks like:
kubectl get configmap haproxy -o yaml
Using the ConfigMap
We are going to use the following pod definition:
apiVersion: v1kind: Podmetadata: name: haproxyspec: volumes: - name: config configMap: name: haproxy containers: - name: haproxy image: haproxy volumeMounts: - name: config mountPath: /usr/local/etc/haproxy/Using the ConfigMap
- Apply the resource definition from the previous slide
Create the HAProxy pod:
kubectl apply -f https://k8smastery.com/haproxy.yamlCheck the IP address allocated to the pod, inside
shpod:kubectl attach --namespace=shpod -ti shpodkubectl get pod haproxy -o wideIP=$(kubectl get pod haproxy -o json | jq -r .status.podIP)
Testing our load balancer
The load balancer will send:
half of the connections to Google
the other half to IBM
- Access the load balancer a few times:curl $IPcurl $IPcurl $IP
We should see connections served by Google, and others served by IBM.
(Each server sends us a redirect page. Look at the URL that they send us to!)
Exposing ConfigMaps with the Downward API
We are going to run a Docker registry on a custom port
By default, the registry listens on port 5000
This can be changed by setting environment variable
REGISTRY_HTTP_ADDRWe are going to store the port number in a ConfigMap
Then we will expose that ConfigMap as a container environment variable
Creating the ConfigMap
Our ConfigMap will have a single key,
http.addr:kubectl create configmap registry --from-literal=http.addr=0.0.0.0:80Check our ConfigMap:
kubectl get configmap registry -o yaml
Using the ConfigMap
We are going to use the following pod definition:
apiVersion: v1kind: Podmetadata: name: registryspec: containers: - name: registry image: registry env: - name: REGISTRY_HTTP_ADDR valueFrom: configMapKeyRef: name: registry key: http.addrUsing the ConfigMap
- The resource definition from the previous slide:
Create the registry pod:
kubectl apply -f https://k8smastery.com/registry.yamlCheck the IP address allocated to the pod:
kubectl attach --namespace=shpod -ti shpodkubectl get pod registry -o wideIP=$(kubectl get pod registry -o json | jq -r .status.podIP)Confirm that the registry is available on port 80:
curl $IP/v2/_catalog
Passwords, tokens, sensitive information
For sensitive information, there is another special resource: Secrets
Secrets and Configmaps work almost the same way
(we'll expose the differences on the next slide)
The intent is different, though:
"You should use secrets for things which are actually secret like API keys, credentials, etc., and use config map for not-secret configuration data."
"In the future there will likely be some differentiators for secrets like rotation or support for backing the secret API w/ HSMs, etc."
(Source: the author of both features)
Differences between ConfigMaps and Secrets
Secrets are base64-encoded when shown with
kubectl get secrets -o yamlkeep in mind that this is just encoding, not encryption
it is very easy to automatically extract and decode secrets
With RBAC, we can authorize a user to access ConfigMaps, but not Secrets
(since they are two different kinds of resources)
Cleanup
Let's cleanup before we start the next lecture!
- remove our pods:kubectl delete pod/haproxy pod/registry
k8smastery/cleanup-haproxy-registry.md
Exposing HTTP services with Ingress resources
(automatically generated title slide)
Exposing HTTP services with Ingress resources
(automatically generated title slide)
Exposing HTTP services with Ingress resources
Services give us a way to access a pod or a set of pods
Services can be exposed to the outside world:
with type
NodePort(on a port >30000)with type
LoadBalancer(allocating an external load balancer)
Exposing HTTP services with Ingress resources
Services give us a way to access a pod or a set of pods
Services can be exposed to the outside world:
with type
NodePort(on a port >30000)with type
LoadBalancer(allocating an external load balancer)
What about HTTP services?
how can we expose
webui,rng,hasher?the Kubernetes dashboard?
all on the same IP and port?
Exposing HTTP services
If we use
NodePortservices, clients have to specify port numbers(i.e. http://xxxxx:31234 instead of just http://xxxxx)
Exposing HTTP services
If we use
NodePortservices, clients have to specify port numbers(i.e. http://xxxxx:31234 instead of just http://xxxxx)
LoadBalancerservices are nice, but:they are not available in all environments
they often carry an additional cost (e.g. they provision an ELB)
They often work at OSI Layer 4 (IP+Port) and not Layer 7 (HTTP/S)
they require one extra step for DNS integration
(waiting for theLoadBalancerto be provisioned; then adding it to DNS)
Exposing HTTP services
If we use
NodePortservices, clients have to specify port numbers(i.e. http://xxxxx:31234 instead of just http://xxxxx)
LoadBalancerservices are nice, but:they are not available in all environments
they often carry an additional cost (e.g. they provision an ELB)
They often work at OSI Layer 4 (IP+Port) and not Layer 7 (HTTP/S)
they require one extra step for DNS integration
(waiting for theLoadBalancerto be provisioned; then adding it to DNS)
- We could build our own reverse proxy
Building a custom reverse proxy
There are many options available:
Apache, HAProxy, Envoy Proxy, Gloo, NGINX, Traefik,...
Most of these options require us to update/edit configuration files after each change
Some of them can pick up virtual hosts and backends from a configuration store
Building a custom reverse proxy
There are many options available:
Apache, HAProxy, Envoy Proxy, Gloo, NGINX, Traefik,...
Most of these options require us to update/edit configuration files after each change
Some of them can pick up virtual hosts and backends from a configuration store
Wouldn't it be nice if this configuration could be managed with the Kubernetes API?
Enter¹ Ingress resources!
¹ Pun maybe intended.
ingress vs. Ingress
ingress
ingress definition: Going in, entering. The opposite of egress (leaving)
In networking terms, ingress refers to handling incoming connections
Could imply incoming to firewall, network, or in this case, a server cluster
ingress vs. Ingress
ingress
ingress definition: Going in, entering. The opposite of egress (leaving)
In networking terms, ingress refers to handling incoming connections
Could imply incoming to firewall, network, or in this case, a server cluster
Ingress
Ingress (capital I) in these slides means the Kubernetes Ingress resource
Specific to HTTP/S
Ingress resources
Kubernetes API resource (
kubectl get ingress/ingresses/ing)Designed to expose HTTP services
Ingress resources
Kubernetes API resource (
kubectl get ingress/ingresses/ing)Designed to expose HTTP services
Basic features:
- load balancing
- SSL termination
- name-based virtual hosting
Ingress resources
Kubernetes API resource (
kubectl get ingress/ingresses/ing)Designed to expose HTTP services
Basic features:
- load balancing
- SSL termination
- name-based virtual hosting
Can also route to different services depending on:
- URI path (e.g.
/api→api-service,/static→assets-service) - Client headers, including cookies (for A/B testing, canary deployment...)
- and more!
- URI path (e.g.
Principle of operation
Step 1: deploy an Ingress controller
Ingress controller = load balancing proxy + control loop
the control loop watches over Ingress resources, and configures the LB accordingly
these might be two separate processes (NGINX sever + NGINX Ingress controller)
or a single app that knows how to speak to Kubernetes API (Traefik)
Principle of operation
Step 1: deploy an Ingress controller
Ingress controller = load balancing proxy + control loop
the control loop watches over Ingress resources, and configures the LB accordingly
these might be two separate processes (NGINX sever + NGINX Ingress controller)
or a single app that knows how to speak to Kubernetes API (Traefik)
Step 2: set up DNS (usually)
- associate external DNS entries with the load balancer or host address
Principle of operation
Step 1: deploy an Ingress controller
Ingress controller = load balancing proxy + control loop
the control loop watches over Ingress resources, and configures the LB accordingly
these might be two separate processes (NGINX sever + NGINX Ingress controller)
or a single app that knows how to speak to Kubernetes API (Traefik)
Step 2: set up DNS (usually)
- associate external DNS entries with the load balancer or host address
Step 3: create Ingress resources for our Service resources
these resources contain rules for handling HTTP/S connections
the Ingress controller picks up these resources and configures the LB
connections to the Ingress LB will be processed by the rules
Ingress in action: NGINX
(automatically generated title slide)
Ingress in action: NGINX
We will deploy the NGINX Ingress controller first
- this is a popular, yet arbitrary choice, the docs list over a dozen options
Ingress in action: NGINX
We will deploy the NGINX Ingress controller first
- this is a popular, yet arbitrary choice, the docs list over a dozen options
For DNS, we will use nip.io
*.127.0.0.1.nip.ioresolves to127.0.0.1we do this so we can use various FQDN's without editing our
hostsfile
We will create Ingress resources for various HTTP-based Services
Deploying pods listening on port 80
- We want our Ingress load balancer to be available on port 80
Deploying pods listening on port 80
We want our Ingress load balancer to be available on port 80
We could do that with a
LoadBalancerservice
Deploying pods listening on port 80
We want our Ingress load balancer to be available on port 80
We could do that with a
LoadBalancerservice... but it requires support from the underlying infrastructure
minikube and MicroK8s don't work with it
... but Docker Desktop supports it for
localhost!
Deploying pods listening on port 80
We want our Ingress load balancer to be available on port 80
We could do that with a
LoadBalancerservice... but it requires support from the underlying infrastructure
minikube and MicroK8s don't work with it
... but Docker Desktop supports it for
localhost!We could use pods specifying
hostPort: 80... but with most CNI plugins, this doesn't work or requires additional setup
Deploying pods listening on port 80
We want our Ingress load balancer to be available on port 80
We could do that with a
LoadBalancerservice... but it requires support from the underlying infrastructure
minikube and MicroK8s don't work with it
... but Docker Desktop supports it for
localhost!We could use pods specifying
hostPort: 80... but with most CNI plugins, this doesn't work or requires additional setup
We could use a
NodePortservice... but that requires changing the
--service-node-port-rangeflag in the API server
Deploying pods listening on port 80
We want our Ingress load balancer to be available on port 80
We could do that with a
LoadBalancerservice... but it requires support from the underlying infrastructure
minikube and MicroK8s don't work with it
... but Docker Desktop supports it for
localhost!We could use pods specifying
hostPort: 80... but with most CNI plugins, this doesn't work or requires additional setup
We could use a
NodePortservice... but that requires changing the
--service-node-port-rangeflag in the API serverLast resort: the
hostNetworkmode
Without hostNetwork
Normally, each pod gets its own network namespace
(sometimes called sandbox or network sandbox)
Without hostNetwork
Normally, each pod gets its own network namespace
(sometimes called sandbox or network sandbox)
An IP address is assigned to the pod
Without hostNetwork
Normally, each pod gets its own network namespace
(sometimes called sandbox or network sandbox)
An IP address is assigned to the pod
This IP address is routed/connected to the cluster network
Without hostNetwork
Normally, each pod gets its own network namespace
(sometimes called sandbox or network sandbox)
An IP address is assigned to the pod
This IP address is routed/connected to the cluster network
All containers of that pod are sharing that network namespace
(and therefore using the same IP address)
With hostNetwork: true
- No network namespace gets created
With hostNetwork: true
No network namespace gets created
The pod is using the network namespace of the host
It "sees" (and can use) the interfaces (and IP addresses) of the host (VM on macOS/Win)
With hostNetwork: true
No network namespace gets created
The pod is using the network namespace of the host
It "sees" (and can use) the interfaces (and IP addresses) of the host (VM on macOS/Win)
The pod can receive outside traffic directly, on any port
With hostNetwork: true
No network namespace gets created
The pod is using the network namespace of the host
It "sees" (and can use) the interfaces (and IP addresses) of the host (VM on macOS/Win)
The pod can receive outside traffic directly, on any port
Downside: with most network plugins, network policies won't work for that pod
most network policies work at the IP address level
filtering that pod = filtering traffic from the node
What you will use now
Docker Desktop:
no built-in Ingress installer, we'll provide you YAML
Ignores
hostNetwork, but Servicetype: LoadBalancerworks withlocalhost!
What you will use now
Docker Desktop:
no built-in Ingress installer, we'll provide you YAML
Ignores
hostNetwork, but Servicetype: LoadBalancerworks withlocalhost!
minikube:
has a built-in NGINX installer
minikube addons enable ingressBut, let's use YAML we provide for learning purposes
hostNetwork: trueenabled on pod works for minikube IP
What you will use now
Docker Desktop:
no built-in Ingress installer, we'll provide you YAML
Ignores
hostNetwork, but Servicetype: LoadBalancerworks withlocalhost!
minikube:
has a built-in NGINX installer
minikube addons enable ingressBut, let's use YAML we provide for learning purposes
hostNetwork: trueenabled on pod works for minikube IP
MicroK8s:
has a built-in NGINX installer
microk8s enable ingresslet's use YAML we provide anyway for learning purposes
hostNetwork: trueenabled on pod works for MicroK8s host IP
First steps with NGINX
Remember the three parts of Ingress:
Ingress controller pod(s) to monitor the API and run the LB/proxy
Ingress Resources that tell the LB where to route traffic
Services for your apps so the Ingress LB/proxy can route to your pods
First, lets apply YAML to create the Ingress controller
Deploying the NGINX Ingress controller
- We need the YAML templates from the kubernetes/ingress-nginx project
The two main sections in the YAML are:
Deploying the NGINX Ingress controller
- We need the YAML templates from the kubernetes/ingress-nginx project
The two main sections in the YAML are:
NGINX Deployment (or DaemonSet) and all its required resources
- Namespace
- ConfigMaps (storing NGINX configs)
- ServiceAccount (authenticate to Kubernetes API)
- Role/ClusterRole/RoleBindings (authorization to API parts)
- LimitRange (limit cpu/memory of NGINX)
Deploying the NGINX Ingress controller
- We need the YAML templates from the kubernetes/ingress-nginx project
The two main sections in the YAML are:
NGINX Deployment (or DaemonSet) and all its required resources
- Namespace
- ConfigMaps (storing NGINX configs)
- ServiceAccount (authenticate to Kubernetes API)
- Role/ClusterRole/RoleBindings (authorization to API parts)
- LimitRange (limit cpu/memory of NGINX)
Service to expose NGINX on 80/443
- different for each Kubernetes distribution
Running NGINX on our cluster
- Now let's deploy the NGINX controller. Pick your distro:
Apply the YAML
# for Docker Desktop, create Service with LoadBalancerkubectl apply -f https://k8smastery.com/ic-nginx-lb.yaml# for minikube/MicroK8s, create Service with hostNetworkkubectl apply -f https://k8smastery.com/ic-nginx-hn.yaml- Check the pod Statuskubectl describe -n ingress-nginx deploy/ingress-nginx-controller
Checking that NGINX runs correctly
- If NGINX started correctly, we now have a web server listening on each node
- Direct your browser to your Kubernetes IP on port 80
We should get a 404 page not found error.
This is normal: we haven't provided any Ingress rule yet.
Setting up DNS
To make our lives easier, we will use nip.io
Check out
http://cheddar.A.B.C.D.nip.io(replacing A.B.C.D with the IP address of your Kubernetes IP)
We should get the same
404 page not founderror(meaning that our DNS is "set up properly", so to speak!)
Setting up host-based routing ingress rules
We are going to use
bretfisher/cheeseimages(there are 3 tags available: wensleydale, cheddar, stilton)
Setting up host-based routing ingress rules
We are going to use
bretfisher/cheeseimages(there are 3 tags available: wensleydale, cheddar, stilton)
These images contain a simple static HTTP server sending a picture of cheese
Setting up host-based routing ingress rules
We are going to use
bretfisher/cheeseimages(there are 3 tags available: wensleydale, cheddar, stilton)
These images contain a simple static HTTP server sending a picture of cheese
We will run 3 deployments (one for each cheese)
We will create 3 services (one for each deployment)
Then we will create 3 ingress rules (one for each service)
Setting up host-based routing ingress rules
We are going to use
bretfisher/cheeseimages(there are 3 tags available: wensleydale, cheddar, stilton)
These images contain a simple static HTTP server sending a picture of cheese
We will run 3 deployments (one for each cheese)
We will create 3 services (one for each deployment)
Then we will create 3 ingress rules (one for each service)
We will route
<name-of-cheese>.A.B.C.D.nip.ioto the corresponding deployment
Running cheesy web servers
Run all three deployments:
kubectl create deployment cheddar --image=bretfisher/cheese:cheddarkubectl create deployment stilton --image=bretfisher/cheese:stiltonkubectl create deployment wensleydale --image=bretfisher/cheese:wensleydaleCreate a service for each of them:
kubectl expose deployment cheddar --port=80kubectl expose deployment stilton --port=80kubectl expose deployment wensleydale --port=80
What does an ingress resource look like?
Here is a minimal host-based ingress resource:
apiVersion: networking.k8s.io/v1kind: Ingressmetadata: name: cheddarspec: rules: - host: cheddar.A.B.C.D.nip.io http: paths: - path: / pathType: Prefix backend: service: name: cheddar port: number: 80Creating our first ingress resources
Download our YAML
curl -O https://k8smastery.com/ingress.yamlEdit the file
ingress.yamlwhich has three Ingress resourcesReplace the A.B.C.D with your Kubernetes IP (
127.0.0.1forlocalhost)Apply the file
kubectl apply -f ingress.yaml
(An image of a piece of cheese should show up.)
Bring up the other Ingress resources
- Different cheeses should show up for each URL
Adding features to a Ingress resource
Reverse proxies have lots of features
Let's add a 301 redirect to a new Ingress resource using annotations
It will apply when any other path is used in URL that we didn't already add
- Create a redirect
kubectl apply -f https://k8smastery.com/redirect.yaml- Open http://< anything >.A.B.C.D.nip.io or localhost or A.B.C.D
- It should immediately redirect to google.com
Annotations can get weird and complex
apiVersion: networking.k8s.io/v1kind: Ingressmetadata: name: my-google annotations: # Notice this annotation is NGINX specific nginx.ingress.kubernetes.io/permanent-redirect: https://www.google.comspec: rules: # Ingress requires a rule and backend, even though it's not needed here - http: paths: - path: / pathType: Prefix backend: service: name: doesntmatter port: number: 80View Ingress resources
- Let's inspect some Ingress resources
- List all Ingress resources in the
defaultnamespace
kubectl get ingress- Get the details on the
cheddarIngress resource
kubectl describe ingress cheddar- Get the details on the
my-googleIngress resource
kubectl describe ingress my-google- Output
stiltonin YAML
kubectl get ingress/stilton -o yaml
Swapping NGINX for Traefik
(automatically generated title slide)
Swapping NGINX for Traefik
Traefik is a proxy with built-in Kubernetes Ingress support
It has a web dashboard, built-in Let's Encrypt, full TCP support, and more
Most importantly: Traefik releases are named after cheeses 🧀🎉
Swapping NGINX for Traefik
Traefik is a proxy with built-in Kubernetes Ingress support
It has a web dashboard, built-in Let's Encrypt, full TCP support, and more
Most importantly: Traefik releases are named after cheeses 🧀🎉
The Traefik documentation tells us to pick between Deployment and DaemonSet
We are going to use a DaemonSet so that each node can accept connections
Swapping NGINX for Traefik
Traefik is a proxy with built-in Kubernetes Ingress support
It has a web dashboard, built-in Let's Encrypt, full TCP support, and more
Most importantly: Traefik releases are named after cheeses 🧀🎉
The Traefik documentation tells us to pick between Deployment and DaemonSet
We are going to use a DaemonSet so that each node can accept connections
We provide a YAML file which is essentially the sum of:
Traefik's DaemonSet resources (patched with
hostNetworkand toleration's)Traefik's RBAC rules allowing it to watch necessary API objects
We will make a minor change to the YAML provided by Traefik to enable
hostNetworkfor MicroK8s/minikubeFor Docker Desktop we'll add a
type: LoadBalancerto the Service
Removing NGINX from our cluster
Before starting Traefik, let's remove the NGINX controller
This won't remove Services or Ingress resources
But it will make them unavailable from outside the cluster
Delete our NGINX controller and related resources:
# for Docker Desktop with LoadBalancerkubectl delete -f https://k8smastery.com/ic-nginx-lb.yaml# for minikube/MicroK8s with hostNetworkkubectl delete -f https://k8smastery.com/ic-nginx-hn.yamlAlso remove the redirect Ingress resource. It only worked in NGINX
kubectl delete -f https://k8smastery.com/redirect.yaml
Running Traefik on our cluster
- Now let's deploy the Traefik Ingress controller
Apply the YAML:
# for Docker Desktop with LoadBalancerkubectl apply -f https://k8smastery.com/ic-traefik-lb.yaml# for minikube/MicroK8s with hostNetworkkubectl apply -f https://k8smastery.com/ic-traefik-hn.yaml- Check the pod Statuskubectl describe -n kube-system ds/traefik-ingress-controller
Checking that Traefik runs correctly
- If Traefik started correctly, we can refresh a cheese and it still works
- Refresh http://cheddar.A.B.C.D.nip.io
Traefik web UI
Traefik provides a web dashboard on container port 8080
For those using the
LoadBalancermethod (Docker Desktop), it's enabled
- If using Docker Desktop, go to
http://localhost:8080
Traefik web UI
Traefik provides a web dashboard on container port 8080
For those using the
LoadBalancermethod (Docker Desktop), it's enabled
- If using Docker Desktop, go to
http://localhost:8080
For those using
hostNetwork, this could be a problemThe container won't start if anything is listening on
< host IP >:8080On MicroK8s, Kubernetes API runs on 8080 😢
Traefik web UI
Traefik provides a web dashboard on container port 8080
For those using the
LoadBalancermethod (Docker Desktop), it's enabled
- If using Docker Desktop, go to
http://localhost:8080
For those using
hostNetwork, this could be a problemThe container won't start if anything is listening on
< host IP >:8080On MicroK8s, Kubernetes API runs on 8080 😢
For those using minikube, you can un-comment the YAML and re-apply
Traefik web UI
Traefik provides a web dashboard on container port 8080
For those using the
LoadBalancermethod (Docker Desktop), it's enabled
- If using Docker Desktop, go to
http://localhost:8080
For those using
hostNetwork, this could be a problemThe container won't start if anything is listening on
< host IP >:8080On MicroK8s, Kubernetes API runs on 8080 😢
For those using minikube, you can un-comment the YAML and re-apply
You could also edit the resource(s) and manually add the details, e.g.
kubectl edit -n kube-system ds/traefik-ingress-controller
What about Traefik 2.x IngressRoute resources?
We've been using Traefik 2.x as the Ingress controller
Traefik released 2.0 in late 2019
Their documentation talks about IngressRoute resource
What about Traefik 2.x IngressRoute resources?
We've been using Traefik 2.x as the Ingress controller
Traefik released 2.0 in late 2019
Their documentation talks about IngressRoute resource
But IngressRoute is not a built-in resource of Kubernetes
Traefik 2.x now supports a custom CRD (Custom Resource Definition)
We'll explore why in a bit
Using multiple ingress controllers
You can have multiple ingress controllers active simultaneously
(e.g. Traefik, Gloo, and NGINX)
Using multiple ingress controllers
You can have multiple ingress controllers active simultaneously
(e.g. Traefik, Gloo, and NGINX)
You can even have multiple instances of the same controller
(e.g. one for internal, another for external traffic)
Using multiple ingress controllers
You can have multiple ingress controllers active simultaneously
(e.g. Traefik, Gloo, and NGINX)
You can even have multiple instances of the same controller
(e.g. one for internal, another for external traffic)
Since K8s 1.18,
ingressClassNamecan be used to tell which one to use
Using multiple ingress controllers
You can have multiple ingress controllers active simultaneously
(e.g. Traefik, Gloo, and NGINX)
You can even have multiple instances of the same controller
(e.g. one for internal, another for external traffic)
Since K8s 1.18,
ingressClassNamecan be used to tell which one to useIt's OK if multiple ingress controllers configure the same resource
(it just means that the service will be accessible through multiple paths)
Using multiple ingress controllers
You can have multiple ingress controllers active simultaneously
(e.g. Traefik, Gloo, and NGINX)
You can even have multiple instances of the same controller
(e.g. one for internal, another for external traffic)
Since K8s 1.18,
ingressClassNamecan be used to tell which one to useIt's OK if multiple ingress controllers configure the same resource
(it just means that the service will be accessible through multiple paths)
TCP/IP IP:PORT rules still apply: Only one can bind to 80 on host IP
Ingress resources: the good
The traffic flows directly from the ingress load balancer to the backends
it doesn't need to go through the
ClusterIPin fact, we don't even need a
ClusterIP(we can use a headless service)
Ingress resources: the good
The traffic flows directly from the ingress load balancer to the backends
it doesn't need to go through the
ClusterIPin fact, we don't even need a
ClusterIP(we can use a headless service)
The load balancer can be outside of Kubernetes
(as long as it has access to the cluster subnet)
This allows the use of external (hardware, physical machines...) load balancers
Ingress resources: the good
The traffic flows directly from the ingress load balancer to the backends
it doesn't need to go through the
ClusterIPin fact, we don't even need a
ClusterIP(we can use a headless service)
The load balancer can be outside of Kubernetes
(as long as it has access to the cluster subnet)
This allows the use of external (hardware, physical machines...) load balancers
Annotations can encode special features
(rate-limiting, A/B testing, session stickiness, etc.)
Ingress resources: the bad (cough Annotations cough)
Aforementioned "special features" are not standardized yet
Some controllers will support them; some won't
Ingress resources: the bad (cough Annotations cough)
Aforementioned "special features" are not standardized yet
Some controllers will support them; some won't
Even relatively common features (stripping a path prefix) can differ:
Ingress resources: the bad (cough Annotations cough)
Aforementioned "special features" are not standardized yet
Some controllers will support them; some won't
Even relatively common features (stripping a path prefix) can differ:
Annotations are not validated in CLI
Ingress resources: the bad (cough Annotations cough)
Aforementioned "special features" are not standardized yet
Some controllers will support them; some won't
Even relatively common features (stripping a path prefix) can differ:
Annotations are not validated in CLI
Some proxies provide a CRD (Custom Resource Definition) option
When not to use built-in Ingress resources
You need features beyond Ingress including:
- TCP support, traffic splitting, mTLS, egress, service mesh
- response transformation, routing to 2+ services
When not to use built-in Ingress resources
You need features beyond Ingress including:
- TCP support, traffic splitting, mTLS, egress, service mesh
- response transformation, routing to 2+ services
You have external load balancers (like AWS ELBs) which route to NodePorts
When not to use built-in Ingress resources
You need features beyond Ingress including:
- TCP support, traffic splitting, mTLS, egress, service mesh
- response transformation, routing to 2+ services
You have external load balancers (like AWS ELBs) which route to NodePorts
You don't need externally available HTTP services on the default ports
When not to use built-in Ingress resources
You need features beyond Ingress including:
- TCP support, traffic splitting, mTLS, egress, service mesh
- response transformation, routing to 2+ services
You have external load balancers (like AWS ELBs) which route to NodePorts
You don't need externally available HTTP services on the default ports
Your proxy of choice uses a CRD rather then a Ingress Resource
Using CRD's as alternatives to Ingress resources
Due to the limits of the built-in Ingress, many projects are moving to CRD's
For example, Traefik 2.x has a IngressRoute CRD option
Ambassador, a controller for Envoy proxy, uses a Mapping CRD
Using CRD's as alternatives to Ingress resources
Due to the limits of the built-in Ingress, many projects are moving to CRD's
For example, Traefik 2.x has a IngressRoute CRD option
Ambassador, a controller for Envoy proxy, uses a Mapping CRD
These CRD proxy options do ingress plus more (sometimes called API Gateways):
- TCP Support (anything beyond HTTP/HTTPS)
- Traffic splitting, rate limiting, circuit breaking, etc
- Complex traffic routing, request and response transformation
Using CRD's as alternatives to Ingress resources
Due to the limits of the built-in Ingress, many projects are moving to CRD's
For example, Traefik 2.x has a IngressRoute CRD option
Ambassador, a controller for Envoy proxy, uses a Mapping CRD
These CRD proxy options do ingress plus more (sometimes called API Gateways):
- TCP Support (anything beyond HTTP/HTTPS)
- Traffic splitting, rate limiting, circuit breaking, etc
- Complex traffic routing, request and response transformation
Once we consider CRD's, many more proxy options are available:
- Envoy Proxy based (Gloo, Ambassador, Contour)
- Other Proxies (Tyk, Traefik, Kong, KrakenD)
Using CRD's as alternatives to Ingress resources
Due to the limits of the built-in Ingress, many projects are moving to CRD's
For example, Traefik 2.x has a IngressRoute CRD option
Ambassador, a controller for Envoy proxy, uses a Mapping CRD
These CRD proxy options do ingress plus more (sometimes called API Gateways):
- TCP Support (anything beyond HTTP/HTTPS)
- Traffic splitting, rate limiting, circuit breaking, etc
- Complex traffic routing, request and response transformation
Once we consider CRD's, many more proxy options are available:
- Envoy Proxy based (Gloo, Ambassador, Contour)
- Other Proxies (Tyk, Traefik, Kong, KrakenD)
Eventually, some more advanced features might be added to "Ingress Resource 2.0"
We'll cover more after we learn about CRD's and Operators
Cleanup
Let's cleanup before we start the next lecture!
remove our ingress controller:
# for Docker Desktop with LoadBalancerkubectl delete -f https://k8smastery.com/ic-traefik-lb.yaml# for minikube/MicroK8s with hostNetworkkubectl delete -f https://k8smastery.com/ic-traefik-hn.yamlremove our ingress resources:
kubectl delete -f ingress.yamlkubectl delete -f https://k8smastery.com/redirect.yamlremove our cheeses:
kubectl delete svc/cheddar svc/stilton svc/wensleydalekubectl delete deploy/cheddar deploy/stilton deploy/wensleydale
Volumes
(automatically generated title slide)
Volumes
- Volumes are special directories that are mounted in containers
Volumes
Volumes are special directories that are mounted in containers
Volumes can have many different purposes:
- share files and directories between containers running on the same machine
Volumes
Volumes are special directories that are mounted in containers
Volumes can have many different purposes:
share files and directories between containers running on the same machine
share files and directories between containers and their host
Volumes
Volumes are special directories that are mounted in containers
Volumes can have many different purposes:
share files and directories between containers running on the same machine
share files and directories between containers and their host
centralize configuration information in Kubernetes and expose it to containers
Volumes
Volumes are special directories that are mounted in containers
Volumes can have many different purposes:
share files and directories between containers running on the same machine
share files and directories between containers and their host
centralize configuration information in Kubernetes and expose it to containers
manage credentials and secrets and expose them securely to containers
access storage systems (like Ceph, EBS, NFS, Portworx, and many others)
Kubernetes volumes vs. Docker volumes
Kubernetes and Docker volumes are very similar
(the Kubernetes documentation says otherwise ...
but it refers to Docker 1.7, which was released in 2015!)
Kubernetes volumes vs. Docker volumes
Kubernetes and Docker volumes are very similar
(the Kubernetes documentation says otherwise ...
but it refers to Docker 1.7, which was released in 2015!)Docker volumes allow us to share data between containers running on the same host
Kubernetes volumes vs. Docker volumes
Kubernetes and Docker volumes are very similar
(the Kubernetes documentation says otherwise ...
but it refers to Docker 1.7, which was released in 2015!)Docker volumes allow us to share data between containers running on the same host
Kubernetes volumes allow us to share data between containers in the same pod
Kubernetes volumes vs. Docker volumes
Kubernetes and Docker volumes are very similar
(the Kubernetes documentation says otherwise ...
but it refers to Docker 1.7, which was released in 2015!)Docker volumes allow us to share data between containers running on the same host
Kubernetes volumes allow us to share data between containers in the same pod
Both Docker and Kubernetes volumes enable access to storage systems
Kubernetes volumes vs. Docker volumes
Kubernetes and Docker volumes are very similar
(the Kubernetes documentation says otherwise ...
but it refers to Docker 1.7, which was released in 2015!)Docker volumes allow us to share data between containers running on the same host
Kubernetes volumes allow us to share data between containers in the same pod
Both Docker and Kubernetes volumes enable access to storage systems
Kubernetes volumes can also be used to expose configuration and secrets
Kubernetes volumes vs. Docker volumes
Kubernetes and Docker volumes are very similar
(the Kubernetes documentation says otherwise ...
but it refers to Docker 1.7, which was released in 2015!)Docker volumes allow us to share data between containers running on the same host
Kubernetes volumes allow us to share data between containers in the same pod
Both Docker and Kubernetes volumes enable access to storage systems
Kubernetes volumes can also be used to expose configuration and secrets
Docker has specific concepts for configuration and secrets
(but under the hood, the technical implementation is similar)
Volumes ≠ Persistent Volumes
- Volumes and Persistent Volumes are related, but very different!
Volumes ≠ Persistent Volumes
Volumes and Persistent Volumes are related, but very different!
Volumes:
appear in Pod specifications (we'll see that in a few slides)
do not exist as API resources (cannot do
kubectl get volumes)
Volumes ≠ Persistent Volumes
Volumes and Persistent Volumes are related, but very different!
Volumes:
appear in Pod specifications (we'll see that in a few slides)
do not exist as API resources (cannot do
kubectl get volumes)
Persistent Volumes:
are API resources (can do
kubectl get persistentvolumes)correspond to concrete volumes (e.g. on a SAN, EBS, etc.)
cannot be associated with a Pod directly
(they need a Persistent Volume Claim)
Adding a volume to a Pod
- We will start with the simplest Pod manifest we can find
Adding a volume to a Pod
We will start with the simplest Pod manifest we can find
We will add a volume to that Pod manifest
Adding a volume to a Pod
We will start with the simplest Pod manifest we can find
We will add a volume to that Pod manifest
We will mount that volume in a container in the Pod
Adding a volume to a Pod
We will start with the simplest Pod manifest we can find
We will add a volume to that Pod manifest
We will mount that volume in a container in the Pod
By default, this volume will be an
emptyDir(an empty directory)
Adding a volume to a Pod
We will start with the simplest Pod manifest we can find
We will add a volume to that Pod manifest
We will mount that volume in a container in the Pod
By default, this volume will be an
emptyDir(an empty directory)
It will hide ("shadow") the image directory where it's mounted
Our basic Pod
apiVersion: v1kind: Podmetadata: name: nginx-without-volumespec: containers: - name: nginx image: nginxThis is a MVP! (Minimum Viable Pod😉)
It runs a single NGINX container.
Trying the basic pod
- Create the Pod:kubectl create -f https://k8smastery.com/nginx-1-without-volume.yaml
Get its IP address:
IPADDR=$(kubectl get pod nginx-without-volume -o jsonpath={.status.podIP})Send a request with curl:
curl $IPADDR
(We should see the "Welcome to NGINX" page.)
Adding a volume
We need to add the volume in two places:
at the Pod level (to declare the volume)
at the container level (to mount the volume)
We will declare a volume named
wwwNo type is specified, so it will default to
emptyDir(as the name implies, it will be initialized as an empty directory at pod creation)
In that pod, there is also a container named
nginxThat container mounts the volume
wwwto path/usr/share/nginx/html/
The Pod with a volume
apiVersion: v1kind: Podmetadata: name: nginx-with-volumespec: volumes: - name: www containers: - name: nginx image: nginx volumeMounts: - name: www mountPath: /usr/share/nginx/html/Trying the Pod with a volume
- Create the Pod:kubectl create -f https://k8smastery.com/nginx-2-with-volume.yaml
Get its IP address:
IPADDR=$(kubectl get pod nginx-with-volume -o jsonpath={.status.podIP})Send a request with curl:
curl $IPADDR
(We should now see a "403 Forbidden" error page.)
Populating the volume with another container
Let's add another container to the Pod
Let's mount the volume in both containers
That container will populate the volume with static files
NGINX will then serve these static files
To populate the volume, we will clone the Spoon-Knife repository
this repository is https://github.com/octocat/Spoon-Knife
it's very popular (more than 100K forks!)
Sharing a volume between two containers
apiVersion: v1kind: Podmetadata: name: nginx-with-gitspec: volumes: - name: www containers: - name: nginx image: nginx volumeMounts: - name: www mountPath: /usr/share/nginx/html/ - name: git image: alpine command: [ "sh", "-c", "apk add git && git clone https://github.com/octocat/Spoon-Knife /www" ] volumeMounts: - name: www mountPath: /www/ restartPolicy: OnFailureSharing a volume, explained
We added another container to the pod
That container mounts the
wwwvolume on a different path (/www)It uses the
alpineimageWhen started, it installs
gitand clones theoctocat/Spoon-Kniferepository(that repository contains a tiny HTML website)
As a result, NGINX now serves this website
Trying the shared volume
This one will be time-sensitive!
We need to catch the Pod IP address as soon as it's created
Then send a request to it as fast as possible
- Watch the pods (so that we can catch the Pod IP address)kubectl get pods -o wide --watch
Shared volume in action
- Create the pod:kubectl create -f https://k8smastery.com/nginx-3-with-git.yaml
- As soon as we see its IP address, access it:curl $IP
- A few seconds later, the state of the pod will change; access it again:curl $IP
The first time, we should see "403 Forbidden".
The second time, we should see the HTML file from the Spoon-Knife repository.
Explanations
Both containers are started at the same time
NGINX starts very quickly
(it can serve requests immediately)
But at this point, the volume is empty
(NGINX serves "403 Forbidden")
The other containers installs git and clones the repository
(this takes a bit longer)
When the other container is done, the volume holds the repository
(NGINX serves the HTML file)
The devil is in the details
The default
restartPolicyisAlwaysThis would cause our
gitcontainer to run again ... and again ... and again(with an exponential back-off delay, as explained in the documentation)
That's why we specified
restartPolicy: OnFailure
Inconsistencies
There is a short period of time during which the website is not available
(because the
gitcontainer hasn't done its job yet)With a bigger website, we could get inconsistent results
(where only a part of the content is ready)
In real applications, this could cause incorrect results
How can we avoid that?
Init Containers
We can define containers that should execute before the main ones
They will be executed in order
(instead of in parallel)
They must all succeed before the main containers are started
This is exactly what we need here!
Let's see one in action
See Init Containers documentation for all the details.
Defining Init Containers
apiVersion: v1kind: Podmetadata: name: nginx-with-initspec: volumes: - name: www containers: - name: nginx image: nginx volumeMounts: - name: www mountPath: /usr/share/nginx/html/ initContainers: - name: git image: alpine command: [ "sh", "-c", "apk add --no-cache git && git clone https://github.com/octocat/Spoon-Knife /www" ] volumeMounts: - name: www mountPath: /www/Trying the init container
Repeat the same operation as earlier
(try to send HTTP requests as soon as the pod comes up)
This time, instead of "403 Forbidden" we get a "connection refused"
NGINX doesn't start until the git container has done its job
We never get inconsistent results
(a "half-ready" container)
Other uses of init containers
Load content
Generate configuration (or certificates)
Database migrations
Waiting for other services to be up
(to avoid flurry of connection errors in main container)
etc.
Volume lifecycle
The lifecycle of a volume is linked to the pod's lifecycle
This means that a volume is created when the pod is created
This is mostly relevant for
emptyDirvolumes(other volumes, like remote storage, are not "created" but rather "attached" )
A volume survives across container restarts
A volume is destroyed (or, for remote storage, detached) when the pod is destroyed
Stateful sets
(automatically generated title slide)
Stateful sets
Stateful sets are a type of resource in the Kubernetes API
(like pods, deployments, services...)
They offer mechanisms to deploy scaled stateful applications
At a first glance, they look like deployments:
a stateful set defines a pod spec and a number of replicas R
it will make sure that R copies of the pod are running
that number can be changed while the stateful set is running
updating the pod spec will cause a rolling update to happen
But they also have some significant differences
Stateful sets unique features
Pods in a stateful set are numbered (from 0 to R-1) and ordered
They are started and updated in order (from 0 to R-1)
A pod is started (or updated) only when the previous one is ready
They are stopped in reverse order (from R-1 to 0)
Each pod know its identity (i.e. which number it is in the set)
Each pod can discover the IP address of the others easily
The pods can persist data on attached volumes
🤔 Wait a minute ... Can't we already attach volumes to pods and deployments?
Revisiting volumes
Volumes are used for many purposes:
sharing data between containers in a pod
exposing configuration information and secrets to containers
accessing storage systems
Let's see examples of the latter usage
Volumes types
There are many types of volumes available:
public cloud storage (GCEPersistentDisk, AWSElasticBlockStore, AzureDisk...)
private cloud storage (Cinder, VsphereVolume...)
traditional storage systems (NFS, iSCSI, FC...)
distributed storage (Ceph, Glusterfs, Portworx...)
Using a persistent volume requires:
creating the volume out-of-band (outside of the Kubernetes API)
referencing the volume in the pod description, with all its parameters
Using a cloud volume
Here is a pod definition using an AWS EBS volume (that has to be created first):
apiVersion: v1kind: Podmetadata: name: pod-using-my-ebs-volumespec: containers: - image: ... name: container-using-my-ebs-volume volumeMounts: - mountPath: /my-ebs name: my-ebs-volume volumes: - name: my-ebs-volume awsElasticBlockStore: volumeID: vol-049df61146c4d7901 fsType: ext4Using an NFS volume
Here is another example using a volume on an NFS server:
apiVersion: v1kind: Podmetadata: name: pod-using-my-nfs-volumespec: containers: - image: ... name: container-using-my-nfs-volume volumeMounts: - mountPath: /my-nfs name: my-nfs-volume volumes: - name: my-nfs-volume nfs: server: 192.168.0.55 path: "/exports/assets"Shortcomings of volumes
Their lifecycle (creation, deletion...) is managed outside of the Kubernetes API
(we can't just use
kubectl apply/create/delete/...to manage them)If a Deployment uses a volume, all replicas end up using the same volume
That volume must then support concurrent access
some volumes do (e.g. NFS servers support multiple read/write access)
some volumes support concurrent reads
some volumes support concurrent access for colocated pods
What we really need is a way for each replica to have its own volume
Individual volumes
The Pods of a Stateful set can have individual volumes
(i.e. in a Stateful set with 3 replicas, there will be 3 volumes)
These volumes can be either:
allocated from a pool of pre-existing volumes (disks, partitions ...)
created dynamically using a storage system
This introduces a bunch of new Kubernetes resource types:
Persistent Volumes, Persistent Volume Claims, Storage Classes
(and also
volumeClaimTemplates, that appear within Stateful Set manifests!)
Stateful set recap
A Stateful sets manages a number of identical pods
(like a Deployment)
These pods are numbered, and started/upgraded/stopped in a specific order
These pods are aware of their number
(e.g., #0 can decide to be the primary, and #1 can be secondary)
These pods can find the IP addresses of the other pods in the set
(through a headless service)
These pods can each have their own persistent storage
(Deployments cannot do that)
Running a Consul cluster
(automatically generated title slide)
Running a Consul cluster
Here is a good use-case for Stateful sets!
We are going to deploy a Consul cluster with 3 nodes
Consul is a highly-available key/value store
(like etcd or Zookeeper)
One easy way to bootstrap a cluster is to tell each node:
the addresses of other nodes
how many nodes are expected (to know when quorum is reached)
Bootstrapping a Consul cluster
After reading the Consul documentation carefully (and/or asking around), we figure out the minimal command-line to run our Consul cluster.
consul agent -data-dir=/consul/data -client=0.0.0.0 -server -ui \ -bootstrap-expect=3 \ -retry-join=X.X.X.X \ -retry-join=Y.Y.Y.YReplace X.X.X.X and Y.Y.Y.Y with the addresses of other nodes
The same command-line can be used on all nodes (convenient!)
Cloud Auto-join
Since version 1.4.0, Consul can use the Kubernetes API to find its peers
This is called Cloud Auto-join
Instead of passing an IP address, we need to pass a parameter like this:
consul agent -retry-join "provider=k8s label_selector=\"app=consul\""Consul needs to be able to talk to the Kubernetes API
We can provide a
kubeconfigfileIf Consul runs in a pod, it will use the service account of the pod k8s/statefulsets.md
Setting up Cloud auto-join
We need to create a service account for Consul
We need to create a role that can
listandgetpodsWe need to bind that role to the service account
And of course, we need to make sure that Consul pods use that service account
Putting it all together
The file
k8s/consul.yamldefines the required resources(service account, cluster role, cluster role binding, service, stateful set)
It has a few extra touches:
a
podAntiAffinityprevents two pods from running on the same nodea
preStophook makes the pod leave the cluster when shutdown gracefully
This was inspired by this excellent tutorial by Kelsey Hightower. Some features from the original tutorial (TLS authentication between nodes and encryption of gossip traffic) were removed for simplicity.
Running our Consul cluster
- We'll use the provided YAML file
Create the stateful set and associated service:
kubectl apply -f ~/container.training/k8s/consul.yamlCheck the logs as the pods come up one after another:
stern consul
- Check the health of the cluster:kubectl exec consul-0 consul members
Caveats
We aren't using actual persistence yet
(no
volumeClaimTemplate, Persistent Volume, etc.)What happens if we lose a pod?
a new pod gets rescheduled (with an empty state)
the new pod tries to connect to the two others
it will be accepted (after 1-2 minutes of instability)
and it will retrieve the data from the other pods
Failure modes
What happens if we lose two pods?
manual repair will be required
we will need to instruct the remaining one to act solo
then rejoin new pods
What happens if we lose three pods? (aka all of them)
- we lose all the data (ouch)
If we run Consul without persistent storage, backups are a good idea!
Persistent Volumes Claims
(automatically generated title slide)
Persistent Volumes Claims
Our Pods can use a special volume type: a Persistent Volume Claim
A Persistent Volume Claim (PVC) is also a Kubernetes resource
(visible with
kubectl get persistentvolumeclaimsorkubectl get pvc)A PVC is not a volume; it is a request for a volume
It should indicate at least:
the size of the volume (e.g. "5 GiB")
the access mode (e.g. "read-write by a single pod")
What's in a PVC?
A PVC contains at least:
a list of access modes (ReadWriteOnce, ReadOnlyMany, ReadWriteMany)
a size (interpreted as the minimal storage space needed)
It can also contain optional elements:
a selector (to restrict which actual volumes it can use)
a storage class (used by dynamic provisioning, more on that later)
What does a PVC look like?
Here is a manifest for a basic PVC:
kind: PersistentVolumeClaimapiVersion: v1metadata: name: my-claimspec: accessModes: - ReadWriteOnce resources: requests: storage: 1GiUsing a Persistent Volume Claim
Here is a Pod definition like the ones shown earlier, but using a PVC:
apiVersion: v1kind: Podmetadata: name: pod-using-a-claimspec: containers: - image: ... name: container-using-a-claim volumeMounts: - mountPath: /my-vol name: my-volume volumes: - name: my-volume persistentVolumeClaim: claimName: my-claimCreating and using Persistent Volume Claims
PVCs can be created manually and used explicitly
(as shown on the previous slides)
They can also be created and used through Stateful Sets
(this will be shown later)
Lifecycle of Persistent Volume Claims
When a PVC is created, it starts existing in "Unbound" state
(without an associated volume)
A Pod referencing an unbound PVC will not start
(the scheduler will wait until the PVC is bound to place it)
A special controller continuously monitors PVCs to associate them with PVs
If no PV is available, one must be created:
manually (by operator intervention)
using a dynamic provisioner (more on that later)
Which PV gets associated to a PVC?
The PV must satisfy the PVC constraints
(access mode, size, optional selector, optional storage class)
The PVs with the closest access mode are picked
Then the PVs with the closest size
It is possible to specify a
claimRefwhen creating a PV(this will associate it to the specified PVC, but only if the PV satisfies all the requirements of the PVC; otherwise another PV might end up being picked)
For all the details about the PersistentVolumeClaimBinder, check this doc
Persistent Volume Claims and Stateful sets
A Stateful set can define one (or more)
volumeClaimTemplateEach
volumeClaimTemplatewill create one Persistent Volume Claim per podEach pod will therefore have its own individual volume
These volumes are numbered (like the pods)
Example:
- a Stateful set is named
db - it is scaled to replicas
- it has a
volumeClaimTemplatenameddata - then it will create pods
db-0,db-1,db-2 - these pods will have volumes named
data-db-0,data-db-1,data-db-2
- a Stateful set is named
Persistent Volume Claims are sticky
When updating the stateful set (e.g. image upgrade), each pod keeps its volume
When pods get rescheduled (e.g. node failure), they keep their volume
(this requires a storage system that is not node-local)
These volumes are not automatically deleted
(when the stateful set is scaled down or deleted)
If a stateful set is scaled back up later, the pods get their data back
Dynamic provisioners
A dynamic provisioner monitors unbound PVCs
It can create volumes (and the corresponding PV) on the fly
This requires the PVCs to have a storage class
(annotation
volume.beta.kubernetes.io/storage-provisioner)A dynamic provisioner only acts on PVCs with the right storage class
(it ignores the other ones)
Just like
LoadBalancerservices, dynamic provisioners are optional(i.e. our cluster may or may not have one pre-installed)
What's a Storage Class?
A Storage Class is yet another Kubernetes API resource
(visible with e.g.
kubectl get storageclassorkubectl get sc)It indicates which provisioner to use
(which controller will create the actual volume)
And arbitrary parameters for that provisioner
(replication levels, type of disk ... anything relevant!)
Storage Classes are required if we want to use dynamic provisioning
(but we can also create volumes manually, and ignore Storage Classes)
The default storage class
At most one storage class can be marked as the default class
(by annotating it with
storageclass.kubernetes.io/is-default-class=true)When a PVC is created, it will be annotated with the default storage class
(unless it specifies an explicit storage class)
This only happens at PVC creation
(existing PVCs are not updated when we mark a class as the default one)
Dynamic provisioning setup
This is how we can achieve fully automated provisioning of persistent storage.
Configure a storage system.
(It needs to have an API, or be capable of automated provisioning of volumes.)
Install a dynamic provisioner for this storage system.
(This is some specific controller code.)
Create a Storage Class for this system.
(It has to match what the dynamic provisioner is expecting.)
Annotate the Storage Class to be the default one.
Dynamic provisioning usage
After setting up the system (previous slide), all we need to do is:
Create a Stateful Set that makes use of a volumeClaimTemplate.
This will trigger the following actions.
The Stateful Set creates PVCs according to the
volumeClaimTemplate.The Stateful Set creates Pods using these PVCs.
The PVCs are automatically annotated with our Storage Class.
The dynamic provisioner provisions volumes and creates the corresponding PVs.
The PersistentVolumeClaimBinder associates the PVs and the PVCs together.
PVCs are now bound, the Pods can start.
Local Persistent Volumes
(automatically generated title slide)
Local Persistent Volumes
We want to run that Consul cluster and actually persist data
But we don't have a distributed storage system
We are going to use local volumes instead
(similar conceptually to
hostPathvolumes)We can use local volumes without installing extra plugins
However, they are tied to a node
If that node goes down, the volume becomes unavailable
k8s/local-persistent-volumes.md
With or without dynamic provisioning
We will deploy a Consul cluster with persistence
That cluster's StatefulSet will create PVCs
These PVCs will remain unbound¹, until we will create local volumes manually
(we will basically do the job of the dynamic provisioner)
Then, we will see how to automate that with a dynamic provisioner
¹Unbound = without an associated Persistent Volume.
k8s/local-persistent-volumes.md
If we have a dynamic provisioner ...
The labs in this section assume that we do not have a dynamic provisioner
If we do have one, we need to disable it
Check if we have a dynamic provisioner:
kubectl get storageclassIf the output contains a line with
(default), run this command:kubectl annotate sc storageclass.kubernetes.io/is-default-class- --allCheck again that it is no longer marked as
(default)
k8s/local-persistent-volumes.md
Deploying Consul
We will use a slightly different YAML file
The only differences between that file and the previous one are:
volumeClaimTemplatedefined in the Stateful Set specthe corresponding
volumeMountsin the Pod specthe label
consulhas been changed topersistentconsul
(to avoid conflicts with the other Stateful Set)
- Apply the persistent Consul YAML file:kubectl apply -f ~/container.training/k8s/persistent-consul.yaml
k8s/local-persistent-volumes.md
Observing the situation
- Let's look at Persistent Volume Claims and Pods
Check that we now have an unbound Persistent Volume Claim:
kubectl get pvcWe don't have any Persistent Volume:
kubectl get pvThe Pod
persistentconsul-0is not scheduled yet:kubectl get pods -o wide
Hint: leave these commands running with -w in different windows.
k8s/local-persistent-volumes.md
Explanations
In a Stateful Set, the Pods are started one by one
persistentconsul-1won't be created untilpersistentconsul-0is runningpersistentconsul-0has a dependency on an unbound Persistent Volume ClaimThe scheduler won't schedule the Pod until the PVC is bound
(because the PVC might be bound to a volume that is only available on a subset of nodes; for instance EBS are tied to an availability zone)
k8s/local-persistent-volumes.md
Creating Persistent Volumes
Let's create 3 local directories (
/mnt/consul) on node2, node3, node4Then create 3 Persistent Volumes corresponding to these directories
Create the local directories:
for NODE in node2 node3 node4; dossh $NODE sudo mkdir -p /mnt/consuldoneCreate the PV objects:
kubectl apply -f ~/container.training/k8s/volumes-for-consul.yaml
k8s/local-persistent-volumes.md
Check our Consul cluster
The PVs that we created will be automatically matched with the PVCs
Once a PVC is bound, its pod can start normally
Once the pod
persistentconsul-0has started,persistentconsul-1can be created, etc.Eventually, our Consul cluster is up, and backend by "persistent" volumes
- Check that our Consul clusters has 3 members indeed:kubectl exec persistentconsul-0 consul members
k8s/local-persistent-volumes.md
Devil is in the details (1/2)
The size of the Persistent Volumes is bogus
(it is used when matching PVs and PVCs together, but there is no actual quota or limit)
k8s/local-persistent-volumes.md
Devil is in the details (2/2)
This specific example worked because we had exactly 1 free PV per node:
if we had created multiple PVs per node ...
we could have ended with two PVCs bound to PVs on the same node ...
which would have required two pods to be on the same node ...
which is forbidden by the anti-affinity constraints in the StatefulSet
To avoid that, we need to associated the PVs with a Storage Class that has:
volumeBindingMode: WaitForFirstConsumer(this means that a PVC will be bound to a PV only after being used by a Pod)
See this blog post for more details
k8s/local-persistent-volumes.md
Bulk provisioning
It's not practical to manually create directories and PVs for each app
We could pre-provision a number of PVs across our fleet
We could even automate that with a Daemon Set:
creating a number of directories on each node
creating the corresponding PV objects
We also need to recycle volumes
... This can quickly get out of hand
k8s/local-persistent-volumes.md
Dynamic provisioning
We could also write our own provisioner, which would:
watch the PVCs across all namespaces
when a PVC is created, create a corresponding PV on a node
Or we could use one of the dynamic provisioners for local persistent volumes
(for instance the Rancher local path provisioner)
k8s/local-persistent-volumes.md
Strategies for local persistent volumes
Remember, when a node goes down, the volumes on that node become unavailable
High availability will require another layer of replication
(like what we've just seen with Consul; or primary/secondary; etc)
Pre-provisioning PVs makes sense for machines with local storage
(e.g. cloud instance storage; or storage directly attached to a physical machine)
Dynamic provisioning makes sense for large number of applications
(when we can't or won't dedicate a whole disk to a volume)
It's possible to mix both (using distinct Storage Classes)
k8s/local-persistent-volumes.md
Kustomize
(automatically generated title slide)
Kustomize
Kustomize lets us transform YAML files representing Kubernetes resources
The original YAML files are valid resource files
(e.g. they can be loaded with
kubectl apply -f)They are left untouched by Kustomize
Kustomize lets us define overlays that extend or change the resource files
Differences with Helm
Helm charts use placeholders
{{ like.this }}Kustomize "bases" are standard Kubernetes YAML
It is possible to use an existing set of YAML as a Kustomize base
As a result, writing a Helm chart is more work ...
... But Helm charts are also more powerful; e.g. they can:
use flags to conditionally include resources or blocks
check if a given Kubernetes API group is supported
Kustomize concepts
Kustomize needs a
kustomization.yamlfileThat file can be a base or a variant
If it's a base:
- it lists YAML resource files to use
If it's a variant (or overlay):
it refers to (at least) one base
and some patches
An easy way to get started with Kustomize
We are going to use Replicated Ship to experiment with Kustomize
The Replicated Ship CLI has been installed on our clusters
Replicated Ship has multiple workflows; here is what we will do:
initialize a Kustomize overlay from a remote GitHub repository
customize some values using the web UI provided by Ship
look at the resulting files and apply them to the cluster
Getting started with Ship
We need to run
ship initin a new directoryship initrequires a URL to a remote repository containing Kubernetes YAMLIt will clone that repository and start a web UI
Later, it can watch that repository and/or update from it
We will use the jpetazzo/kubercoins repository
(it contains all the DockerCoins resources as YAML files)
ship init
Change to a new directory:
mkdir ~/kustomcoinscd ~/kustomcoinsRun
ship initwith the kustomcoins repository:ship init https://github.com/jpetazzo/kubercoins
Access the web UI
ship inittells us to connect onlocalhost:8800We need to replace
localhostwith the address of our node(since we run on a remote machine)
Follow the steps in the web UI, and change one parameter
(e.g. set the number of replicas in the worker Deployment)
Complete the web workflow, and go back to the CLI
Inspect the results
Look at the content of our directory
basecontains the kubercoins repository + akustomization.yamlfileoverlays/shipcontains the Kustomize overlay referencing the base + our patch(es)rendered.yamlis a YAML bundle containing the patched application.shipcontains a state file used by Ship
Using the results
We can
kubectl apply -f rendered.yaml(on any version of Kubernetes)
Starting with Kubernetes 1.14, we can apply the overlay directly with:
kubectl apply -k overlays/shipBut let's not do that for now!
We will create a new copy of DockerCoins in another namespace
Deploy DockerCoins with Kustomize
Create a new namespace:
kubectl create namespace kustomcoinsDeploy DockerCoins:
kubectl apply -f rendered.yaml --namespace=kustomcoinsOr, with Kubernetes 1.14, you can also do this:
kubectl apply -k overlays/ship --namespace=kustomcoins
Checking our new copy of DockerCoins
- We can check the worker logs, or the web UI
Retrieve the NodePort number of the web UI:
kubectl get service webui --namespace=kustomcoinsOpen it in a web browser
Look at the worker logs:
kubectl logs deploy/worker --tail=10 --follow --namespace=kustomcoins
Note: it might take a minute or two for the worker to start.
Managing stacks with Helm
(automatically generated title slide)
Managing stacks with Helm
We created our first resources with
kubectl run,kubectl expose...We have also created resources by loading YAML files with
kubectl apply -fFor larger stacks, managing thousands of lines of YAML is unreasonable
These YAML bundles need to be customized with variable parameters
(E.g.: number of replicas, image version to use ...)
It would be nice to have an organized, versioned collection of bundles
It would be nice to be able to upgrade/rollback these bundles carefully
Helm is an open source project offering all these things!
Helm concepts
helmis a CLI toolIt is used to find, install, upgrade charts
A chart is an archive containing templatized YAML bundles
Charts are versioned
Charts can be stored on private or public repositories
Differences between charts and packages
A package (deb, rpm...) contains binaries, libraries, etc.
A chart contains YAML manifests
(the binaries, libraries, etc. are in the images referenced by the chart)
On most distributions, a package can only be installed once
(installing another version replaces the installed one)
A chart can be installed multiple times
Each installation is called a release
This allows to install e.g. 10 instances of MongoDB
(with potentially different versions and configurations)
Wait a minute ...
But, on my Debian system, I have Python 2 and Python 3.
Also, I have multiple versions of the Postgres database engine!
Yes!
But they have different package names:
python2.7,python3.8postgresql-10,postgresql-11
Good to know: the Postgres package in Debian includes
provisions to deploy multiple Postgres servers on the
same system, but it's an exception (and it's a lot of
work done by the package maintainer, not by the dpkg
or apt tools).
Helm 2 vs Helm 3
Helm 3 was released November 13, 2019
Charts remain compatible between Helm 2 and Helm 3
The CLI is very similar (with minor changes to some commands)
The main difference is that Helm 2 uses
tiller, a server-side componentHelm 3 doesn't use
tillerat all, making it simpler (yay!)
With or without tiller
With Helm 3:
the
helmCLI communicates directly with the Kubernetes APIit creates resources (deployments, services...) with our credentials
With Helm 2:
the
helmCLI communicates withtiller, tellingtillerwhat to dotillerthen communicates with the Kubernetes API, using its own credentials
This indirect model caused significant permissions headaches
(
tillerrequired very broad permissions to function)tillerwas removed in Helm 3 to simplify the security aspects
Installing Helm
- If the
helmCLI is not installed in your environment, install it
Check if
helmis installed:helmIf it's not installed, run the following command:
curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get-helm-3 \| bash
(To install Helm 2, replace get-helm-3 with get.)
Only if using Helm 2 ...
We need to install Tiller and give it some permissions
Tiller is composed of a service and a deployment in the
kube-systemnamespaceThey can be managed (installed, upgraded...) with the
helmCLI
- Deploy Tiller:helm init
At the end of the install process, you will see:
Happy Helming!Only if using Helm 2 ...
Tiller needs permissions to create Kubernetes resources
In a more realistic deployment, you might create per-user or per-team service accounts, roles, and role bindings
- Grant
cluster-adminrole tokube-system:defaultservice account:kubectl create clusterrolebinding add-on-cluster-admin \--clusterrole=cluster-admin --serviceaccount=kube-system:default
(Defining the exact roles and permissions on your cluster requires a deeper knowledge of Kubernetes' RBAC model. The command above is fine for personal and development clusters.)
Charts and repositories
A repository (or repo in short) is a collection of charts
It's just a bunch of files
(they can be hosted by a static HTTP server, or on a local directory)
We can add "repos" to Helm, giving them a nickname
The nickname is used when referring to charts on that repo
(for instance, if we try to install
hello/world, that means the chartworldon the repohello; and that repohellomight be something like https://blahblah.hello.io/charts/)
Managing repositories
Let's check what repositories we have, and add the
stablerepo(the
stablerepo contains a set of official-ish charts)
List our repos:
helm repo listAdd the
stablerepo:helm repo add stable https://kubernetes-charts.storage.googleapis.com/
Adding a repo can take a few seconds (it downloads the list of charts from the repo).
It's OK to add a repo that already exists (it will merely update it).
Search available charts
We can search available charts with
helm searchWe need to specify where to search (only our repos, or Helm Hub)
Let's search for all charts mentioning tomcat!
Search for tomcat in the repo that we added earlier:
helm search repo tomcatSearch for tomcat on the Helm Hub:
helm search hub tomcat
Helm Hub indexes many repos, using the Monocular server.
Charts and releases
"Installing a chart" means creating a release
We need to name that release
(or use the
--generate-nameto get Helm to generate one for us)
Install the tomcat chart that we found earlier:
helm install java4ever stable/tomcatList the releases:
helm list
Searching and installing with Helm 2
Helm 2 doesn't have support for the Helm Hub
The
helm searchcommand only takes a search string argument(e.g.
helm search tomcat)With Helm 2, the name is optional:
helm install stable/tomcatwill automatically generate a namehelm install --name java4ever stable/tomcatwill specify a name
Viewing resources of a release
This specific chart labels all its resources with a
releaselabelWe can use a selector to see these resources
- List all the resources created by this release:kubectl get all --selector=release=java4ever
Note: this release label wasn't added automatically by Helm.
It is defined in that chart. In other words, not all charts will provide this label.
Configuring a release
By default,
stable/tomcatcreates a service of typeLoadBalancerWe would like to change that to a
NodePortWe could use
kubectl edit service java4ever-tomcat, but ...... our changes would get overwritten next time we update that chart!
Instead, we are going to set a value
Values are parameters that the chart can use to change its behavior
Values have default values
Each chart is free to define its own values and their defaults
Checking possible values
- We can inspect a chart with
helm showorhelm inspect
Look at the README for tomcat:
helm show readme stable/tomcatLook at the values and their defaults:
helm show values stable/tomcat
The values may or may not have useful comments.
The readme may or may not have (accurate) explanations for the values.
(If we're unlucky, there won't be any indication about how to use the values!)
Setting values
Values can be set when installing a chart, or when upgrading it
We are going to update
java4everto change the type of the service
- Update
java4ever:helm upgrade java4ever stable/tomcat --set service.type=NodePort
Note that we have to specify the chart that we use (stable/tomcat),
even if we just want to update some values.
We can set multiple values. If we want to set many values, we can use -f/--values and pass a YAML file with all the values.
All unspecified values will take the default values defined in the chart.
Connecting to tomcat
Let's check the tomcat server that we just installed
Note: its readiness probe has a 60s delay
(so it will take 60s after the initial deployment before the service works)
Check the node port allocated to the service:
kubectl get service java4ever-tomcatPORT=$(kubectl get service java4ever-tomcat -o jsonpath={..nodePort})Connect to it, checking the demo app on
/sample/:curl localhost:$PORT/sample/
Helm chart format
(automatically generated title slide)
Helm chart format
What exactly is a chart?
What's in it?
What would be involved in creating a chart?
(we won't create a chart, but we'll see the required steps)
What is a chart
A chart is a set of files
Some of these files are mandatory for the chart to be viable
(more on that later)
These files are typically packed in a tarball
These tarballs are stored in "repos"
(which can be static HTTP servers)
We can install from a repo, from a local tarball, or an unpacked tarball
(the latter option is preferred when developing a chart)
What's in a chart
A chart must have at least:
a
templatesdirectory, with YAML manifests for Kubernetes resourcesa
values.yamlfile, containing (tunable) parameters for the charta
Chart.yamlfile, containing metadata (name, version, description ...)
Let's look at a simple chart,
stable/tomcat
Downloading a chart
- We can use
helm pullto download a chart from a repo
Download the tarball for
stable/tomcat:helm pull stable/tomcat(This will create a file named
tomcat-X.Y.Z.tgz.)Or, download + untar
stable/tomcat:helm pull stable/tomcat --untar(This will create a directory named
tomcat.)
Looking at the chart's content
- Let's look at the files and directories in the
tomcatchart
- Display the tree structure of the chart we just downloaded:tree tomcat
We see the components mentioned above: Chart.yaml, templates/, values.yaml.
Templates
The
templates/directory contains YAML manifests for Kubernetes resources(Deployments, Services, etc.)
These manifests can contain template tags
(using the standard Go template library)
- Look at the template file for the tomcat Service resource:cat tomcat/templates/appsrv-svc.yaml
Analyzing the template file
Tags are identified by
{{ ... }}{{ template "x.y" }}expands a named template(previously defined with
{{ define "x.y "}}...stuff...{{ end }})The
.in{{ template "x.y" . }}is the context for that named template(so that the named template block can access variables from the local context)
{{ .Release.xyz }}refers to built-in variables initialized by Helm(indicating the chart name, version, whether we are installing or upgrading ...)
{{ .Values.xyz }}refers to tunable/settable values(more on that in a minute)
Values
Each chart comes with a values file
It's a YAML file containing a set of default parameters for the chart
The values can be accessed in templates with e.g.
{{ .Values.x.y }}(corresponding to field
yin mapxin the values file)The values can be set or overridden when installing or ugprading a chart:
with
--set x.y=z(can be used multiple times to set multiple values)with
--values some-yaml-file.yaml(set a bunch of values from a file)
Charts following best practices will have values following specific patterns
(e.g. having a
servicemap allowing to setservice.typeetc.)
Other useful tags
{{ if x }} y {{ end }}allows to includeyifxevaluates totrue(can be used for e.g. healthchecks, annotations, or even an entire resource)
{{ range x }} y {{ end }}iterates overx, evaluatingyeach time(the elements of
xare assigned to.in the range scope){{- x }}/{{ x -}}will remove whitespace on the left/rightThe whole Sprig library, with additions:
lowerupperquotetrimdefaultb64encb64decsha256sumindenttoYaml...
Pipelines
{{ quote blah }}can also be expressed as{{ blah | quote }}With multiple arguments,
{{ x y z }}can be expressed as{{ z | x y }})Example:
{{ .Values.annotations | toYaml | indent 4 }}transforms the map under
annotationsinto a YAML stringindents it with 4 spaces (to match the surrounding context)
Pipelines are not specific to Helm, but a feature of Go templates
(check the Go text/template documentation for more details and examples)
README and NOTES.txt
At the top-level of the chart, it's a good idea to have a README
It will be viewable with e.g.
helm show readme stable/tomcatIn the
templates/directory, we can also have aNOTES.txtfileWhen the template is installed (or upgraded),
NOTES.txtis processed too(i.e. its
{{ ... }}tags are evaluated)It gets displayed after the install or upgrade
It's a great place to generate messages to tell the user:
how to connect to the release they just deployed
any passwords or other thing that we generated for them
Additional files
We can place arbitrary files in the chart (outside of the
templates/directory)They can be accessed in templates with
.FilesThey can be transformed into ConfigMaps or Secrets with
AsConfigandAsSecrets(see this example in the Helm docs)
Hooks and tests
We can define hooks in our templates
Hooks are resources annotated with
"helm.sh/hook": NAME-OF-HOOKHook names include
pre-install,post-install,test, and much moreThe resources defined in hooks are loaded at a specific time
Hook execution is synchronous
(if the resource is a Job or Pod, Helm will wait for its completion)
This can be use for database migrations, backups, notifications, smoke tests ...
Hooks named
testare executed only when runninghelm test RELEASE-NAME
Creating a basic chart
(automatically generated title slide)
Creating a basic chart
We are going to show a way to create a very simplified chart
In a real chart, lots of things would be templatized
(Resource names, service types, number of replicas...)
Create a sample chart:
helm create dockercoinsMove away the sample templates and create an empty template directory:
mv dockercoins/templates dockercoins/default-templatesmkdir dockercoins/templates
k8s/helm-create-basic-chart.md
Exporting the YAML for our application
The following section assumes that DockerCoins is currently running
If DockerCoins is not running, see next slide
- Create one YAML file for each resource that we need:while read kind name; dokubectl get -o yaml $kind $name > dockercoins/templates/$name-$kind.yamldone <<EOFdeployment workerdeployment hasherdaemonset rngdeployment webuideployment redisservice hasherservice rngservice webuiservice redisEOF
k8s/helm-create-basic-chart.md
Obtaining DockerCoins YAML
- If DockerCoins is not running, we can also obtain the YAML from a public repository
Clone the kubercoins repository:
git clone https://github.com/jpetazzo/kubercoinsCopy the YAML files to the
templates/directory:cp kubercoins/*.yaml dockercoins/templates/
k8s/helm-create-basic-chart.md
Testing our helm chart
- Let's install our helm chart!
(helm install helmcoins dockercoinshelmcoinsis the name of the release;dockercoinsis the local path of the chart)
Testing our helm chart
- Let's install our helm chart!
(helm install helmcoins dockercoinshelmcoinsis the name of the release;dockercoinsis the local path of the chart)
Since the application is already deployed, this will fail:
Error: rendered manifests contain a resource that already exists.Unable to continue with install: existing resource conflict:kind: Service, namespace: default, name: hasherTo avoid naming conflicts, we will deploy the application in another namespace
k8s/helm-create-basic-chart.md
Switching to another namespace
We need create a new namespace
(Helm 2 creates namespaces automatically; Helm 3 doesn't anymore)
We need to tell Helm which namespace to use
Create a new namespace:
kubectl create namespace helmcoinsDeploy our chart in that namespace:
helm install helmcoins dockercoins --namespace=helmcoins
k8s/helm-create-basic-chart.md
Helm releases are namespaced
- Let's try to see the release that we just deployed
- List Helm releases:helm list
Our release doesn't show up!
We have to specify its namespace (or switch to that namespace).
k8s/helm-create-basic-chart.md
Specifying the namespace
- Try again, with the correct namespace
- List Helm releases in
helmcoins:helm list --namespace=helmcoins
k8s/helm-create-basic-chart.md
Checking our new copy of DockerCoins
- We can check the worker logs, or the web UI
Retrieve the NodePort number of the web UI:
kubectl get service webui --namespace=helmcoinsOpen it in a web browser
Look at the worker logs:
kubectl logs deploy/worker --tail=10 --follow --namespace=helmcoins
Note: it might take a minute or two for the worker to start.
k8s/helm-create-basic-chart.md
Discussion, shortcomings
Helm (and Kubernetes) best practices recommend to add a number of annotations
(e.g.
app.kubernetes.io/name,helm.sh/chart,app.kubernetes.io/instance...)Our basic chart doesn't have any of these
Our basic chart doesn't use any template tag
Does it make sense to use Helm in that case?
Yes, because Helm will:
track the resources created by the chart
save successive revisions, allowing us to rollback
Helm docs and Kubernetes docs have details about recommended annotations and labels.
k8s/helm-create-basic-chart.md
Cleaning up
- Let's remove that chart before moving on
- Delete the release (don't forget to specify the namespace):helm delete helmcoins --namespace=helmcoins
k8s/helm-create-basic-chart.md
Creating better Helm charts
(automatically generated title slide)
Creating better Helm charts
We are going to create a chart with the helper
helm createThis will give us a chart implementing lots of Helm best practices
(labels, annotations, structure of the
values.yamlfile ...)We will use that chart as a generic Helm chart
We will use it to deploy DockerCoins
Each component of DockerCoins will have its own release
In other words, we will "install" that Helm chart multiple times
(one time per component of DockerCoins)
k8s/helm-create-better-chart.md
Creating a generic chart
Rather than starting from scratch, we will use
helm createThis will give us a basic chart that we will customize
- Create a basic chart:cd ~helm create helmcoins
This creates a basic chart in the directory helmcoins.
k8s/helm-create-better-chart.md
What's in the basic chart?
The basic chart will create a Deployment and a Service
Optionally, it will also include an Ingress
If we don't pass any values, it will deploy the
nginximageWe can override many things in that chart
Let's try to deploy DockerCoins components with that chart!
k8s/helm-create-better-chart.md
Writing values.yaml for our components
We need to write one
values.yamlfile for each component(hasher, redis, rng, webui, worker)
We will start with the
values.yamlof the chart, and remove what we don't needWe will create 5 files:
hasher.yaml, redis.yaml, rng.yaml, webui.yaml, worker.yaml
In each file, we want to have:
image:repository: IMAGE-REPOSITORY-NAMEtag: IMAGE-TAG
k8s/helm-create-better-chart.md
Getting started
For component X, we want to use the image dockercoins/X:v0.1
(for instance, for rng, we want to use the image dockercoins/rng:v0.1)
Exception: for redis, we want to use the official image redis:latest
- Write YAML files for the 5 components, with the following model:image:repository: IMAGE-REPOSITORY-NAME (e.g. dockercoins/worker)tag: IMAGE-TAG (e.g. v0.1)
k8s/helm-create-better-chart.md
Deploying DockerCoins components
- For convenience, let's work in a separate namespace
Create a new namespace (if it doesn't already exist):
kubectl create namespace helmcoinsSwitch to that namespace:
kns helmcoins
k8s/helm-create-better-chart.md
Deploying the chart
To install a chart, we can use the following command:
helm install COMPONENT-NAME CHART-DIRECTORYWe can also use the following command, which is idempotent:
helm upgrade COMPONENT-NAME CHART-DIRECTORY --install
- Install the 5 components of DockerCoins:for COMPONENT in hasher redis rng webui worker; dohelm upgrade $COMPONENT helmcoins --install --values=$COMPONENT.yamldone
k8s/helm-create-better-chart.md
Checking what we've done
- Let's see if DockerCoins is working!
Check the logs of the worker:
stern workerLook at the resources that were created:
kubectl get all
There are many issues to fix!
k8s/helm-create-better-chart.md
Can't pull image
- It looks like our images can't be found
- Use
kubectl describeon any of the pods in error
We're trying to pull
rng:1.16.0instead ofrng:v0.1!Where does that
1.16.0tag come from?
k8s/helm-create-better-chart.md
Inspecting our template
Let's look at the
templates/directory(and try to find the one generating the Deployment resource)
Show the structure of the
helmcoinschart that Helm generated:tree helmcoinsCheck the file
helmcoins/templates/deployment.yamlLook for the
image:parameter
The image tag references {{ .Chart.AppVersion }}. Where does that come from?
k8s/helm-create-better-chart.md
The .Chart variable
.Chartis a map corresponding to the values inChart.yamlLet's look for
AppVersionthere!
Check the file
helmcoins/Chart.yamlLook for the
appVersion:parameter
(Yes, the case is different between the template and the Chart file.)
k8s/helm-create-better-chart.md
Using the correct tags
If we change
AppVersiontov0.1, it will change for all deployments(including redis)
Instead, let's change the template to use
{{ .Values.image.tag }}(to match what we've specified in our values YAML files)
Edit
helmcoins/templates/deployment.yamlReplace
{{ .Chart.AppVersion }}with{{ .Values.image.tag }}
k8s/helm-create-better-chart.md
Upgrading to use the new template
Technically, we just made a new version of the chart
To use the new template, we need to upgrade the release to use that chart
Upgrade all components:
for COMPONENT in hasher redis rng webui worker; dohelm upgrade $COMPONENT helmcoinsdoneCheck how our pods are doing:
kubectl get pods
We should see all pods "Running". But ... not all of them are READY.
k8s/helm-create-better-chart.md
Troubleshooting readiness
hasher,rng,webuishould show up as1/1 READYBut
redisandworkershould show up as0/1 READYWhy?
k8s/helm-create-better-chart.md
Troubleshooting pods
The easiest way to troubleshoot pods is to look at events
We can look at all the events on the cluster (with
kubectl get events)Or we can use
kubectl describeon the objects that have problems(
kubectl describewill retrieve the events related to the object)
- Check the events for the redis pods:kubectl describe pod -l app.kubernetes.io/name=redis
It's failing both its liveness and readiness probes!
k8s/helm-create-better-chart.md
Healthchecks
The default chart defines healthchecks doing HTTP requests on port 80
That won't work for redis and worker
(redis is not HTTP, and not on port 80; worker doesn't even listen)
Healthchecks
The default chart defines healthchecks doing HTTP requests on port 80
That won't work for redis and worker
(redis is not HTTP, and not on port 80; worker doesn't even listen)
We could remove or comment out the healthchecks
We could also make them conditional
This sounds more interesting, let's do that!
k8s/helm-create-better-chart.md
Conditionals
We need to enclose the healthcheck block with:
{{ if false }}at the beginning (we can change the condition later){{ end }}at the end
Edit
helmcoins/templates/deployment.yamlAdd
{{ if false }}on the line beforelivenessProbeAdd
{{ end }}after thereadinessProbesection(see next slide for details)
k8s/helm-create-better-chart.md
This is what the new YAML should look like (added lines in yellow):
ports: - name: http containerPort: 80 protocol: TCP {{ if false }} livenessProbe: httpGet: path: / port: http readinessProbe: httpGet: path: / port: http {{ end }} resources: {{- toYaml .Values.resources | nindent 12 }}k8s/helm-create-better-chart.md
Testing the new chart
- We need to upgrade all the services again to use the new chart
Upgrade all components:
for COMPONENT in hasher redis rng webui worker; dohelm upgrade $COMPONENT helmcoinsdoneCheck how our pods are doing:
kubectl get pods
Everything should now be running!
k8s/helm-create-better-chart.md
What's next?
- Is this working now?
- Let's check the logs of the worker:stern worker
This error might look familiar ... The worker can't resolve redis.
Typically, that error means that the redis service doesn't exist.
k8s/helm-create-better-chart.md
Checking services
- What about the services created by our chart?
- Check the list of services:kubectl get services
They are named COMPONENT-helmcoins instead of just COMPONENT.
We need to change that!
k8s/helm-create-better-chart.md
Where do the service names come from?
Look at the YAML template used for the services
It should be using
{{ include "helmcoins.fullname" }}includeindicates a template block defined somewhere else
- Find where that
fullnamething is defined:grep define.*fullname helmcoins/templates/*
It should be in _helpers.tpl.
We can look at the definition, but it's fairly complex ...
k8s/helm-create-better-chart.md
Changing service names
Instead of that
{{ include }}tag, let's use the name of the releaseThe name of the release is available as
{{ .Release.Name }}
Edit
helmcoins/templates/service.yamlReplace the service name with
{{ .Release.Name }}Upgrade all the releases to use the new chart
Confirm that the services now have the right names
k8s/helm-create-better-chart.md
Is it working now?
If we look at the worker logs, it appears that the worker is still stuck
What could be happening?
Is it working now?
If we look at the worker logs, it appears that the worker is still stuck
What could be happening?
The redis service is not on port 80!
Let's see how the port number is set
We need to look at both the deployment template and the service template
k8s/helm-create-better-chart.md
Service template
In the service template, we have the following section:
ports:- port: {{ .Values.service.port }}targetPort: httpprotocol: TCPname: httpportis the port on which the service is "listening"(i.e. to which our code needs to connect)
targetPortis the port on which the pods are listeningThe
nameis not important (it's OK if it'shttpeven for non-HTTP traffic)
k8s/helm-create-better-chart.md
Setting the redis port
- Let's add a
service.portvalue to the redis release
Edit
redis.yamlto add:service:port: 6379Apply the new values file:
helm upgrade redis helmcoins --values=redis.yaml
k8s/helm-create-better-chart.md
Deployment template
If we look at the deployment template, we see this section:
ports:- name: httpcontainerPort: 80protocol: TCPThe container port is hard-coded to 80
We'll change it to use the port number specified in the values
k8s/helm-create-better-chart.md
Changing the deployment template
Edit
helmcoins/templates/deployment.yamlThe line with
containerPortshould be:containerPort: {{ .Values.service.port }}
k8s/helm-create-better-chart.md
Apply changes
Re-run the for loop to execute
helm upgradeone more timeCheck the worker logs
This time, it should be working!
k8s/helm-create-better-chart.md
Extra steps
We don't need to create a service for the worker
We can put the whole service block in a conditional
(this will require additional changes in other files referencing the service)
We can set the webui to be a NodePort service
We can change the number of workers with
replicaCountAnd much more!
k8s/helm-create-better-chart.md
Helm secrets
(automatically generated title slide)
Helm secrets
Helm can do rollbacks:
to previously installed charts
to previous sets of values
How and where does it store the data needed to do that?
Let's investigate!
We need a release
We need to install something with Helm
Let's use the
stable/tomcatchart as an example
Install a release called
tomcatwith the chartstable/tomcat:helm upgrade tomcat stable/tomcat --installLet's upgrade that release, and change a value:
helm upgrade tomcat stable/tomcat --set ingress.enabled=true
Release history
- Helm stores successive revisions of each release
- View the history for that release:helm history tomcat
Where does that come from?
Investigate
Possible options:
local filesystem (no, because history is visible from other machines)
persistent volumes (no, Helm works even without them)
ConfigMaps, Secrets?
- Look for ConfigMaps and Secrets:kubectl get configmaps,secrets
Investigate
Possible options:
local filesystem (no, because history is visible from other machines)
persistent volumes (no, Helm works even without them)
ConfigMaps, Secrets?
- Look for ConfigMaps and Secrets:kubectl get configmaps,secrets
We should see a number of secrets with TYPE helm.sh/release.v1.
Unpacking a secret
- Let's find out what is in these Helm secrets
- Examine the secret corresponding to the second release of
tomcat:
(kubectl describe secret sh.helm.release.v1.tomcat.v2v1is the secret format;v2means revision 2 of thetomcatrelease)
There is a key named release.
Unpacking the release data
- Let's see what's in this
releasething!
- Dump the secret:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release }}'
Secrets are encoded in base64. We need to decode that!
Decoding base64
- We can pipe the output through
base64 -dor use go-template'sbase64decode
- Decode the secret:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode }}'
Decoding base64
- We can pipe the output through
base64 -dor use go-template'sbase64decode
- Decode the secret:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode }}'
... Wait, this still looks like base64. What's going on?
Decoding base64
- We can pipe the output through
base64 -dor use go-template'sbase64decode
- Decode the secret:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode }}'
... Wait, this still looks like base64. What's going on?
Let's try one more round of decoding!
Decoding harder
- Just add one more base64 decode filter
- Decode it twice:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode | base64decode }}'
Decoding harder
- Just add one more base64 decode filter
- Decode it twice:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode | base64decode }}'
... OK, that was a lot of binary data. What sould we do with it?
Guessing data type
- We could use
fileto figure out the data type
- Pipe the decoded release through
file -:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode | base64decode }}' \| file -
Guessing data type
- We could use
fileto figure out the data type
- Pipe the decoded release through
file -:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode | base64decode }}' \| file -
Gzipped data! It can be decoded with gunzip -c.
Uncompressing the data
- Let's uncompress the data and save it to a file
Rerun the previous command, but with
| gunzip -c > release-info:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode | base64decode }}' \| gunzip -c > release-infoLook at
release-info:cat release-info
Uncompressing the data
- Let's uncompress the data and save it to a file
Rerun the previous command, but with
| gunzip -c > release-info:kubectl get secret sh.helm.release.v1.tomcat.v2 \-o go-template='{{ .data.release | base64decode | base64decode }}' \| gunzip -c > release-infoLook at
release-info:cat release-info
It's a bundle of YAML JSON.
Looking at the JSON
If we inspect that JSON (e.g. with jq keys release-info), we see:
chart(contains the entire chart used for that release)config(contains the values that we've set)info(date of deployment, status messages)manifest(YAML generated from the templates)name(name of the release, sotomcat)namespace(namespace where we deployed the release)version(revision number within that release; starts at 1)
The chart is in a structured format, but it's entirely captured in this JSON.
Conclusions
Helm stores each release information in a Secret in the namespace of the release
The secret is JSON object (gzipped and encoded in base64)
It contains the manifests generated for that release
... And everything needed to rebuild these manifests
(including the full source of the chart, and the values used)
This allows arbitrary rollbacks, as well as tweaking values even without having access to the source of the chart (or the chart repo) used for deployment
Extending the Kubernetes API
(automatically generated title slide)
Extending the Kubernetes API
There are multiple ways to extend the Kubernetes API.
We are going to cover:
Custom Resource Definitions (CRDs)
Admission Webhooks
The Aggregation Layer
Revisiting the API server
The Kubernetes API server is a central point of the control plane
(everything connects to it: controller manager, scheduler, kubelets)
Almost everything in Kubernetes is materialized by a resource
Resources have a type (or "kind")
(similar to strongly typed languages)
We can see existing types with
kubectl api-resourcesWe can list resources of a given type with
kubectl get <type>
Creating new types
We can create new types with Custom Resource Definitions (CRDs)
CRDs are created dynamically
(without recompiling or restarting the API server)
CRDs themselves are resources:
we can create a new type with
kubectl createand some YAMLwe can see all our custom types with
kubectl get crds
After we create a CRD, the new type works just like built-in types
A very simple CRD
The YAML below describes a very simple CRD representing different kinds of coffee:
apiVersion: apiextensions.k8s.io/v1alpha1kind: CustomResourceDefinitionmetadata: name: coffees.container.trainingspec: group: container.training version: v1alpha1 scope: Namespaced names: plural: coffees singular: coffee kind: Coffee shortNames: - cofCreating a CRD
- Let's create the Custom Resource Definition for our Coffee resource
Load the CRD:
kubectl apply -f ~/container.training/k8s/coffee-1.yamlConfirm that it shows up:
kubectl get crds
Creating custom resources
The YAML below defines a resource using the CRD that we just created:
kind: CoffeeapiVersion: container.training/v1alpha1metadata: name: arabicaspec: taste: strong- Create a few types of coffee beans:kubectl apply -f ~/container.training/k8s/coffees.yaml
Viewing custom resources
- By default,
kubectl getonly shows name and age of custom resources
- View the coffee beans that we just created:kubectl get coffees
- We can improve that, but it's outside the scope of this section!
What can we do with CRDs?
There are many possibilities!
Operators encapsulate complex sets of resources
(e.g.: a PostgreSQL replicated cluster; an etcd cluster...
see awesome operators and OperatorHub to find more)Custom use-cases like gitkube
creates a new custom type,
Remote, exposing a git+ssh serverdeploy by pushing YAML or Helm charts to that remote
Replacing built-in types with CRDs
Little details
By default, CRDs are not validated
(we can put anything we want in the
spec)When creating a CRD, we can pass an OpenAPI v3 schema (BETA!)
(which will then be used to validate resources)
Generally, when creating a CRD, we also want to run a controller
(otherwise nothing will happen when we create resources of that type)
The controller will typically watch our custom resources
(and take action when they are created/updated)
Examples: YAML to install the gitkube CRD, YAML to install a redis operator CRD
(Ab)using the API server
If we need to store something "safely" (as in: in etcd), we can use CRDs
This gives us primitives to read/write/list objects (and optionally validate them)
The Kubernetes API server can run on its own
(without the scheduler, controller manager, and kubelets)
By loading CRDs, we can have it manage totally different objects
(unrelated to containers, clusters, etc.)
Service catalog
Service catalog is another extension mechanism
It's not extending the Kubernetes API strictly speaking
(but it still provides new features!)
It doesn't create new types; it uses:
- ClusterServiceBroker
- ClusterServiceClass
- ClusterServicePlan
- ServiceInstance
- ServiceBinding
It uses the Open service broker API
Admission controllers
Admission controllers are another way to extend the Kubernetes API
Instead of creating new types, admission controllers can transform or vet API requests
The diagram on the next slide shows the path of an API request
(courtesy of Banzai Cloud)
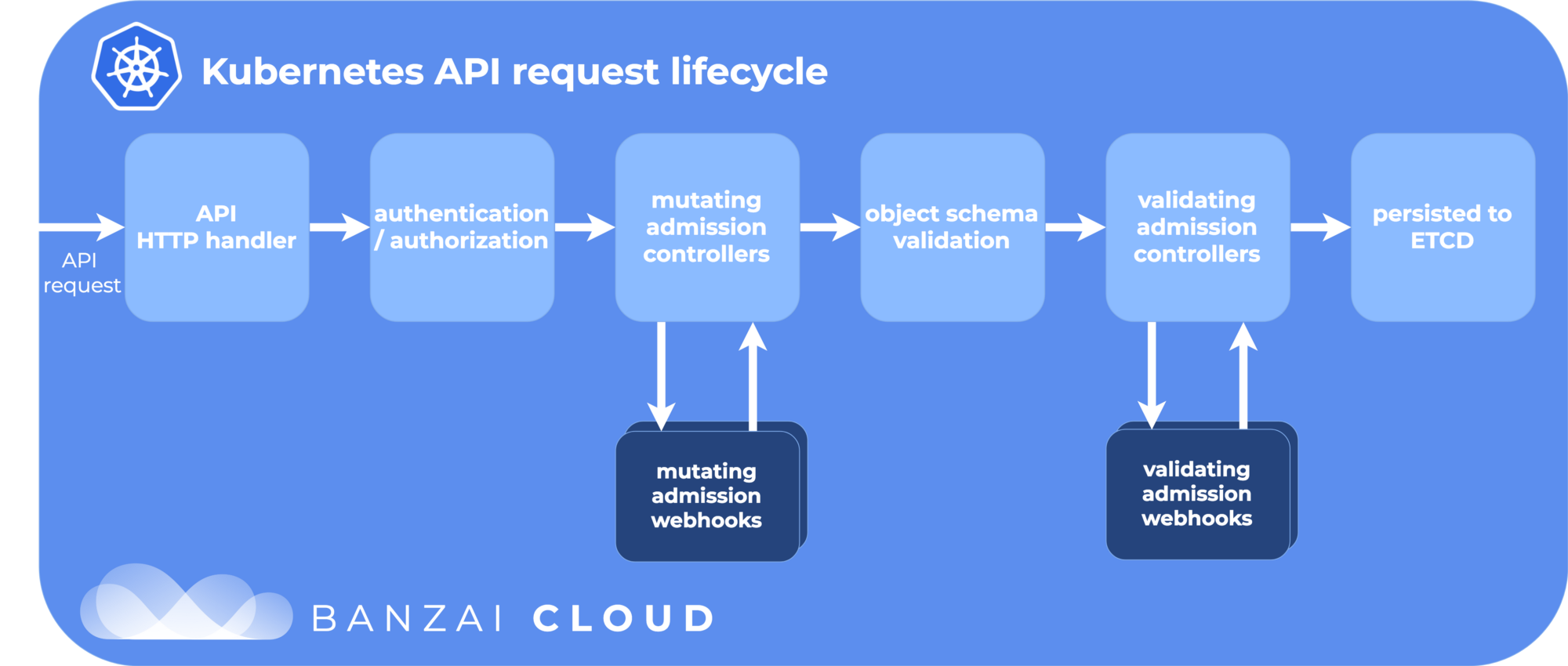
Types of admission controllers
Validating admission controllers can accept/reject the API call
Mutating admission controllers can modify the API request payload
Both types can also trigger additional actions
(e.g. automatically create a Namespace if it doesn't exist)
There are a number of built-in admission controllers
(see documentation for a list)
We can also dynamically define and register our own
Some built-in admission controllers
ServiceAccount:
automatically adds a ServiceAccount to Pods that don't explicitly specify one
LimitRanger:
applies resource constraints specified by LimitRange objects when Pods are created
NamespaceAutoProvision:
automatically creates namespaces when an object is created in a non-existent namespace
Note: #1 and #2 are enabled by default; #3 is not.
Admission Webhooks
We can setup admission webhooks to extend the behavior of the API server
The API server will submit incoming API requests to these webhooks
These webhooks can be validating or mutating
Webhooks can be set up dynamically (without restarting the API server)
To setup a dynamic admission webhook, we create a special resource:
a
ValidatingWebhookConfigurationor aMutatingWebhookConfigurationThese resources are created and managed like other resources
(i.e.
kubectl create,kubectl get...)
Webhook Configuration
A ValidatingWebhookConfiguration or MutatingWebhookConfiguration contains:
the address of the webhook
the authentication information to use with the webhook
a list of rules
The rules indicate for which objects and actions the webhook is triggered
(to avoid e.g. triggering webhooks when setting up webhooks)
The aggregation layer
We can delegate entire parts of the Kubernetes API to external servers
This is done by creating APIService resources
(check them with
kubectl get apiservices!)The APIService resource maps a type (kind) and version to an external service
All requests concerning that type are sent (proxied) to the external service
This allows to have resources like CRDs, but that aren't stored in etcd
Example:
metrics-server(storing live metrics in etcd would be extremely inefficient)
Requires significantly more work than CRDs!
Operators
(automatically generated title slide)
Operators
Operators are one of the many ways to extend Kubernetes
We will define operators
We will see how they work
We will install a specific operator (for ElasticSearch)
We will use it to provision an ElasticSearch cluster
What are operators?
An operator represents human operational knowledge in software,
to reliably manage an application.
— CoreOS
Examples:
Deploying and configuring replication with MySQL, PostgreSQL ...
Setting up Elasticsearch, Kafka, RabbitMQ, Zookeeper ...
Reacting to failures when intervention is needed
Scaling up and down these systems
What are they made from?
Operators combine two things:
Custom Resource Definitions
controller code watching the corresponding resources and acting upon them
A given operator can define one or multiple CRDs
The controller code (control loop) typically runs within the cluster
(running as a Deployment with 1 replica is a common scenario)
But it could also run elsewhere
(nothing mandates that the code run on the cluster, as long as it has API access)
Why use operators?
Kubernetes gives us Deployments, StatefulSets, Services ...
These mechanisms give us building blocks to deploy applications
They work great for services that are made of N identical containers
(like stateless ones)
They also work great for some stateful applications like Consul, etcd ...
(with the help of highly persistent volumes)
They're not enough for complex services:
where different containers have different roles
where extra steps have to be taken when scaling or replacing containers
Use-cases for operators
Systems with primary/secondary replication
Examples: MariaDB, MySQL, PostgreSQL, Redis ...
Systems where different groups of nodes have different roles
Examples: ElasticSearch, MongoDB ...
Systems with complex dependencies (that are themselves managed with operators)
Examples: Flink or Kafka, which both depend on Zookeeper
More use-cases
Representing and managing external resources
(Example: AWS Service Operator)
Managing complex cluster add-ons
(Example: Istio operator)
Deploying and managing our applications' lifecycles
(more on that later)
How operators work
An operator creates one or more CRDs
(i.e., it creates new "Kinds" of resources on our cluster)
The operator also runs a controller that will watch its resources
Each time we create/update/delete a resource, the controller is notified
(we could write our own cheap controller with
kubectl get --watch)
One operator in action
We will install Elastic Cloud on Kubernetes, an ElasticSearch operator
This operator requires PersistentVolumes
We will install Rancher's local path storage provisioner to automatically create these
Then, we will create an ElasticSearch resource
The operator will detect that resource and provision the cluster
Installing a Persistent Volume provisioner
(This step can be skipped if you already have a dynamic volume provisioner.)
This provisioner creates Persistent Volumes backed by
hostPath(local directories on our nodes)
It doesn't require anything special ...
... But losing a node = losing the volumes on that node!
- Install the local path storage provisioner:kubectl apply -f ~/container.training/k8s/local-path-storage.yaml
Making sure we have a default StorageClass
The ElasticSearch operator will create StatefulSets
These StatefulSets will instantiate PersistentVolumeClaims
These PVCs need to be explicitly associated with a StorageClass
Or we need to tag a StorageClass to be used as the default one
- List StorageClasses:kubectl get storageclasses
We should see the local-path StorageClass.
Setting a default StorageClass
This is done by adding an annotation to the StorageClass:
storageclass.kubernetes.io/is-default-class: true
Tag the StorageClass so that it's the default one:
kubectl annotate storageclass local-path \storageclass.kubernetes.io/is-default-class=trueCheck the result:
kubectl get storageclasses
Now, the StorageClass should have (default) next to its name.
Install the ElasticSearch operator
The operator provides:
- a few CustomResourceDefinitions
- a Namespace for its other resources
- a ValidatingWebhookConfiguration for type checking
- a StatefulSet for its controller and webhook code
- a ServiceAccount, ClusterRole, ClusterRoleBinding for permissions
All these resources are grouped in a convenient YAML file
- Install the operator:kubectl apply -f ~/container.training/k8s/eck-operator.yaml
Check our new custom resources
- Let's see which CRDs were created
- List all CRDs:kubectl get crds
This operator supports ElasticSearch, but also Kibana and APM. Cool!
Create the eck-demo namespace
For clarity, we will create everything in a new namespace,
eck-demoThis namespace is hard-coded in the YAML files that we are going to use
We need to create that namespace
Create the
eck-demonamespace:kubectl create namespace eck-demoSwitch to that namespace:
kns eck-demo
Can we use a different namespace?
Yes, but then we need to update all the YAML manifests that we are going to apply in the next slides.
The eck-demo namespace is hard-coded in these YAML manifests.
Why?
Because when defining a ClusterRoleBinding that references a ServiceAccount, we have to indicate in which namespace the ServiceAccount is located.
Create an ElasticSearch resource
We can now create a resource with
kind: ElasticSearchThe YAML for that resource will specify all the desired parameters:
- how many nodes we want
- image to use
- add-ons (kibana, cerebro, ...)
- whether to use TLS or not
- etc.
- Create our ElasticSearch cluster:kubectl apply -f ~/container.training/k8s/eck-elasticsearch.yaml
Operator in action
Over the next minutes, the operator will create our ES cluster
It will report our cluster status through the CRD
- Check the logs of the operator:stern --namespace=elastic-system operator
- Watch the status of the cluster through the CRD:kubectl get es -w
Connecting to our cluster
It's not easy to use the ElasticSearch API from the shell
But let's check at least if ElasticSearch is up!
Get the ClusterIP of our ES instance:
kubectl get servicesIssue a request with
curl:curl http://CLUSTERIP:9200
We get an authentication error. Our cluster is protected!
Obtaining the credentials
The operator creates a user named
elasticIt generates a random password and stores it in a Secret
Extract the password:
kubectl get secret demo-es-elastic-user \-o go-template="{{ .data.elastic | base64decode }} "Use it to connect to the API:
curl -u elastic:PASSWORD http://CLUSTERIP:9200
We should see a JSON payload with the "You Know, for Search" tagline.
Sending data to the cluster
Let's send some data to our brand new ElasticSearch cluster!
We'll deploy a filebeat DaemonSet to collect node logs
Deploy filebeat:
kubectl apply -f ~/container.training/k8s/eck-filebeat.yamlWait until some pods are up:
watch kubectl get pods -l k8s-app=filebeat
- Check that a filebeat index was created:curl -u elastic:PASSWORD http://CLUSTERIP:9200/_cat/indices
Deploying an instance of Kibana
Kibana can visualize the logs injected by filebeat
The ECK operator can also manage Kibana
Let's give it a try!
Deploy a Kibana instance:
kubectl apply -f ~/container.training/k8s/eck-kibana.yamlWait for it to be ready:
kubectl get kibana -w
Connecting to Kibana
Kibana is automatically set up to conect to ElasticSearch
(this is arranged by the YAML that we're using)
However, it will ask for authentication
It's using the same user/password as ElasticSearch
Get the NodePort allocated to Kibana:
kubectl get servicesConnect to it with a web browser
Use the same user/password as before
Setting up Kibana
After the Kibana UI loads, we need to click around a bit
Pick "explore on my own"
Click on Use Elasticsearch data / Connect to your Elasticsearch index"
Enter
filebeat-*for the index pattern and click "Next step"Select
@timestampas time filter field nameClick on "discover" (the small icon looking like a compass on the left bar)
Play around!
Scaling up the cluster
At this point, we have only one node
We are going to scale up
But first, we'll deploy Cerebro, an UI for ElasticSearch
This will let us see the state of the cluster, how indexes are sharded, etc.
Deploying Cerebro
Cerebro is stateless, so it's fairly easy to deploy
(one Deployment + one Service)
However, it needs the address and credentials for ElasticSearch
We prepared yet another manifest for that!
Deploy Cerebro:
kubectl apply -f ~/container.training/k8s/eck-cerebro.yamlLookup the NodePort number and connect to it:
kubectl get services
Scaling up the cluster
We can see on Cerebro that the cluster is "yellow"
(because our index is not replicated)
Let's change that!
Edit the ElasticSearch cluster manifest:
kubectl edit es demoFind the field
count: 1and change it to 3Save and quit
Deploying our apps with operators
It is very simple to deploy with
kubectl run/kubectl exposeWe can unlock more features by writing YAML and using
kubectl applyKustomize or Helm let us deploy in multiple environments
(and adjust/tweak parameters in each environment)
We can also use an operator to deploy our application
Pros and cons of deploying with operators
The app definition and configuration is persisted in the Kubernetes API
Multiple instances of the app can be manipulated with
kubectl getWe can add labels, annotations to the app instances
Our controller can execute custom code for any lifecycle event
However, we need to write this controller
We need to be careful about changes
(what happens when the resource
specis updated?)
Operators are not magic
Look at the ElasticSearch resource definition
(
~/container.training/k8s/eck-elasticsearch.yaml)What should happen if we flip the TLS flag? Twice?
What should happen if we add another group of nodes?
What if we want different images or parameters for the different nodes?
Operators can be very powerful.
But we need to know exactly the scenarios that they can handle.
What does it take to write an operator?
Writing a quick-and-dirty operator, or a POC/MVP, is easy
Writing a robust operator is hard
We will describe the general idea
We will identify some of the associated challenges
We will list a few tools that can help us
Top-down vs. bottom-up
Both approaches are possible
Let's see what they entail, and their respective pros and cons
Top-down approach
Start with high-level design (see next slide)
Pros:
- can yield cleaner design that will be more robust
Cons:
must be able to anticipate all the events that might happen
design will be better only to the extent of what we anticipated
hard to anticipate if we don't have production experience
High-level design
What are we solving?
(e.g.: geographic databases backed by PostGIS with Redis caches)
What are our use-cases, stories?
(e.g.: adding/resizing caches and read replicas; load balancing queries)
What kind of outage do we want to address?
(e.g.: loss of individual node, pod, volume)
What are our non-features, the things we don't want to address?
(e.g.: loss of datacenter/zone; differentiating between read and write queries;
cache invalidation; upgrading to newer major versions of Redis, PostGIS, PostgreSQL)
Low-level design
What Custom Resource Definitions do we need?
(one, many?)
How will we store configuration information?
(part of the CRD spec fields, annotations, other?)
Do we need to store state? If so, where?
state that is small and doesn't change much can be stored via the Kubernetes API
(e.g.: leader information, configuration, credentials)things that are big and/or change a lot should go elsewhere
(e.g.: metrics, bigger configuration file like GeoIP)
What can we store via the Kubernetes API?
The API server stores most Kubernetes resources in etcd
Etcd is designed for reliability, not for performance
If our storage needs exceed what etcd can offer, we need to use something else:
either directly
or by extending the API server
(for instance by using the agregation layer, like metrics server does)
Bottom-up approach
Start with existing Kubernetes resources (Deployment, Stateful Set...)
Run the system in production
Add scripts, automation, to facilitate day-to-day operations
Turn the scripts into an operator
Pros: simpler to get started; reflects actual use-cases
Cons: can result in convoluted designs requiring extensive refactor
General idea
Our operator will watch its CRDs and associated resources
Drawing state diagrams and finite state automata helps a lot
It's OK if some transitions lead to a big catch-all "human intervention"
Over time, we will learn about new failure modes and add to these diagrams
It's OK to start with CRD creation / deletion and prevent any modification
(that's the easy POC/MVP we were talking about)
Presentation and validation will help our users
(more on that later)
Challenges
Reacting to infrastructure disruption can seem hard at first
Kubernetes gives us a lot of primitives to help:
Pods and Persistent Volumes will eventually recover
Stateful Sets give us easy ways to "add N copies" of a thing
The real challenges come with configuration changes
(i.e., what to do when our users update our CRDs)
Keep in mind that some of the largest cloud outages haven't been caused by natural catastrophes, or even code bugs, but by configuration changes k8s/operators-design.md
Configuration changes
It is helpful to analyze and understand how Kubernetes controllers work:
watch resource for modifications
compare desired state (CRD) and current state
issue actions to converge state
Configuration changes will probably require another state diagram or FSA
Again, it's OK to have transitions labeled as "unsupported"
(i.e. reject some modifications because we can't execute them)
Tools
CoreOS / RedHat Operator Framework
GitHub | Blog | Intro talk | Deep dive talk | Simple example
Zalando Kubernetes Operator Pythonic Framework (KOPF)
Mesosphere Kubernetes Universal Declarative Operator (KUDO)
GitHub | Blog | Docs | Zookeeper example
Validation
By default, a CRD is "free form"
(we can put pretty much anything we want in it)
When creating a CRD, we can provide an OpenAPI v3 schema (Example)
The API server will then validate resources created/edited with this schema
If we need a stronger validation, we can use a Validating Admission Webhook:
run an admission webhook server to receive validation requests
register the webhook by creating a ValidatingWebhookConfiguration
each time the API server receives a request matching the configuration,
the request is sent to our server for validation
Presentation
By default,
kubectl get mycustomresourcewon't display much information(just the name and age of each resource)
When creating a CRD, we can specify additional columns to print (Example, Docs)
By default,
kubectl describe mycustomresourcewill also be generickubectl describecan show events related to our custom resources(for that, we need to create Event resources, and fill the
involvedObjectfield)For scalable resources, we can define a
scalesub-resourceThis will enable the use of
kubectl scaleand other scaling-related operations
About scaling
It is possible to use the HPA (Horizontal Pod Autoscaler) with CRDs
But it is not always desirable
The HPA works very well for homogenous, stateless workloads
For other workloads, your mileage may vary
Some systems can scale across multiple dimensions
(for instance: increase number of replicas, or number of shards?)
If autoscaling is desired, the operator will have to take complex decisions
(example: Zalando's Elasticsearch Operator (Video))
Versioning
As our operator evolves over time, we may have to change the CRD
(add, remove, change fields)
Like every other resource in Kubernetes, custom resources are versioned
When creating a CRD, we need to specify a list of versions
Versions can be marked as
storedand/orserved
Stored version
Exactly one version has to be marked as the
storedversionAs the name implies, it is the one that will be stored in etcd
Resources in storage are never converted automatically
(we need to read and re-write them ourselves)
Yes, this means that we can have different versions in etcd at any time
Our code needs to handle all the versions that still exist in storage
Served versions
By default, the Kubernetes API will serve resources "as-is"
(using their stored version)
It will assume that all versions are compatible storage-wise
(i.e. that the spec and fields are compatible between versions)
We can provide conversion webhooks to "translate" requests
(the alternative is to upgrade all stored resources and stop serving old versions)
Operator reliability
Remember that the operator itself must be resilient
(e.g.: the node running it can fail)
Our operator must be able to restart and recover gracefully
Do not store state locally
(unless we can reconstruct that state when we restart)
As indicated earlier, we can use the Kubernetes API to store data:
in the custom resources themselves
in other resources' annotations
Beyond CRDs
CRDs cannot use custom storage (e.g. for time series data)
CRDs cannot support arbitrary subresources (like logs or exec for Pods)
CRDs cannot support protobuf (for faster, more efficient communication)
If we need these things, we can use the aggregation layer instead
The aggregation layer proxies all requests below a specific path to another server
(this is used e.g. by the metrics server)
This documentation page compares the features of CRDs and API aggregation
Owners and dependents
(automatically generated title slide)
Owners and dependents
(automatically generated title slide)
Owners and dependents
Some objects are created by other objects
(example: pods created by replica sets, themselves created by deployments)
When an owner object is deleted, its dependents are deleted
(this is the default behavior; it can be changed)
We can delete a dependent directly if we want
(but generally, the owner will recreate another right away)
An object can have multiple owners
Finding out the owners of an object
- The owners are recorded in the field
ownerReferencesin themetadatablock
Let's create a deployment running
nginx:kubectl create deployment yanginx --image=nginxScale it to a few replicas:
kubectl scale deployment yanginx --replicas=3Once it's up, check the corresponding pods:
kubectl get pods -l app=yanginx -o yaml | head -n 25
These pods are owned by a ReplicaSet named yanginx-xxxxxxxxxx.
Listing objects with their owners
- This is a good opportunity to try the
custom-columnsoutput!
- Show all pods with their owners:kubectl get pod -o custom-columns=\NAME:.metadata.name,\OWNER-KIND:.metadata.ownerReferences[0].kind,\OWNER-NAME:.metadata.ownerReferences[0].name
Note: the custom-columns option should be one long option (without spaces),
so the lines should not be indented (otherwise the indentation will insert spaces).
Deletion policy
When deleting an object through the API, three policies are available:
foreground (API call returns after all dependents are deleted)
background (API call returns immediately; dependents are scheduled for deletion)
orphan (the dependents are not deleted)
When deleting an object with
kubectl, this is selected with--cascade:--cascade=truedeletes all dependent objects (default)--cascade=falseorphans dependent objects
What happens when an object is deleted
It is removed from the list of owners of its dependents
If, for one of these dependents, the list of owners becomes empty ...
if the policy is "orphan", the object stays
otherwise, the object is deleted
Orphaning pods
We are going to delete the Deployment and Replica Set that we created
... without deleting the corresponding pods!
Delete the Deployment:
kubectl delete deployment -l app=yanginx --cascade=falseDelete the Replica Set:
kubectl delete replicaset -l app=yanginx --cascade=falseCheck that the pods are still here:
kubectl get pods
When and why would we have orphans?
If we remove an owner and explicitly instruct the API to orphan dependents
(like on the previous slide)
If we change the labels on a dependent, so that it's not selected anymore
(e.g. change the
app: yanginxin the pods of the previous example)If a deployment tool that we're using does these things for us
If there is a serious problem within API machinery or other components
(i.e. "this should not happen")
Finding orphan objects
We're going to output all pods in JSON format
Then we will use
jqto keep only the ones without an ownerAnd we will display their name
- List all pods that do not have an owner:kubectl get pod -o json | jq -r ".items[]| select(.metadata.ownerReferences|not)| .metadata.name"
Deleting orphan pods
- Now that we can list orphan pods, deleting them is easy
- Add
| xargs kubectl delete podto the previous command:kubectl get pod -o json | jq -r ".items[]| select(.metadata.ownerReferences|not)| .metadata.name" | xargs kubectl delete pod
As always, the documentation has useful extra information and pointers.
Centralized logging
(automatically generated title slide)
Centralized logging
Using
kubectlorsternis simple; but it has drawbacks:when a node goes down, its logs are not available anymore
we can only dump or stream logs; we want to search/index/count...
We want to send all our logs to a single place
We want to parse them (e.g. for HTTP logs) and index them
We want a nice web dashboard
Centralized logging
Using
kubectlorsternis simple; but it has drawbacks:when a node goes down, its logs are not available anymore
we can only dump or stream logs; we want to search/index/count...
We want to send all our logs to a single place
We want to parse them (e.g. for HTTP logs) and index them
We want a nice web dashboard
We are going to deploy an EFK stack
What is EFK?
EFK is three components:
ElasticSearch (to store and index log entries)
Fluentd (to get container logs, process them, and put them in ElasticSearch)
Kibana (to view/search log entries with a nice UI)
The only component that we need to access from outside the cluster will be Kibana
Deploying EFK on our cluster
- We are going to use a YAML file describing all the required resources
- Load the YAML file into our cluster:kubectl apply -f ~/container.training/k8s/efk.yaml
If we look at the YAML file, we see that it creates a daemon set, two deployments, two services, and a few roles and role bindings (to give fluentd the required permissions).
The itinerary of a log line (before Fluentd)
A container writes a line on stdout or stderr
Both are typically piped to the container engine (Docker or otherwise)
The container engine reads the line, and sends it to a logging driver
The timestamp and stream (stdout or stderr) is added to the log line
With the default configuration for Kubernetes, the line is written to a JSON file
(
/var/log/containers/pod-name_namespace_container-id.log)That file is read when we invoke
kubectl logs; we can access it directly too
The itinerary of a log line (with Fluentd)
Fluentd runs on each node (thanks to a daemon set)
It bind-mounts
/var/log/containersfrom the host (to access these files)It continuously scans this directory for new files; reads them; parses them
Each log line becomes a JSON object, fully annotated with extra information:
container id, pod name, Kubernetes labels...These JSON objects are stored in ElasticSearch
ElasticSearch indexes the JSON objects
We can access the logs through Kibana (and perform searches, counts, etc.)
Accessing Kibana
Kibana offers a web interface that is relatively straightforward
Let's check it out!
Check which
NodePortwas allocated to Kibana:kubectl get svc kibanaWith our web browser, connect to Kibana
Using Kibana
Note: this is not a Kibana workshop! So this section is deliberately very terse.
The first time you connect to Kibana, you must "configure an index pattern"
Just use the one that is suggested,
@timestamp*Then click "Discover" (in the top-left corner)
You should see container logs
Advice: in the left column, select a few fields to display, e.g.:
kubernetes.host,kubernetes.pod_name,stream,log
*If you don't see @timestamp, it's probably because no logs exist yet.
Wait a bit, and double-check the logging pipeline!
Caveat emptor
We are using EFK because it is relatively straightforward to deploy on Kubernetes, without having to redeploy or reconfigure our cluster. But it doesn't mean that it will always be the best option for your use-case. If you are running Kubernetes in the cloud, you might consider using the cloud provider's logging infrastructure (if it can be integrated with Kubernetes).
The deployment method that we will use here has been simplified: there is only one ElasticSearch node. In a real deployment, you might use a cluster, both for performance and reliability reasons. But this is outside of the scope of this chapter.
The YAML file that we used creates all the resources in the
default namespace, for simplicity. In a real scenario, you will
create the resources in the kube-system namespace or in a dedicated namespace.
Collecting metrics with Prometheus
(automatically generated title slide)
Collecting metrics with Prometheus
Prometheus is an open-source monitoring system including:
multiple service discovery backends to figure out which metrics to collect
a scraper to collect these metrics
an efficient time series database to store these metrics
a specific query language (PromQL) to query these time series
an alert manager to notify us according to metrics values or trends
We are going to use it to collect and query some metrics on our Kubernetes cluster
Why Prometheus?
We don't endorse Prometheus more or less than any other system
It's relatively well integrated within the cloud-native ecosystem
It can be self-hosted (this is useful for tutorials like this)
It can be used for deployments of varying complexity:
one binary and 10 lines of configuration to get started
all the way to thousands of nodes and millions of metrics
Exposing metrics to Prometheus
Prometheus obtains metrics and their values by querying exporters
An exporter serves metrics over HTTP, in plain text
This is what the node exporter looks like:
Prometheus itself exposes its own internal metrics, too:
If you want to expose custom metrics to Prometheus:
serve a text page like these, and you're good to go
libraries are available in various languages to help with quantiles etc.
How Prometheus gets these metrics
The Prometheus server will scrape URLs like these at regular intervals
(by default: every minute; can be more/less frequent)
The list of URLs to scrape (the scrape targets) is defined in configuration
Worried about the overhead of parsing a text format?
Check this comparison of the text format with the (now deprecated) protobuf format!
Defining scrape targets
This is maybe the simplest configuration file for Prometheus:
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090']In this configuration, Prometheus collects its own internal metrics
A typical configuration file will have multiple
scrape_configsIn this configuration, the list of targets is fixed
A typical configuration file will use dynamic service discovery
Service discovery
This configuration file will leverage existing DNS A records:
scrape_configs: - ... - job_name: 'node' dns_sd_configs: - names: ['api-backends.dc-paris-2.enix.io'] type: 'A' port: 9100In this configuration, Prometheus resolves the provided name(s)
(here,
api-backends.dc-paris-2.enix.io)Each resulting IP address is added as a target on port 9100
Dynamic service discovery
In the DNS example, the names are re-resolved at regular intervals
As DNS records are created/updated/removed, scrape targets change as well
Existing data (previously collected metrics) is not deleted
Other service discovery backends work in a similar fashion
Other service discovery mechanisms
Prometheus can connect to e.g. a cloud API to list instances
Or to the Kubernetes API to list nodes, pods, services ...
Or a service like Consul, Zookeeper, etcd, to list applications
The resulting configurations files are way more complex
(but don't worry, we won't need to write them ourselves)
Time series database
We could wonder, "why do we need a specialized database?"
One metrics data point = metrics ID + timestamp + value
With a classic SQL or noSQL data store, that's at least 160 bits of data + indexes
Prometheus is way more efficient, without sacrificing performance
(it will even be gentler on the I/O subsystem since it needs to write less)
Would you like to know more? Check this video:
Storage in Prometheus 2.0 by Goutham V at DC17EU
Checking if Prometheus is installed
- Before trying to install Prometheus, let's check if it's already there
- Look for services with a label
app=prometheusacross all namespaces:kubectl get services --selector=app=prometheus --all-namespaces
If we see a NodePort service called prometheus-server, we're good!
(We can then skip to "Connecting to the Prometheus web UI".)
Running Prometheus on our cluster
We need to:
Run the Prometheus server in a pod
(using e.g. a Deployment to ensure that it keeps running)
Expose the Prometheus server web UI (e.g. with a NodePort)
Run the node exporter on each node (with a Daemon Set)
Set up a Service Account so that Prometheus can query the Kubernetes API
Configure the Prometheus server
(storing the configuration in a Config Map for easy updates)
Helm charts to the rescue
To make our lives easier, we are going to use a Helm chart
The Helm chart will take care of all the steps explained above
(including some extra features that we don't need, but won't hurt)
Step 1: install Helm
- If we already installed Helm earlier, this command won't break anything
- Install the Helm CLI:curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get-helm-3 \| bash
Step 2: add the stable repo
This will add the repository containing the chart for Prometheus
This command is idempotent
(it won't break anything if the repository was already added)
- Add the repository:helm repo add stable https://kubernetes-charts.storage.googleapis.com/
Step 3: install Prometheus
The following command, just like the previous ones, is idempotent
(it won't error out if Prometheus is already installed)
- Install Prometheus on our cluster:helm upgrade prometheus stable/prometheus \--install \--namespace kube-system \--set server.service.type=NodePort \--set server.service.nodePort=30090 \--set server.persistentVolume.enabled=false \--set alertmanager.enabled=false
Curious about all these flags? They're explained in the next slide.
Explaining all the Helm flags
helm upgrade prometheus→ upgrade release "prometheus" to the latest version...(a "release" is a unique name given to an app deployed with Helm)
stable/prometheus→ ... of the chartprometheusin repostable--install→ if the app doesn't exist, create it--namespace kube-system→ put it in that specific namespaceAnd set the following values when rendering the chart's templates:
server.service.type=NodePort→ expose the Prometheus server with a NodePortserver.service.nodePort=30090→ set the specific NodePort number to useserver.persistentVolume.enabled=false→ do not use a PersistentVolumeClaimalertmanager.enabled=false→ disable the alert manager entirely
Connecting to the Prometheus web UI
- Let's connect to the web UI and see what we can do
Figure out the NodePort that was allocated to the Prometheus server:
kubectl get svc --all-namespaces | grep prometheus-serverWith your browser, connect to that port
Querying some metrics
- This is easy... if you are familiar with PromQL
- Click on "Graph", and in "expression", paste the following:sum by (instance) (irate(container_cpu_usage_seconds_total{pod_name=~"worker.*"}[5m]))
Click on the blue "Execute" button and on the "Graph" tab just below
We see the cumulated CPU usage of worker pods for each node
(if we just deployed Prometheus, there won't be much data to see, though)
Getting started with PromQL
We can't learn PromQL in just 5 minutes
But we can cover the basics to get an idea of what is possible
(and have some keywords and pointers)
We are going to break down the query above
(building it one step at a time)
Graphing one metric across all tags
This query will show us CPU usage across all containers:
container_cpu_usage_seconds_totalThe suffix of the metrics name tells us:
the unit (seconds of CPU)
that it's the total used since the container creation
Since it's a "total," it is an increasing quantity
(we need to compute the derivative if we want e.g. CPU % over time)
We see that the metrics retrieved have tags attached to them
Selecting metrics with tags
This query will show us only metrics for worker containers:
container_cpu_usage_seconds_total{pod_name=~"worker.*"}The
=~operator allows regex matchingWe select all the pods with a name starting with
worker(it would be better to use labels to select pods; more on that later)
The result is a smaller set of containers
Transforming counters in rates
This query will show us CPU usage % instead of total seconds used:
100*irate(container_cpu_usage_seconds_total{pod_name=~"worker.*"}[5m])The
irateoperator computes the "per-second instant rate of increase"rateis similar but allows decreasing counters and negative valueswith
irate, if a counter goes back to zero, we don't get a negative spike
The
[5m]tells how far to look back if there is a gap in the dataAnd we multiply with
100*to get CPU % usage
Aggregation operators
This query sums the CPU usage per node:
sum by (instance) ( irate(container_cpu_usage_seconds_total{pod_name=~"worker.*"}[5m]))instancecorresponds to the node on which the container is runningsum by (instance) (...)computes the sum for each instanceNote: all the other tags are collapsed
(in other words, the resulting graph only shows the
instancetag)PromQL supports many more aggregation operators
What kind of metrics can we collect?
Node metrics (related to physical or virtual machines)
Container metrics (resource usage per container)
Databases, message queues, load balancers, ...
(check out this list of exporters!)
Instrumentation (=deluxe
printffor our code)Business metrics (customers served, revenue, ...)
Node metrics
CPU, RAM, disk usage on the whole node
Total number of processes running, and their states
Number of open files, sockets, and their states
I/O activity (disk, network), per operation or volume
Physical/hardware (when applicable): temperature, fan speed...
...and much more!
Container metrics
Similar to node metrics, but not totally identical
RAM breakdown will be different
- active vs inactive memory
- some memory is shared between containers, and specially accounted for
I/O activity is also harder to track
- async writes can cause deferred "charges"
- some page-ins are also shared between containers
For details about container metrics, see:
http://jpetazzo.github.io/2013/10/08/docker-containers-metrics/
Application metrics
Arbitrary metrics related to your application and business
System performance: request latency, error rate...
Volume information: number of rows in database, message queue size...
Business data: inventory, items sold, revenue...
Detecting scrape targets
Prometheus can leverage Kubernetes service discovery
(with proper configuration)
Services or pods can be annotated with:
prometheus.io/scrape: trueto enable scrapingprometheus.io/port: 9090to indicate the port numberprometheus.io/path: /metricsto indicate the URI (/metricsby default)
Prometheus will detect and scrape these (without needing a restart or reload)
Querying labels
What if we want to get metrics for containers belonging to a pod tagged
worker?The cAdvisor exporter does not give us Kubernetes labels
Kubernetes labels are exposed through another exporter
We can see Kubernetes labels through metrics
kube_pod_labels(each container appears as a time series with constant value of
1)Prometheus kind of supports "joins" between time series
But only if the names of the tags match exactly
Unfortunately ...
The cAdvisor exporter uses tag
pod_namefor the name of a podThe Kubernetes service endpoints exporter uses tag
podinsteadSee this blog post or this other one to see how to perform "joins"
Alas, Prometheus cannot "join" time series with different labels
(see Prometheus issue #2204 for the rationale)
There is a workaround involving relabeling, but it's "not cheap"
see this comment for an overview
or this blog post for a complete description of the process
In practice
Grafana is a beautiful (and useful) frontend to display all kinds of graphs
Not everyone needs to know Prometheus, PromQL, Grafana, etc.
But in a team, it is valuable to have at least one person who know them
That person can set up queries and dashboards for the rest of the team
It's a little bit like knowing how to optimize SQL queries, Dockerfiles...
Don't panic if you don't know these tools!
...But make sure at least one person in your team is on it 💯
Resource Limits
(automatically generated title slide)
Resource Limits
We can attach resource indications to our pods
(or rather: to the containers in our pods)
We can specify limits and/or requests
We can specify quantities of CPU and/or memory
CPU vs memory
CPU is a compressible resource
(it can be preempted immediately without adverse effect)
Memory is an incompressible resource
(it needs to be swapped out to be reclaimed; and this is costly)
As a result, exceeding limits will have different consequences for CPU and memory
Exceeding CPU limits
CPU can be reclaimed instantaneously
(in fact, it is preempted hundreds of times per second, at each context switch)
If a container uses too much CPU, it can be throttled
(it will be scheduled less often)
The processes in that container will run slower
(or rather: they will not run faster)
Exceeding memory limits
Memory needs to be swapped out before being reclaimed
"Swapping" means writing memory pages to disk, which is very slow
On a classic system, a process that swaps can get 1000x slower
(because disk I/O is 1000x slower than memory I/O)
Exceeding the memory limit (even by a small amount) can reduce performance a lot
Kubernetes does not support swap (more on that later!)
Exceeding the memory limit will cause the container to be killed
Limits vs requests
Limits are "hard limits" (they can't be exceeded)
a container exceeding its memory limit is killed
a container exceeding its CPU limit is throttled
Requests are used for scheduling purposes
a container using less than what it requested will never be killed or throttled
the scheduler uses the requested sizes to determine placement
the resources requested by all pods on a node will never exceed the node size
Pod quality of service
Each pod is assigned a QoS class (visible in status.qosClass).
If limits = requests:
as long as the container uses less than the limit, it won't be affected
if all containers in a pod have (limits=requests), QoS is considered "Guaranteed"
If requests < limits:
as long as the container uses less than the request, it won't be affected
otherwise, it might be killed/evicted if the node gets overloaded
if at least one container has (requests<limits), QoS is considered "Burstable"
If a pod doesn't have any request nor limit, QoS is considered "BestEffort"
Quality of service impact
When a node is overloaded, BestEffort pods are killed first
Then, Burstable pods that exceed their limits
Burstable and Guaranteed pods below their limits are never killed
(except if their node fails)
If we only use Guaranteed pods, no pod should ever be killed
(as long as they stay within their limits)
(Pod QoS is also explained in this page of the Kubernetes documentation and in this blog post.)
Where is my swap?
The semantics of memory and swap limits on Linux cgroups are complex
In particular, it's not possible to disable swap for a cgroup
(the closest option is to reduce "swappiness")
The architects of Kubernetes wanted to ensure that Guaranteed pods never swap
The only solution was to disable swap entirely
Alternative point of view
Swap enables paging¹ of anonymous² memory
Even when swap is disabled, Linux will still page memory for:
executables, libraries
mapped files
Disabling swap will reduce performance and available resources
For a good time, read kubernetes/kubernetes#53533
Also read this excellent blog post about swap
¹Paging: reading/writing memory pages from/to disk to reclaim physical memory
²Anonymous memory: memory that is not backed by files or blocks
Enabling swap anyway
If you don't care that pods are swapping, you can enable swap
You will need to add the flag
--fail-swap-on=falseto kubelet(otherwise, it won't start!)
Specifying resources
Resource requests are expressed at the container level
CPU is expressed in "virtual CPUs"
(corresponding to the virtual CPUs offered by some cloud providers)
CPU can be expressed with a decimal value, or even a "milli" suffix
(so 100m = 0.1)
Memory is expressed in bytes
Memory can be expressed with k, M, G, T, ki, Mi, Gi, Ti suffixes
(corresponding to 10^3, 10^6, 10^9, 10^12, 2^10, 2^20, 2^30, 2^40)
Specifying resources in practice
This is what the spec of a Pod with resources will look like:
containers:- name: httpenv image: jpetazzo/httpenv resources: limits: memory: "100Mi" cpu: "100m" requests: memory: "100Mi" cpu: "10m"This set of resources makes sure that this service won't be killed (as long as it stays below 100 MB of RAM), but allows its CPU usage to be throttled if necessary.
Default values
If we specify a limit without a request:
the request is set to the limit
If we specify a request without a limit:
there will be no limit
(which means that the limit will be the size of the node)
If we don't specify anything:
the request is zero and the limit is the size of the node
Unless there are default values defined for our namespace!
We need default resource values
If we do not set resource values at all:
the limit is "the size of the node"
the request is zero
This is generally not what we want
a container without a limit can use up all the resources of a node
if the request is zero, the scheduler can't make a smart placement decision
To address this, we can set default values for resources
This is done with a LimitRange object
Defining min, max, and default resources
(automatically generated title slide)
Defining min, max, and default resources
We can create LimitRange objects to indicate any combination of:
min and/or max resources allowed per pod
default resource limits
default resource requests
maximal burst ratio (limit/request)
LimitRange objects are namespaced
They apply to their namespace only
LimitRange example
apiVersion: v1kind: LimitRangemetadata: name: my-very-detailed-limitrangespec: limits: - type: Container min: cpu: "100m" max: cpu: "2000m" memory: "1Gi" default: cpu: "500m" memory: "250Mi" defaultRequest: cpu: "500m"Example explanation
The YAML on the previous slide shows an example LimitRange object specifying very detailed limits on CPU usage, and providing defaults on RAM usage.
Note the type: Container line: in the future,
it might also be possible to specify limits
per Pod, but it's not officially documented yet.
LimitRange details
LimitRange restrictions are enforced only when a Pod is created
(they don't apply retroactively)
They don't prevent creation of e.g. an invalid Deployment or DaemonSet
(but the pods will not be created as long as the LimitRange is in effect)
If there are multiple LimitRange restrictions, they all apply together
(which means that it's possible to specify conflicting LimitRanges,
preventing any Pod from being created)If a LimitRange specifies a
maxfor a resource but nodefault,
thatmaxvalue becomes thedefaultlimit too
Namespace quotas
(automatically generated title slide)
Namespace quotas
We can also set quotas per namespace
Quotas apply to the total usage in a namespace
(e.g. total CPU limits of all pods in a given namespace)
Quotas can apply to resource limits and/or requests
(like the CPU and memory limits that we saw earlier)
Quotas can also apply to other resources:
"extended" resources (like GPUs)
storage size
number of objects (number of pods, services...)
Creating a quota for a namespace
Quotas are enforced by creating a ResourceQuota object
ResourceQuota objects are namespaced, and apply to their namespace only
We can have multiple ResourceQuota objects in the same namespace
The most restrictive values are used
Limiting total CPU/memory usage
- The following YAML specifies an upper bound for limits and requests:apiVersion: v1kind: ResourceQuotametadata:name: a-little-bit-of-computespec:hard:requests.cpu: "10"requests.memory: 10Gilimits.cpu: "20"limits.memory: 20Gi
These quotas will apply to the namespace where the ResourceQuota is created.
Limiting number of objects
- The following YAML specifies how many objects of specific types can be created:apiVersion: v1kind: ResourceQuotametadata:name: quota-for-objectsspec:hard:pods: 100services: 10secrets: 10configmaps: 10persistentvolumeclaims: 20services.nodeports: 0services.loadbalancers: 0count/roles.rbac.authorization.k8s.io: 10
(The count/ syntax allows limiting arbitrary objects, including CRDs.)
YAML vs CLI
Quotas can be created with a YAML definition
...Or with the
kubectl create quotacommandExample:
kubectl create quota my-resource-quota --hard=pods=300,limits.memory=300GiWith both YAML and CLI form, the values are always under the
hardsection(there is no
softquota)
Viewing current usage
When a ResourceQuota is created, we can see how much of it is used:
kubectl describe resourcequota my-resource-quotaName: my-resource-quotaNamespace: defaultResource Used Hard-------- ---- ----pods 12 100services 1 5services.loadbalancers 0 0services.nodeports 0 0Advanced quotas and PriorityClass
Since Kubernetes 1.12, it is possible to create PriorityClass objects
Pods can be assigned a PriorityClass
Quotas can be linked to a PriorityClass
This allows us to reserve resources for pods within a namespace
For more details, check this documentation page
Limiting resources in practice
(automatically generated title slide)
Limiting resources in practice
We have at least three mechanisms:
requests and limits per Pod
LimitRange per namespace
ResourceQuota per namespace
Let's see a simple recommendation to get started with resource limits
Set a LimitRange
In each namespace, create a LimitRange object
Set a small default CPU request and CPU limit
(e.g. "100m")
Set a default memory request and limit depending on your most common workload
for Java, Ruby: start with "1G"
for Go, Python, PHP, Node: start with "250M"
Set upper bounds slightly below your expected node size
(80-90% of your node size, with at least a 500M memory buffer)
Set a ResourceQuota
In each namespace, create a ResourceQuota object
Set generous CPU and memory limits
(e.g. half the cluster size if the cluster hosts multiple apps)
Set generous objects limits
these limits should not be here to constrain your users
they should catch a runaway process creating many resources
example: a custom controller creating many pods
Observe, refine, iterate
Observe the resource usage of your pods
(we will see how in the next chapter)
Adjust individual pod limits
If you see trends: adjust the LimitRange
(rather than adjusting every individual set of pod limits)
Observe the resource usage of your namespaces
(with
kubectl describe resourcequota ...)Rinse and repeat regularly
Additional resources
A Practical Guide to Setting Kubernetes Requests and Limits
explains what requests and limits are
provides guidelines to set requests and limits
gives PromQL expressions to compute good values
(our app needs to be running for a while)
-
generates web reports on resource usage
Checking pod and node resource usage
(automatically generated title slide)
Checking pod and node resource usage
Since Kubernetes 1.8, metrics are collected by the resource metrics pipeline
The resource metrics pipeline is:
optional (Kubernetes can function without it)
necessary for some features (like the Horizontal Pod Autoscaler)
exposed through the Kubernetes API using the aggregation layer
usually implemented by the "metrics server"
How to know if the metrics server is running?
- The easiest way to know is to run
kubectl top
- Check if the core metrics pipeline is available:kubectl top nodes
If it shows our nodes and their CPU and memory load, we're good!
Installing metrics server
The metrics server doesn't have any particular requirements
(it doesn't need persistence, as it doesn't store metrics)
It has its own repository, kubernetes-incubator/metrics-server
The repository comes with YAML files for deployment
These files may not work on some clusters
(e.g. if your node names are not in DNS)
The container.training repository has a metrics-server.yaml file to help with that
(we can
kubectl apply -fthat file if needed)
Showing container resource usage
- Once the metrics server is running, we can check container resource usage
- Show resource usage across all containers:kubectl top pods --containers --all-namespaces
- We can also use selectors (
-l app=...)
Other tools
kube-capacity is a great CLI tool to view resources
It can show resource and limits, and compare them with usage
It can show utilization per node, or per pod
kube-resource-report can generate HTML reports
Cluster sizing
(automatically generated title slide)
Cluster sizing
What happens when the cluster gets full?
How can we scale up the cluster?
Can we do it automatically?
What are other methods to address capacity planning?
When are we out of resources?
kubelet monitors node resources:
memory
node disk usage (typically the root filesystem of the node)
image disk usage (where container images and RW layers are stored)
For each resource, we can provide two thresholds:
a hard threshold (if it's met, it provokes immediate action)
a soft threshold (provokes action only after a grace period)
Resource thresholds and grace periods are configurable
(by passing kubelet command-line flags)
What happens then?
If disk usage is too high:
kubelet will try to remove terminated pods
then, it will try to evict pods
If memory usage is too high:
- it will try to evict pods
The node is marked as "under pressure"
This temporarily prevents new pods from being scheduled on the node
Which pods get evicted?
kubelet looks at the pods' QoS and PriorityClass
First, pods with BestEffort QoS are considered
Then, pods with Burstable QoS exceeding their requests
(but only if the exceeding resource is the one that is low on the node)
Finally, pods with Guaranteed QoS, and Burstable pods within their requests
Within each group, pods are sorted by PriorityClass
If there are pods with the same PriorityClass, they are sorted by usage excess
(i.e. the pods whose usage exceeds their requests the most are evicted first)
Eviction of Guaranteed pods
Normally, pods with Guaranteed QoS should not be evicted
A chunk of resources is reserved for node processes (like kubelet)
It is expected that these processes won't use more than this reservation
If they do use more resources anyway, all bets are off!
If this happens, kubelet must evict Guaranteed pods to preserve node stability
(or Burstable pods that are still within their requested usage)
What happens to evicted pods?
The pod is terminated
It is marked as
Failedat the API levelIf the pod was created by a controller, the controller will recreate it
The pod will be recreated on another node, if there are resources available!
For more details about the eviction process, see:
this documentation page about resource pressure and pod eviction,
this other documentation page about pod priority and preemption.
What if there are no resources available?
Sometimes, a pod cannot be scheduled anywhere:
all the nodes are under pressure,
or the pod requests more resources than are available
The pod then remains in
Pendingstate until the situation improves
Cluster scaling
One way to improve the situation is to add new nodes
This can be done automatically with the Cluster Autoscaler
The autoscaler will automatically scale up:
- if there are pods that failed to be scheduled
The autoscaler will automatically scale down:
- if nodes have a low utilization for an extended period of time
Restrictions, gotchas ...
The Cluster Autoscaler only supports a few cloud infrastructures
(see here for a list)
The Cluster Autoscaler cannot scale down nodes that have pods using:
local storage
affinity/anti-affinity rules preventing them from being rescheduled
a restrictive PodDisruptionBudget
Other way to do capacity planning
"Running Kubernetes without nodes"
Systems like Virtual Kubelet or Kiyot can run pods using on-demand resources
Virtual Kubelet can leverage e.g. ACI or Fargate to run pods
Kiyot runs pods in ad-hoc EC2 instances (1 instance per pod)
Economic advantage (no wasted capacity)
Security advantage (stronger isolation between pods)
Check this blog post for more details.
The Horizontal Pod Autoscaler
(automatically generated title slide)
The Horizontal Pod Autoscaler
What is the Horizontal Pod Autoscaler, or HPA?
It is a controller that can perform horizontal scaling automatically
Horizontal scaling = changing the number of replicas
(adding/removing pods)
Vertical scaling = changing the size of individual replicas
(increasing/reducing CPU and RAM per pod)
Cluster scaling = changing the size of the cluster
(adding/removing nodes)
k8s/horizontal-pod-autoscaler.md
Principle of operation
Each HPA resource (or "policy") specifies:
which object to monitor and scale (e.g. a Deployment, ReplicaSet...)
min/max scaling ranges (the max is a safety limit!)
a target resource usage (e.g. the default is CPU=80%)
The HPA continuously monitors the CPU usage for the related object
It computes how many pods should be running:
TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)It scales the related object up/down to this target number of pods
k8s/horizontal-pod-autoscaler.md
Pre-requirements
The metrics server needs to be running
(i.e. we need to be able to see pod metrics with
kubectl top pods)The pods that we want to autoscale need to have resource requests
(because the target CPU% is not absolute, but relative to the request)
The latter actually makes a lot of sense:
if a Pod doesn't have a CPU request, it might be using 10% of CPU...
...but only because there is no CPU time available!
this makes sure that we won't add pods to nodes that are already resource-starved
k8s/horizontal-pod-autoscaler.md
Testing the HPA
We will start a CPU-intensive web service
We will send some traffic to that service
We will create an HPA policy
The HPA will automatically scale up the service for us
k8s/horizontal-pod-autoscaler.md
A CPU-intensive web service
Let's use
jpetazzo/busyhttp(it is a web server that will use 1s of CPU for each HTTP request)
Deploy the web server:
kubectl create deployment busyhttp --image=jpetazzo/busyhttpExpose it with a ClusterIP service:
kubectl expose deployment busyhttp --port=80Get the ClusterIP allocated to the service:
kubectl get svc busyhttp
k8s/horizontal-pod-autoscaler.md
Monitor what's going on
- Let's start a bunch of commands to watch what is happening
- Monitor pod CPU usage:watch kubectl top pods -l app=busyhttp
- Monitor service latency:httping http://$CLUSTERIP/
- Monitor cluster events:kubectl get events -w
k8s/horizontal-pod-autoscaler.md
Send traffic to the service
- We will use
ab(Apache Bench) to send traffic
- Send a lot of requests to the service, with a concurrency level of 3:ab -c 3 -n 100000 http://$CLUSTERIP/
The latency (reported by httping) should increase above 3s.
The CPU utilization should increase to 100%.
(The server is single-threaded and won't go above 100%.)
k8s/horizontal-pod-autoscaler.md
Create an HPA policy
- There is a helper command to do that for us:
kubectl autoscale
- Create the HPA policy for the
busyhttpdeployment:kubectl autoscale deployment busyhttp --max=10
By default, it will assume a target of 80% CPU usage.
This can also be set with --cpu-percent=.
Create an HPA policy
- There is a helper command to do that for us:
kubectl autoscale
- Create the HPA policy for the
busyhttpdeployment:kubectl autoscale deployment busyhttp --max=10
By default, it will assume a target of 80% CPU usage.
This can also be set with --cpu-percent=.
The autoscaler doesn't seem to work. Why?
k8s/horizontal-pod-autoscaler.md
What did we miss?
The events stream gives us a hint, but to be honest, it's not very clear:
missing request for cpuWe forgot to specify a resource request for our Deployment!
The HPA target is not an absolute CPU%
It is relative to the CPU requested by the pod
k8s/horizontal-pod-autoscaler.md
Adding a CPU request
Let's edit the deployment and add a CPU request
Since our server can use up to 1 core, let's request 1 core
- Edit the Deployment definition:kubectl edit deployment busyhttp
- In the
containerslist, add the following block:resources:requests:cpu: "1"
k8s/horizontal-pod-autoscaler.md
Results
After saving and quitting, a rolling update happens
(if
aborhttpingexits, make sure to restart it)It will take a minute or two for the HPA to kick in:
the HPA runs every 30 seconds by default
it needs to gather metrics from the metrics server first
If we scale further up (or down), the HPA will react after a few minutes:
it won't scale up if it already scaled in the last 3 minutes
it won't scale down if it already scaled in the last 5 minutes
k8s/horizontal-pod-autoscaler.md
What about other metrics?
The HPA in API group
autoscaling/v1only supports CPU scalingThe HPA in API group
autoscaling/v2beta2supports metrics from various API groups:metrics.k8s.io, aka metrics server (per-Pod CPU and RAM)
custom.metrics.k8s.io, custom metrics per Pod
external.metrics.k8s.io, external metrics (not associated to Pods)
Kubernetes doesn't implement any of these API groups
Using these metrics requires registering additional APIs
The metrics provided by metrics server are standard; everything else is custom
For more details, see this great blog post or this talk
k8s/horizontal-pod-autoscaler.md
Cleanup
- Since
busyhttpuses CPU cycles, let's stop it before moving on
- Delete the
busyhttpDeployment:kubectl delete deployment busyhttp
k8s/horizontal-pod-autoscaler.md
Declarative vs imperative
(automatically generated title slide)
Declarative vs imperative
Our container orchestrator puts a very strong emphasis on being declarative
Declarative:
I would like a cup of tea.
Imperative:
Boil some water. Pour it in a teapot. Add tea leaves. Steep for a while. Serve in a cup.
Declarative vs imperative
Our container orchestrator puts a very strong emphasis on being declarative
Declarative:
I would like a cup of tea.
Imperative:
Boil some water. Pour it in a teapot. Add tea leaves. Steep for a while. Serve in a cup.
Declarative seems simpler at first ...
Declarative vs imperative
Our container orchestrator puts a very strong emphasis on being declarative
Declarative:
I would like a cup of tea.
Imperative:
Boil some water. Pour it in a teapot. Add tea leaves. Steep for a while. Serve in a cup.
Declarative seems simpler at first ...
... As long as you know how to brew tea
Declarative vs imperative
What declarative would really be:
I want a cup of tea, obtained by pouring an infusion¹ of tea leaves in a cup.
Declarative vs imperative
What declarative would really be:
I want a cup of tea, obtained by pouring an infusion¹ of tea leaves in a cup.
¹An infusion is obtained by letting the object steep a few minutes in hot² water.
Declarative vs imperative
What declarative would really be:
I want a cup of tea, obtained by pouring an infusion¹ of tea leaves in a cup.
¹An infusion is obtained by letting the object steep a few minutes in hot² water.
²Hot liquid is obtained by pouring it in an appropriate container³ and setting it on a stove.
Declarative vs imperative
What declarative would really be:
I want a cup of tea, obtained by pouring an infusion¹ of tea leaves in a cup.
¹An infusion is obtained by letting the object steep a few minutes in hot² water.
²Hot liquid is obtained by pouring it in an appropriate container³ and setting it on a stove.
³Ah, finally, containers! Something we know about. Let's get to work, shall we?
Declarative vs imperative
What declarative would really be:
I want a cup of tea, obtained by pouring an infusion¹ of tea leaves in a cup.
¹An infusion is obtained by letting the object steep a few minutes in hot² water.
²Hot liquid is obtained by pouring it in an appropriate container³ and setting it on a stove.
³Ah, finally, containers! Something we know about. Let's get to work, shall we?
Did you know there was an ISO standard specifying how to brew tea?
Declarative vs imperative
Imperative systems:
simpler
if a task is interrupted, we have to restart from scratch
Declarative systems:
if a task is interrupted (or if we show up to the party half-way through), we can figure out what's missing and do only what's necessary
we need to be able to observe the system
... and compute a "diff" between what we have and what we want
Declarative vs imperative in Kubernetes
With Kubernetes, we cannot say: "run this container"
All we can do is write a spec and push it to the API server
(for example, by creating a resource like a Pod or a Deployment)
The API server will validate that spec (and reject it if it's invalid)
Then it will store it in etcd
A controller will "notice" that spec and act upon it
Reconciling state
Watch for the
specfields in the YAML files later!The spec describes how we want the thing to be
Kubernetes will reconcile the current state with the spec
(technically, this is done by a number of controllers)When we want to change some resource, we update the spec
Kubernetes will then converge that resource
Kubernetes Management Approaches
(automatically generated title slide)
Kubernetes Management Approaches
- Imperative commands:
run,expose,scale,edit,createdeployment- Best for dev/learning/personal projects
- Easy to learn, hardest to manage over time
Kubernetes Management Approaches
Imperative commands:
run,expose,scale,edit,createdeployment- Best for dev/learning/personal projects
- Easy to learn, hardest to manage over time
Imperative objects:
create -f file.yml,replace -f file.yml,delete...- Good for prod of small environments, single file per command
- Store your changes in git-based yaml files
- Hard to automate
Kubernetes Management Approaches
Imperative commands:
run,expose,scale,edit,createdeployment- Best for dev/learning/personal projects
- Easy to learn, hardest to manage over time
Imperative objects:
create -f file.yml,replace -f file.yml,delete...- Good for prod of small environments, single file per command
- Store your changes in git-based yaml files
- Hard to automate
Declarative objects:
apply -f file.ymlor-f dir\,diff- Best for prod, easier to automate
- Harder to understand and predict changes
k8smastery/cli-good-better-best.md
Recording deployment actions
(automatically generated title slide)
Recording deployment actions
Some commands that modify a Deployment accept an optional
--recordflag(Example:
kubectl set image deployment worker worker=alpine --record)That flag will store the command line in the Deployment
(Technically, using the annotation
kubernetes.io/change-cause)It gets copied to the corresponding ReplicaSet
(Allowing to keep track of which command created or promoted this ReplicaSet)
We can view this information with
kubectl rollout history
Using --record
- Let's make a couple of changes to a Deployment and record them
Roll back
workerto image version 0.1:kubectl set image deployment worker worker=dockercoins/worker:v0.1 --recordPromote it to version 0.2 again:
kubectl set image deployment worker worker=dockercoins/worker:v0.2 --recordView the change history:
kubectl rollout history deployment worker
Pitfall #1: forgetting --record
- What happens if we don't specify
--record?
Promote
workerto image version 0.3:kubectl set image deployment worker worker=dockercoins/worker:v0.3View the change history:
kubectl rollout history deployment worker
Pitfall #1: forgetting --record
- What happens if we don't specify
--record?
Promote
workerto image version 0.3:kubectl set image deployment worker worker=dockercoins/worker:v0.3View the change history:
kubectl rollout history deployment worker
It recorded version 0.2 instead of 0.3! Why?
How --record really works
kubectladds the annotationkubernetes.io/change-causeto the DeploymentThe Deployment controller copies that annotation to the ReplicaSet
kubectl rollout historyshows the ReplicaSets' annotationsIf we don't specify
--record, the annotation is not updatedThe previous value of that annotation is copied to the new ReplicaSet
In that case, the ReplicaSet annotation does not reflect reality!
Pitfall #2: recording scale commands
- What happens if we use
kubectl scale --record?
Check the current history:
kubectl rollout history deployment workerScale the deployment:
kubectl scale deployment worker --replicas=3 --recordCheck the change history again:
kubectl rollout history deployment worker
Pitfall #2: recording scale commands
- What happens if we use
kubectl scale --record?
Check the current history:
kubectl rollout history deployment workerScale the deployment:
kubectl scale deployment worker --replicas=3 --recordCheck the change history again:
kubectl rollout history deployment worker
The last entry in the history was overwritten by the scale command! Why?
Actions that don't create a new ReplicaSet
The
scalecommand updates the Deployment definitionBut it doesn't create a new ReplicaSet
Using the
--recordflag sets the annotation like beforeThe annotation gets copied to the existing ReplicaSet
This overwrites the previous annotation that was there
In that case, we lose the previous change cause!
Updating the annotation directly
- Let's see what happens if we set the annotation manually
Annotate the Deployment:
kubectl annotate deployment worker kubernetes.io/change-cause="Just for fun"Check that our annotation shows up in the change history:
kubectl rollout history deployment worker
Updating the annotation directly
- Let's see what happens if we set the annotation manually
Annotate the Deployment:
kubectl annotate deployment worker kubernetes.io/change-cause="Just for fun"Check that our annotation shows up in the change history:
kubectl rollout history deployment worker
Our annotation shows up (and overwrote whatever was there before).
Using change cause
It sounds like a good idea to use
--record, but:"Incorrect documentation is often worse than no documentation."
(Bertrand Meyer)If we use
--recordonce, we need to either:use it every single time after that
or clear the Deployment annotation after using
--record
(subsequent changes will show up with a<none>change cause)
A safer way is to set it through our tooling
Git-based workflows
(automatically generated title slide)
Git-based workflows
Deploying with
kubectlhas downsides:we don't know who deployed what and when
there is no audit trail (except the API server logs)
there is no easy way to undo most operations
there is no review/approval process (like for code reviews)
We have all these things for code, though
Can we manage cluster state like we manage our source code?
Reminder: Kubernetes is declarative
All we do is create/change resources
These resources have a perfect YAML representation
All we do is manipulating these YAML representations
(
kubectl rungenerates a YAML file that gets applied)We can store these YAML representations in a code repository
We can version that code repository and maintain it with best practices
define which branch(es) can go to qa/staging/production
control who can push to which branches
have formal review processes, pull requests ...
Enabling git-based workflows
There are a few tools out there to help us do that
There are many other tools, some of them with even more features
There are also many integrations with popular CI/CD systems
(e.g.: GitLab, Jenkins, ...) k8s/gitworkflows.md
Flux overview
We put our Kubernetes resources as YAML files in a git repository
Flux polls that repository regularly (every 5 minutes by default)
The resources described by the YAML files are created/updated automatically
Changes are made by updating the code in the repository
Preparing a repository for Flux
We need a repository with Kubernetes YAML files
I have one: https://github.com/jpetazzo/kubercoins
Fork it to your GitHub account
Create a new branch in your fork; e.g.
prod(e.g. by adding a line in the README through the GitHub web UI)
This is the branch that we are going to use for deployment
Setting up Flux
Clone the Flux repository:
git clone https://github.com/fluxcd/fluxEdit
deploy/flux-deployment.yamlChange the
--git-urland--git-branchparameters:- [email protected]:your-git-username/kubercoins- --git-branch=prodApply all the YAML:
kubectl apply -f deploy/
Allowing Flux to access the repository
When it starts, Flux generates an SSH key
Display that key:
kubectl logs deployment/flux | grep identityThen add that key to the repository, giving it write access
(some Flux features require write access)
After a minute or so, DockerCoins will be deployed to the current namespace
Making changes
Make changes (on the
prodbranch), e.g. changereplicasinworkerAfter a few minutes, the changes will be picked up by Flux and applied
Other features
Flux can keep a list of all the tags of all the images we're running
The
fluxctltool can show us if we're running the latest imagesWe can also "automate" a resource (i.e. automatically deploy new images)
And much more!
Gitkube overview
We put our Kubernetes resources as YAML files in a git repository
Gitkube is a git server (or "git remote")
After making changes to the repository, we push to Gitkube
Gitkube applies the resources to the cluster
Setting up Gitkube
Install the CLI:
sudo curl -L -o /usr/local/bin/gitkube \https://github.com/hasura/gitkube/releases/download/v0.2.1/gitkube_linux_amd64sudo chmod +x /usr/local/bin/gitkubeInstall Gitkube on the cluster:
gitkube install --expose ClusterIP
Creating a Remote
Gitkube provides a new type of API resource: Remote
(this is using a mechanism called Custom Resource Definitions or CRD)
Create and apply a YAML file containing the following manifest:
apiVersion: gitkube.sh/v1alpha1kind: Remotemetadata:name: examplespec:authorizedKeys:- ssh-rsa AAA...manifests:path: "."(replace the
ssh-rsa AAA...section with the content of~/.ssh/id_rsa.pub)
Pushing to our remote
Get the
gitkubedIP address:kubectl -n kube-system get svc gitkubedIP=$(kubectl -n kube-system get svc gitkubed -o json |jq -r .spec.clusterIP)Get ourselves a sample repository with resource YAML files:
git clone git://github.com/jpetazzo/kubercoinscd kubercoinsAdd the remote and push to it:
git remote add k8s ssh://default-example@$IP/~/git/default-examplegit push k8s master
Making changes
Edit a local file
Commit
Push!
Make sure that you push to the
k8sremote
Other features
Gitkube can also build container images for us
(see the documentation for more details)
Gitkube can also deploy Helm charts
(instead of raw YAML files)
Building images with the Docker Engine
(automatically generated title slide)
Building images with the Docker Engine
Until now, we have built our images manually, directly on a node
We are going to show how to build images from within the cluster
(by executing code in a container controlled by Kubernetes)
We are going to use the Docker Engine for that purpose
To access the Docker Engine, we will mount the Docker socket in our container
After building the image, we will push it to our self-hosted registry
Resource specification for our builder pod
apiVersion: v1kind: Podmetadata: name: build-imagespec: restartPolicy: OnFailure containers: - name: docker-build image: docker env: - name: REGISTRY_PORT value: "3XXXX" command: ["sh", "-c"] args: - | apk add --no-cache git && mkdir /workspace && git clone https://github.com/jpetazzo/container.training /workspace && docker build -t localhost:$REGISTRY_PORT/worker /workspace/dockercoins/worker && docker push localhost:$REGISTRY_PORT/worker volumeMounts: - name: docker-socket mountPath: /var/run/docker.sock volumes: - name: docker-socket hostPath: path: /var/run/docker.sockBreaking down the pod specification (1/2)
restartPolicy: OnFailureprevents the build from running in an infinite lopoWe use the
dockerimage (so that thedockerCLI is available)We rely on the fact that the
dockerimage is based onalpine(which is why we use
apkto installgit)The port for the registry is passed through an environment variable
(this avoids repeating it in the specification, which would be error-prone)
The environment variable has to be a string, so the "s are mandatory!
Breaking down the pod specification (2/2)
The volume
docker-socketis declared with ahostPath, indicating a bind-mountIt is then mounted in the container onto the default Docker socket path
We show a interesting way to specify the commands to run in the container:
the command executed will be
sh -c <args>argsis a list of strings|is used to pass a multi-line string in the YAML file
Running our pod
- Let's try this out!
Check the port used by our self-hosted registry:
kubectl get svc registryEdit
~/container.training/k8s/docker-build.yamlto put the port numberSchedule the pod by applying the resource file:
kubectl apply -f ~/container.training/k8s/docker-build.yamlWatch the logs:
stern build-image
What's missing?
What do we need to change to make this production-ready?
Build from a long-running container (e.g. a
Deployment) triggered by web hooks(the payload of the web hook could indicate the repository to build)
Build a specific branch or tag; tag image accordingly
Handle repositories where the Dockerfile is not at the root
(or containing multiple Dockerfiles)
Expose build logs so that troubleshooting is straightforward
What's missing?
What do we need to change to make this production-ready?
Build from a long-running container (e.g. a
Deployment) triggered by web hooks(the payload of the web hook could indicate the repository to build)
Build a specific branch or tag; tag image accordingly
Handle repositories where the Dockerfile is not at the root
(or containing multiple Dockerfiles)
Expose build logs so that troubleshooting is straightforward
🤔 That seems like a lot of work!
What's missing?
What do we need to change to make this production-ready?
Build from a long-running container (e.g. a
Deployment) triggered by web hooks(the payload of the web hook could indicate the repository to build)
Build a specific branch or tag; tag image accordingly
Handle repositories where the Dockerfile is not at the root
(or containing multiple Dockerfiles)
Expose build logs so that troubleshooting is straightforward
🤔 That seems like a lot of work!
That's why services like Docker Hub (with automated builds) are helpful.
They handle the whole "code repository → Docker image" workflow.
Things to be aware of
This is talking directly to a node's Docker Engine to build images
It bypasses resource allocation mechanisms used by Kubernetes
(but you can use taints and tolerations to dedicate builder nodes)
Be careful not to introduce conflicts when naming images
(e.g. do not allow the user to specify the image names!)
Your builds are going to be fast
(because they will leverage Docker's caching system)
Building images with Kaniko
(automatically generated title slide)
Building images with Kaniko
Kaniko is an open source tool to build container images within Kubernetes
It can build an image using any standard Dockerfile
The resulting image can be pushed to a registry or exported as a tarball
It doesn't require any particular privilege
(and can therefore run in a regular container in a regular pod)
This combination of features is pretty unique
(most other tools use different formats, or require elevated privileges)
Kaniko in practice
Kaniko provides an "executor image",
gcr.io/kaniko-project/executorWhen running that image, we need to specify at least:
the path to the build context (=the directory with our Dockerfile)
the target image name (including the registry address)
Simplified example:
docker run \-v ...:/workspace gcr.io/kaniko-project/executor \--context=/workspace \--destination=registry:5000/image_name:image_tag
Running Kaniko in a Docker container
- Let's build the image for the DockerCoins
workerservice with Kaniko
Find the port number for our self-hosted registry:
kubectl get svc registryPORT=$(kubectl get svc registry -o json | jq .spec.ports[0].nodePort)Run Kaniko:
docker run --net host \-v ~/container.training/dockercoins/worker:/workspace \gcr.io/kaniko-project/executor \--context=/workspace \--destination=127.0.0.1:$PORT/worker-kaniko:latest
We use --net host so that we can connect to the registry over 127.0.0.1.
Running Kaniko in a Kubernetes pod
We need to mount or copy the build context to the pod
We are going to build straight from the git repository
(to avoid depending on files sitting on a node, outside of containers)
We need to
git clonethe repository before running KanikoWe are going to use two containers sharing a volume:
a first container to
git clonethe repository to the volumea second container to run Kaniko, using the content of the volume
However, we need the first container to be done before running the second one
🤔 How could we do that?
Init Containers to the rescue
A pod can have a list of
initContainersinitContainersare executed in the specified orderEach Init Container needs to complete (exit) successfully
If any Init Container fails (non-zero exit status) the pod fails
(what happens next depends on the pod's
restartPolicy)After all Init Containers have run successfully, normal
containersare startedWe are going to execute the
git cloneoperation in an Init Container
Our Kaniko builder pod
apiVersion: v1kind: Podmetadata: name: kaniko-buildspec: initContainers: - name: git-clone image: alpine command: ["sh", "-c"] args: - | apk add --no-cache git && git clone git://github.com/jpetazzo/container.training /workspace volumeMounts: - name: workspace mountPath: /workspace containers: - name: build-image image: gcr.io/kaniko-project/executor:latest args: - "--context=/workspace/dockercoins/rng" - "--insecure" - "--destination=registry:5000/rng-kaniko:latest" volumeMounts: - name: workspace mountPath: /workspace volumes: - name: workspaceExplanations
We define a volume named
workspace(using the defaultemptyDirprovider)That volume is mounted to
/workspacein both our containersThe
git-cloneInit Container installsgitand runsgit cloneThe
build-imagecontainer executes KanikoWe use our self-hosted registry DNS name (
registry)We add
--insecureto use plain HTTP to talk to the registry
Running our Kaniko builder pod
- The YAML for the pod is in
k8s/kaniko-build.yaml
Create the pod:
kubectl apply -f ~/container.training/k8s/kaniko-build.yamlWatch the logs:
stern kaniko
Discussion
What should we use? The Docker build technique shown earlier? Kaniko? Something else?
The Docker build technique is simple, and has the potential to be very fast
However, it doesn't play nice with Kubernetes resource limits
Kaniko plays nice with resource limits
However, it's slower (there is no caching at all)
The ultimate building tool will probably be Jessica Frazelle's img builder
(it depends on upstream changes that are not in Kubernetes 1.11.2 yet)
But ... is it all about speed? (No!)
The big picture
For starters: the Docker Hub automated builds are very easy to set up
link a GitHub repository with the Docker Hub
each time you push to GitHub, an image gets build on the Docker Hub
If this doesn't work for you: why?
too slow (I'm far from
us-east-1!) → consider using your cloud provider's registryI'm not using a cloud provider → ok, perhaps you need to self-host then
I need fancy features (e.g. CI) → consider something like GitLab
Building our own cluster
(automatically generated title slide)
Building our own cluster
Let's build our own cluster!
Perfection is attained not when there is nothing left to add, but when there is nothing left to take away. (Antoine de Saint-Exupery)
Our goal is to build a minimal cluster allowing us to:
- create a Deployment (with
kubectl runorkubectl create deployment) - expose it with a Service
- connect to that service
- create a Deployment (with
"Minimal" here means:
- smaller number of components
- smaller number of command-line flags
- smaller number of configuration files
Non-goals
For now, we don't care about security
For now, we don't care about scalability
For now, we don't care about high availability
All we care about is simplicity
Our environment
We will use the machine indicated as
dmuc1(this stands for "Dessine Moi Un Cluster" or "Draw Me A Sheep",
in homage to Saint-Exupery's "The Little Prince")This machine:
runs Ubuntu LTS
has Kubernetes, Docker, and etcd binaries installed
but nothing is running
Checking our environment
- Let's make sure we have everything we need first
Log into the
dmuc1machineGet root:
sudo -iCheck available versions:
etcd -versionkube-apiserver --versiondockerd --version
The plan
Start API server
Interact with it (create Deployment and Service)
See what's broken
Fix it and go back to step 2 until it works!
Dealing with multiple processes
We are going to start many processes
Depending on what you're comfortable with, you can:
open multiple windows and multiple SSH connections
use a terminal multiplexer like screen or tmux
put processes in the background with
&
(warning: log output might get confusing to read!)
Starting API server
- Try to start the API server:kube-apiserver# It will fail with "--etcd-servers must be specified"
Since the API server stores everything in etcd, it cannot start without it.
Starting etcd
- Try to start etcd:etcd
Success!
Note the last line of output:
serving insecure client requests on 127.0.0.1:2379, this is strongly discouraged!Sure, that's discouraged. But thanks for telling us the address!
Starting API server (for real)
Try again, passing the
--etcd-serversargumentThat argument should be a comma-separated list of URLs
- Start API server:kube-apiserver --etcd-servers http://127.0.0.1:2379
Success!
Interacting with API server
- Let's try a few "classic" commands
List nodes:
kubectl get nodesList services:
kubectl get services
We should get No resources found. and the kubernetes service, respectively.
Note: the API server automatically created the kubernetes service entry.
What about kubeconfig?
We didn't need to create a
kubeconfigfileBy default, the API server is listening on
localhost:8080(without requiring authentication)
By default,
kubectlconnects tolocalhost:8080(without providing authentication)
Creating a Deployment
- Let's run a web server!
- Create a Deployment with NGINX:kubectl create deployment web --image=nginx
Success?
Checking our Deployment status
- Look at pods, deployments, etc.:kubectl get all
Our Deployment is in bad shape:
NAME READY UP-TO-DATE AVAILABLE AGEdeployment.apps/web 0/1 0 0 2m26sAnd, there is no ReplicaSet, and no Pod.
What's going on?
We stored the definition of our Deployment in etcd
(through the API server)
But there is no controller to do the rest of the work
We need to start the controller manager
Starting the controller manager
- Try to start the controller manager:kube-controller-manager
The final error message is:
invalid configuration: no configuration has been providedBut the logs include another useful piece of information:
Neither --kubeconfig nor --master was specified.Using the inClusterConfig. This might not work.Reminder: everyone talks to API server
The controller manager needs to connect to the API server
It does not have a convenient
localhost:8080defaultWe can pass the connection information in two ways:
--masterand a host:port combination (easy)--kubeconfigand akubeconfigfile
For simplicity, we'll use the first option
Starting the controller manager (for real)
- Start the controller manager:kube-controller-manager --master http://localhost:8080
Success!
Checking our Deployment status
- Check all our resources again:kubectl get all
We now have a ReplicaSet.
But we still don't have a Pod.
What's going on?
In the controller manager logs, we should see something like this:
E0404 15:46:25.753376 22847 replica_set.go:450] Sync "default/web-5bc9bd5b8d"failed with No API token found for service account "default", retry after thetoken is automatically created and added to the service accountThe service account
defaultwas automatically added to our Deployment(and to its pods)
The service account
defaultexistsBut it doesn't have an associated token
(the token is a secret; creating it requires signature; therefore a CA)
Solving the missing token issue
There are many ways to solve that issue.
We are going to list a few (to get an idea of what's happening behind the scenes).
Of course, we don't need to perform all the solutions mentioned here.
Option 1: disable service accounts
Restart the API server with
--disable-admission-plugins=ServiceAccountThe API server will no longer add a service account automatically
Our pods will be created without a service account
Option 2: do not mount the (missing) token
Add
automountServiceAccountToken: falseto the Deployment specor
Add
automountServiceAccountToken: falseto the default ServiceAccountThe ReplicaSet controller will no longer create pods referencing the (missing) token
- Programmatically change the
defaultServiceAccount:kubectl patch sa default -p "automountServiceAccountToken: false"
Option 3: set up service accounts properly
This is the most complex option!
Generate a key pair
Pass the private key to the controller manager
(to generate and sign tokens)
Pass the public key to the API server
(to verify these tokens)
Continuing without service account token
- Once we patch the default service account, the ReplicaSet can create a Pod
- Check that we now have a pod:kubectl get all
Note: we might have to wait a bit for the ReplicaSet controller to retry.
If we're impatient, we can restart the controller manager.
What's next?
Our pod exists, but it is in
PendingstateRemember, we don't have a node so far
(
kubectl get nodesshows an empty list)We need to:
start a container engine
start kubelet
Starting a container engine
- We're going to use Docker (because it's the default option)
- Start the Docker Engine:dockerd
Success!
Feel free to check that it actually works with e.g.:
docker run alpine echo hello worldStarting kubelet
If we start kubelet without arguments, it will start
But it will not join the cluster!
It will start in standalone mode
Just like with the controller manager, we need to tell kubelet where the API server is
Alas, kubelet doesn't have a simple
--masteroptionWe have to use
--kubeconfigWe need to write a
kubeconfigfile for kubelet
Writing a kubeconfig file
We can copy/paste a bunch of YAML
Or we can generate the file with
kubectl
- Create the file
~/.kube/configwithkubectl:kubectl config \set-cluster localhost --server http://localhost:8080kubectl config \set-context localhost --cluster localhostkubectl config \use-context localhost
Our ~/.kube/config file
The file that we generated looks like the one below.
That one has been slightly simplified (removing extraneous fields), but it is still valid.
apiVersion: v1kind: Configcurrent-context: localhostcontexts:- name: localhost context: cluster: localhostclusters:- name: localhost cluster: server: http://localhost:8080Starting kubelet
- Start kubelet with that kubeconfig file:kubelet --kubeconfig ~/.kube/config
Success!
Looking at our 1-node cluster
- Let's check that our node registered correctly
- List the nodes in our cluster:kubectl get nodes
Our node should show up.
Its name will be its hostname (it should be dmuc1).
Are we there yet?
- Let's check if our pod is running
- List all resources:kubectl get all
Are we there yet?
- Let's check if our pod is running
- List all resources:kubectl get all
Our pod is still Pending. 🤔
Are we there yet?
- Let's check if our pod is running
- List all resources:kubectl get all
Our pod is still Pending. 🤔
Which is normal: it needs to be scheduled.
(i.e., something needs to decide which node it should go on.)
Scheduling our pod
Why do we need a scheduling decision, since we have only one node?
The node might be full, unavailable; the pod might have constraints ...
The easiest way to schedule our pod is to start the scheduler
(we could also schedule it manually)
Starting the scheduler
The scheduler also needs to know how to connect to the API server
Just like for controller manager, we can use
--kubeconfigor--master
- Start the scheduler:kube-scheduler --master http://localhost:8080
- Our pod should now start correctly
Checking the status of our pod
Our pod will go through a short
ContainerCreatingphaseThen it will be
Running
- Check pod status:kubectl get pods
Success!
Scheduling a pod manually
We can schedule a pod in
Pendingstate by creating a Binding, e.g.:kubectl create -f- <<EOFapiVersion: v1kind: Bindingmetadata:name: name-of-the-podtarget:apiVersion: v1kind: Nodename: name-of-the-nodeEOFThis is actually how the scheduler works!
It watches pods, makes scheduling decisions, and creates Binding objects
Connecting to our pod
- Let's check that our pod correctly runs NGINX
Check our pod's IP address:
kubectl get pods -o wideSend some HTTP request to the pod:
curl X.X.X.X
We should see the Welcome to nginx! page.
Exposing our Deployment
- We can now create a Service associated with this Deployment
Expose the Deployment's port 80:
kubectl expose deployment web --port=80Check the Service's ClusterIP, and try connecting:
kubectl get service webcurl http://X.X.X.X
Exposing our Deployment
- We can now create a Service associated with this Deployment
Expose the Deployment's port 80:
kubectl expose deployment web --port=80Check the Service's ClusterIP, and try connecting:
kubectl get service webcurl http://X.X.X.X
This won't work. We need kube-proxy to enable internal communication.
Starting kube-proxy
kube-proxy also needs to connect to the API server
It can work with the
--masterflag(although that will be deprecated in the future)
- Start kube-proxy:kube-proxy --master http://localhost:8080
Connecting to our Service
- Now that kube-proxy is running, we should be able to connect
- Check the Service's ClusterIP again, and retry connecting:kubectl get service webcurl http://X.X.X.X
Success!
How kube-proxy works
kube-proxy watches Service resources
When a Service is created or updated, kube-proxy creates iptables rules
Check out the
OUTPUTchain in thenattable:iptables -t nat -L OUTPUTTraffic is sent to
KUBE-SERVICES; check that too:iptables -t nat -L KUBE-SERVICES
For each Service, there is an entry in that chain.
Diving into iptables
- The last command showed a chain named
KUBE-SVC-...corresponding to our service
Check that
KUBE-SVC-...chain:iptables -t nat -L KUBE-SVC-...It should show a jump to a
KUBE-SEP-...chains; check it out too:iptables -t nat -L KUBE-SEP-...
This is a DNAT rule to rewrite the destination address of the connection to our pod.
This is how kube-proxy works!
kube-router, IPVS
With recent versions of Kubernetes, it is possible to tell kube-proxy to use IPVS
IPVS is a more powerful load balancing framework
(remember: iptables was primarily designed for firewalling, not load balancing!)
It is also possible to replace kube-proxy with kube-router
kube-router uses IPVS by default
kube-router can also perform other functions
(e.g., we can use it as a CNI plugin to provide pod connectivity)
What about the kubernetes service?
If we try to connect, it won't work
(by default, it should be
10.0.0.1)If we look at the Endpoints for this service, we will see one endpoint:
host-address:6443By default, the API server expects to be running directly on the nodes
(it could be as a bare process, or in a container/pod using the host network)
... And it expects to be listening on port 6443 with TLS
Adding nodes to the cluster
(automatically generated title slide)
Adding nodes to the cluster
So far, our cluster has only 1 node
Let's see what it takes to add more nodes
We are going to use another set of machines:
kubenet
The environment
We have 3 identical machines:
kubenet1,kubenet2,kubenet3The Docker Engine is installed (and running) on these machines
The Kubernetes packages are installed, but nothing is running
We will use
kubenet1to run the control plane
The plan
Start the control plane on
kubenet1Join the 3 nodes to the cluster
Deploy and scale a simple web server
- Log into
kubenet1
Running the control plane
- We will use a Compose file to start the control plane components
Clone the repository containing the workshop materials:
git clone https://github.com/BretFisher/kubernetes-masteryGo to the
compose/simple-k8s-control-planedirectory:cd container.training/compose/simple-k8s-control-planeStart the control plane:
docker-compose up
Checking the control plane status
- Before moving on, verify that the control plane works
Show control plane component statuses:
kubectl get componentstatuseskubectl get csShow the (empty) list of nodes:
kubectl get nodes
Differences from dmuc
Our new control plane listens on
0.0.0.0instead of the default127.0.0.1The ServiceAccount admission plugin is disabled
Joining the nodes
We need to generate a
kubeconfigfile for kubeletThis time, we need to put the public IP address of
kubenet1(instead of
localhostor127.0.0.1)
- Generate the
kubeconfigfile:kubectl config set-cluster kubenet --server http://X.X.X.X:8080kubectl config set-context kubenet --cluster kubenetkubectl config use-context kubenetcp ~/.kube/config ~/kubeconfig
Distributing the kubeconfig file
- We need that
kubeconfigfile on the other nodes, too
- Copy
kubeconfigto the other nodes:for N in 2 3; doscp ~/kubeconfig kubenet$N:done
Starting kubelet
- Reminder: kubelet needs to run as root; don't forget
sudo!
Join the first node:
sudo kubelet --kubeconfig ~/kubeconfigOpen more terminals and join the other nodes to the cluster:
ssh kubenet2 sudo kubelet --kubeconfig ~/kubeconfigssh kubenet3 sudo kubelet --kubeconfig ~/kubeconfig
Checking cluster status
We should now see all 3 nodes
At first, their
STATUSwill beNotReadyThey will move to
Readystate after approximately 10 seconds
- Check the list of nodes:kubectl get nodes
Deploy a web server
Let's create a Deployment and scale it
(so that we have multiple pods on multiple nodes)
Create a Deployment running NGINX:
kubectl create deployment web --image=nginxScale it:
kubectl scale deployment web --replicas=5
Check our pods
The pods will be scheduled on the nodes
The nodes will pull the
nginximage, and start the podsWhat are the IP addresses of our pods?
- Check the IP addresses of our podskubectl get pods -o wide
Check our pods
The pods will be scheduled on the nodes
The nodes will pull the
nginximage, and start the podsWhat are the IP addresses of our pods?
- Check the IP addresses of our podskubectl get pods -o wide
🤔 Something's not right ... Some pods have the same IP address!
What's going on?
Without the
--network-pluginflag, kubelet defaults to "no-op" networkingIt lets the container engine use a default network
(in that case, we end up with the default Docker bridge)
Our pods are running on independent, disconnected, host-local networks
What do we need to do?
On a normal cluster, kubelet is configured to set up pod networking with CNI plugins
This requires:
installing CNI plugins
writing CNI configuration files
running kubelet with
--network-plugin=cni
Using network plugins
We need to set up a better network
Before diving into CNI, we will use the
kubenetpluginThis plugin creates a
cbr0bridge and connects the containers to that bridgeThis plugin allocates IP addresses from a range:
either specified to kubelet (e.g. with
--pod-cidr)or stored in the node's
spec.podCIDRfield
See here for more details about this kubenet plugin.
k8s/multinode.md
What kubenet does and does not do
It allocates IP addresses to pods locally
(each node has its own local subnet)
It connects the pods to a local bridge
(pods on the same node can communicate together; not with other nodes)
It doesn't set up routing or tunneling
(we get pods on separated networks; we need to connect them somehow)
It doesn't allocate subnets to nodes
(this can be done manually, or by the controller manager)
Setting up routing or tunneling
On each node, we will add routes to the other nodes' pod network
Of course, this is not convenient or scalable!
We will see better techniques to do this; but for now, hang on!
Allocating subnets to nodes
There are multiple options:
passing the subnet to kubelet with the
--pod-cidrflagmanually setting
spec.podCIDRon each nodeallocating node CIDRs automatically with the controller manager
The last option would be implemented by adding these flags to controller manager:
--allocate-node-cidrs=true --cluster-cidr=<cidr>
The pod CIDR field is not mandatory
kubenetneeds the pod CIDR, but other plugins don't need it(e.g. because they allocate addresses in multiple pools, or a single big one)
The pod CIDR field may eventually be deprecated and replaced by an annotation
Restarting kubelet wih pod CIDR
We need to stop and restart all our kubelets
We will add the
--network-pluginand--pod-cidrflagsWe all have a "cluster number" (let's call that
C) printed on your VM info cardWe will use pod CIDR
10.C.N.0/24(whereNis the node number: 1, 2, 3)
Stop all the kubelets (Ctrl-C is fine)
Restart them all, adding
--network-plugin=kubenet --pod-cidr 10.C.N.0/24
What happens to our pods?
When we stop (or kill) kubelet, the containers keep running
When kubelet starts again, it detects the containers
- Check that our pods are still here:kubectl get pods -o wide
🤔 But our pods still use local IP addresses!
Recreating the pods
The IP address of a pod cannot change
kubelet doesn't automatically kill/restart containers with "invalid" addresses
(in fact, from kubelet's point of view, there is no such thing as an "invalid" address)We must delete our pods and recreate them
Delete all the pods, and let the ReplicaSet recreate them:
kubectl delete pods --allWait for the pods to be up again:
kubectl get pods -o wide -w
Adding kube-proxy
Let's start kube-proxy to provide internal load balancing
Then see if we can create a Service and use it to contact our pods
Start kube-proxy:
sudo kube-proxy --kubeconfig ~/.kube/configExpose our Deployment:
kubectl expose deployment web --port=80
Test internal load balancing
Retrieve the ClusterIP address:
kubectl get svc webSend a few requests to the ClusterIP address (with
curl)
Test internal load balancing
Retrieve the ClusterIP address:
kubectl get svc webSend a few requests to the ClusterIP address (with
curl)
Sometimes it works, sometimes it doesn't. Why?
Routing traffic
Our pods have new, distinct IP addresses
But they are on host-local, isolated networks
If we try to ping a pod on a different node, it won't work
kube-proxy merely rewrites the destination IP address
But we need that IP address to be reachable in the first place
How do we fix this?
(hint: check the title of this slide!)
Important warning
The technique that we are about to use doesn't work everywhere
It only works if:
all the nodes are directly connected to each other (at layer 2)
the underlying network allows the IP addresses of our pods
If we are on physical machines connected by a switch: OK
If we are on virtual machines in a public cloud: NOT OK
on AWS, we need to disable "source and destination checks" on our instances
on OpenStack, we need to disable "port security" on our network ports
Routing basics
We need to tell each node:
"The subnet 10.C.N.0/24 is located on node N" (for all values of N)
This is how we add a route on Linux:
ip route add 10.C.N.0/24 via W.X.Y.Z(where
W.X.Y.Zis the internal IP address of node N)We can see the internal IP addresses of our nodes with:
kubectl get nodes -o wide
Firewalling
By default, Docker prevents containers from using arbitrary IP addresses
(by setting up iptables rules)
We need to allow our containers to use our pod CIDR
For simplicity, we will insert a blanket iptables rule allowing all traffic:
iptables -I FORWARD -j ACCEPTThis has to be done on every node
Setting up routing
Create all the routes on all the nodes
Insert the iptables rule allowing traffic
Check that you can ping all the pods from one of the nodes
Check that you can
curlthe ClusterIP of the Service successfully
What's next?
We did a lot of manual operations:
allocating subnets to nodes
adding command-line flags to kubelet
updating the routing tables on our nodes
We want to automate all these steps
We want something that works on all networks
API server availability
(automatically generated title slide)
API server availability
When we set up a node, we need the address of the API server:
for kubelet
for kube-proxy
sometimes for the pod network system (like kube-router)
How do we ensure the availability of that endpoint?
(what if the node running the API server goes down?)
Option 1: external load balancer
Set up an external load balancer
Point kubelet (and other components) to that load balancer
Put the node(s) running the API server behind that load balancer
Update the load balancer if/when an API server node needs to be replaced
On cloud infrastructures, some mechanisms provide automation for this
(e.g. on AWS, an Elastic Load Balancer + Auto Scaling Group)
Option 2: local load balancer
Set up a load balancer (like NGINX, HAProxy...) on each node
Configure that load balancer to send traffic to the API server node(s)
Point kubelet (and other components) to
localhostUpdate the load balancer configuration when API server nodes are updated
Updating the local load balancer config
Distribute the updated configuration (push)
Or regularly check for updates (pull)
The latter requires an external, highly available store
(it could be an object store, an HTTP server, or even DNS...)
Updates can be facilitated by a DaemonSet
(but remember that it can't be used when installing a new node!)
Option 3: DNS records
Put all the API server nodes behind a round-robin DNS
Point kubelet (and other components) to that name
Update the records when needed
Note: this option is not officially supported
(but since kubelet supports reconnection anyway, it should work)
Option 4: ....................
Many managed clusters expose a high-availability API endpoint
(and you don't have to worry about it)
You can also use HA mechanisms that you're familiar with
(e.g. virtual IPs)
Tunnels are also fine
(e.g. k3s uses a tunnel to allow each node to contact the API server)
Static pods
(automatically generated title slide)
Static pods
Hosting the Kubernetes control plane on Kubernetes has advantages:
we can use Kubernetes' replication and scaling features for the control plane
we can leverage rolling updates to upgrade the control plane
However, there is a catch:
deploying on Kubernetes requires the API to be available
the API won't be available until the control plane is deployed
How can we get out of that chicken-and-egg problem?
A possible approach
Since each component of the control plane can be replicated...
We could set up the control plane outside of the cluster
Then, once the cluster is fully operational, create replicas running on the cluster
Finally, remove the replicas that are running outside of the cluster
What could possibly go wrong?
Sawing off the branch you're sitting on
What if anything goes wrong?
(During the setup or at a later point)
Worst case scenario, we might need to:
set up a new control plane (outside of the cluster)
restore a backup from the old control plane
move the new control plane to the cluster (again)
This doesn't sound like a great experience
Static pods to the rescue
Pods are started by kubelet (an agent running on every node)
To know which pods it should run, the kubelet queries the API server
The kubelet can also get a list of static pods from:
a directory containing one (or multiple) manifests, and/or
a URL (serving a manifest)
These "manifests" are basically YAML definitions
(As produced by
kubectl get pod my-little-pod -o yaml)
Static pods are dynamic
Kubelet will periodically reload the manifests
It will start/stop pods accordingly
(i.e. it is not necessary to restart the kubelet after updating the manifests)
When connected to the Kubernetes API, the kubelet will create mirror pods
Mirror pods are copies of the static pods
(so they can be seen with e.g.
kubectl get pods)
Bootstrapping a cluster with static pods
We can run control plane components with these static pods
They can start without requiring access to the API server
Once they are up and running, the API becomes available
These pods are then visible through the API
(We cannot upgrade them from the API, though)
This is how kubeadm has initialized our clusters.
Static pods vs normal pods
The API only gives us read-only access to static pods
We can
kubectl deletea static pod......But the kubelet will re-mirror it immediately
Static pods can be selected just like other pods
(So they can receive service traffic)
A service can select a mixture of static and other pods
From static pods to normal pods
Once the control plane is up and running, it can be used to create normal pods
We can then set up a copy of the control plane in normal pods
Then the static pods can be removed
The scheduler and the controller manager use leader election
(Only one is active at a time; removing an instance is seamless)
Each instance of the API server adds itself to the
kubernetesserviceEtcd will typically require more work!
From normal pods back to static pods
Alright, but what if the control plane is down and we need to fix it?
We restart it using static pods!
This can be done automatically with the Pod Checkpointer
The Pod Checkpointer automatically generates manifests of running pods
The manifests are used to restart these pods if API contact is lost
(More details in the Pod Checkpointer documentation page)
This technique is used by bootkube k8s/staticpods.md
Where should the control plane run?
Is it better to run the control plane in static pods, or normal pods?
If I'm a user of the cluster: I don't care, it makes no difference to me
What if I'm an admin, i.e. the person who installs, upgrades, repairs... the cluster?
If I'm using a managed Kubernetes cluster (AKS, EKS, GKE...) it's not my problem
(I'm not the one setting up and managing the control plane)
If I already picked a tool (kubeadm, kops...) to set up my cluster, the tool decides for me
What if I haven't picked a tool yet, or if I'm installing from scratch?
static pods = easier to set up, easier to troubleshoot, less risk of outage
normal pods = easier to upgrade, easier to move (if nodes need to be shut down)
Static pods in action
- On our clusters, the
staticPodPathis/etc/kubernetes/manifests
- Have a look at this directory:ls -l /etc/kubernetes/manifests
We should see YAML files corresponding to the pods of the control plane.
Running a static pod
- We are going to add a pod manifest to the directory, and kubelet will run it
Copy a manifest to the directory:
sudo cp ~/container.training/k8s/just-a-pod.yaml /etc/kubernetes/manifestsCheck that it's running:
kubectl get pods
The output should include a pod named hello-node1.
Remarks
In the manifest, the pod was named hello.
apiVersion: v1kind: Podmetadata: name: hello namespace: defaultspec: containers: - name: hello image: nginxThe -node1 suffix was added automatically by kubelet.
If we delete the pod (with kubectl delete), it will be recreated immediately.
To delete the pod, we need to delete (or move) the manifest file.
Owners and dependents
Some objects are created by other objects
(example: pods created by replica sets, themselves created by deployments)
When an owner object is deleted, its dependents are deleted
(this is the default behavior; it can be changed)
We can delete a dependent directly if we want
(but generally, the owner will recreate another right away)
An object can have multiple owners
Finding out the owners of an object
- The owners are recorded in the field
ownerReferencesin themetadatablock
Let's create a deployment running
nginx:kubectl create deployment yanginx --image=nginxScale it to a few replicas:
kubectl scale deployment yanginx --replicas=3Once it's up, check the corresponding pods:
kubectl get pods -l app=yanginx -o yaml | head -n 25
These pods are owned by a ReplicaSet named yanginx-xxxxxxxxxx.
Listing objects with their owners
- This is a good opportunity to try the
custom-columnsoutput!
- Show all pods with their owners:kubectl get pod -o custom-columns=\NAME:.metadata.name,\OWNER-KIND:.metadata.ownerReferences[0].kind,\OWNER-NAME:.metadata.ownerReferences[0].name
Note: the custom-columns option should be one long option (without spaces),
so the lines should not be indented (otherwise the indentation will insert spaces).
Deletion policy
When deleting an object through the API, three policies are available:
foreground (API call returns after all dependents are deleted)
background (API call returns immediately; dependents are scheduled for deletion)
orphan (the dependents are not deleted)
When deleting an object with
kubectl, this is selected with--cascade:--cascade=truedeletes all dependent objects (default)--cascade=falseorphans dependent objects
What happens when an object is deleted
It is removed from the list of owners of its dependents
If, for one of these dependents, the list of owners becomes empty ...
if the policy is "orphan", the object stays
otherwise, the object is deleted
Orphaning pods
We are going to delete the Deployment and Replica Set that we created
... without deleting the corresponding pods!
Delete the Deployment:
kubectl delete deployment -l app=yanginx --cascade=falseDelete the Replica Set:
kubectl delete replicaset -l app=yanginx --cascade=falseCheck that the pods are still here:
kubectl get pods
When and why would we have orphans?
If we remove an owner and explicitly instruct the API to orphan dependents
(like on the previous slide)
If we change the labels on a dependent, so that it's not selected anymore
(e.g. change the
app: yanginxin the pods of the previous example)If a deployment tool that we're using does these things for us
If there is a serious problem within API machinery or other components
(i.e. "this should not happen")
Finding orphan objects
We're going to output all pods in JSON format
Then we will use
jqto keep only the ones without an ownerAnd we will display their name
- List all pods that do not have an owner:kubectl get pod -o json | jq -r ".items[]| select(.metadata.ownerReferences|not)| .metadata.name"
Deleting orphan pods
- Now that we can list orphan pods, deleting them is easy
- Add
| xargs kubectl delete podto the previous command:kubectl get pod -o json | jq -r ".items[]| select(.metadata.ownerReferences|not)| .metadata.name" | xargs kubectl delete pod
As always, the documentation has useful extra information and pointers.
Exposing HTTP services with Ingress resources
Services give us a way to access a pod or a set of pods
Services can be exposed to the outside world:
with type
NodePort(on a port >30000)with type
LoadBalancer(allocating an external load balancer)
What about HTTP services?
how can we expose
webui,rng,hasher?the Kubernetes dashboard?
a new version of
webui?
Exposing HTTP services
If we use
NodePortservices, clients have to specify port numbers(i.e. http://xxxxx:31234 instead of just http://xxxxx)
LoadBalancerservices are nice, but:they are not available in all environments
they often carry an additional cost (e.g. they provision an ELB)
They often work at OSI Layer 4 (IP+Port) and not Layer 7 (HTTP/S)
they require one extra step for DNS integration
(waiting for theLoadBalancerto be provisioned; then adding it to DNS)
We could build our own reverse proxy
Building a custom reverse proxy
There are many options available:
Apache, HAProxy, Envoy, NGINX, Traefik, ...
Most of these options require us to update/edit configuration files after each change
Some of them can pick up virtual hosts and backends from a configuration store
Wouldn't it be nice if this configuration could be managed with the Kubernetes API?
Building a custom reverse proxy
There are many options available:
Apache, HAProxy, Envoy, NGINX, Traefik, ...
Most of these options require us to update/edit configuration files after each change
Some of them can pick up virtual hosts and backends from a configuration store
Wouldn't it be nice if this configuration could be managed with the Kubernetes API?
Enter¹ Ingress resources!
¹ Pun maybe intended.
Ingress resources
Kubernetes API resource (
kubectl get ingress/ingresses/ing)Designed to expose HTTP services
Basic features:
- load balancing
- SSL termination
- name-based virtual hosting
Can also route to different services depending on:
- URI path (e.g.
/api→api-service,/static→assets-service) - Client headers, including cookies (for A/B testing, canary deployment...)
- and more!
- URI path (e.g.
Principle of operation
Step 1: deploy an ingress controller
ingress controller = load balancer + control loop
the control loop watches over ingress resources, and configures the LB accordingly
Step 2: set up DNS
- associate DNS entries with the load balancer address
Step 3: create ingress resources
- the ingress controller picks up these resources and configures the LB
Step 4: profit!
Ingress in action
We will deploy the Traefik ingress controller
this is an arbitrary choice, the docs list over a dozen options
maybe motivated by the fact that Traefik releases are named after cheeses
For DNS, we will use nip.io
*.1.2.3.4.nip.ioresolves to1.2.3.4
We will create ingress resources for various HTTP services
Deploying pods listening on port 80
We want our ingress load balancer to be available on port 80
We could do that with a
LoadBalancerservice... but it requires support from the underlying infrastructure
We could use pods specifying
hostPort: 80... but with most CNI plugins, this doesn't work or requires additional setup
We could use a
NodePortservice... but that requires changing the
--service-node-port-rangeflag in the API serverLast resort: the
hostNetworkmode
Without hostNetwork
Normally, each pod gets its own network namespace
(sometimes called sandbox or network sandbox)
An IP address is assigned to the pod
This IP address is routed/connected to the cluster network
All containers of that pod are sharing that network namespace
(and therefore using the same IP address)
With hostNetwork: true
No network namespace gets created
The pod is using the network namespace of the host
It "sees" (and can use) the interfaces (and IP addresses) of the host
The pod can receive outside traffic directly, on any port
Downside: with most network plugins, network policies won't work for that pod
most network policies work at the IP address level
filtering that pod = filtering traffic from the node
Running Traefik
The Traefik documentation tells us to pick between Deployment and Daemon Set
We are going to use a Daemon Set so that each node can accept connections
We will do two minor changes to the YAML provided by Traefik:
enable
hostNetworkadd a toleration so that Traefik also runs on
node1
Taints and tolerations
A taint is an attribute added to a node
It prevents pods from running on the node
... Unless they have a matching toleration
When deploying with
kubeadm:a taint is placed on the node dedicated to the control plane
the pods running the control plane have a matching toleration
Checking taints on our nodes
- Check our nodes specs:kubectl get node node1 -o json | jq .speckubectl get node node2 -o json | jq .spec
We should see a result only for node1 (the one with the control plane):
"taints": [ { "effect": "NoSchedule", "key": "node-role.kubernetes.io/master" } ]Understanding a taint
The
keycan be interpreted as:a reservation for a special set of pods
(here, this means "this node is reserved for the control plane")an error condition on the node
(for instance: "disk full," do not start new pods here!)
The
effectcan be:NoSchedule(don't run new pods here)PreferNoSchedule(try not to run new pods here)NoExecute(don't run new pods and evict running pods)
Checking tolerations on the control plane
- Check tolerations for CoreDNS:kubectl -n kube-system get deployments coredns -o json |jq .spec.template.spec.tolerations
The result should include:
{ "effect": "NoSchedule", "key": "node-role.kubernetes.io/master" }It means: "bypass the exact taint that we saw earlier on node1."
Special tolerations
- Check tolerations on
kube-proxy:kubectl -n kube-system get ds kube-proxy -o json |jq .spec.template.spec.tolerations
The result should include:
{ "operator": "Exists" }This one is a special case that means "ignore all taints and run anyway."
Running Traefik on our cluster
We provide a YAML file (
k8s/traefik.yaml) which is essentially the sum of:Traefik's Daemon Set resources (patched with
hostNetworkand tolerations)Traefik's RBAC rules allowing it to watch necessary API objects
- Apply the YAML:kubectl apply -f ~/container.training/k8s/traefik.yaml
Checking that Traefik runs correctly
- If Traefik started correctly, we now have a web server listening on each node
- Check that Traefik is serving 80/tcp:curl localhost
We should get a 404 page not found error.
This is normal: we haven't provided any ingress rule yet.
Setting up DNS
To make our lives easier, we will use nip.io
Check out
http://cheddar.A.B.C.D.nip.io(replacing A.B.C.D with the IP address of
node1)We should get the same
404 page not founderror(meaning that our DNS is "set up properly", so to speak!)
Traefik web UI
Traefik provides a web dashboard
With the current install method, it's listening on port 8080
- Go to
http://node1:8080(replacingnode1with its IP address)
Setting up host-based routing ingress rules
We are going to use
bretfisher/cheeseimages(there are 3 tags available: wensleydale, cheddar, stilton)
These images contain a simple static HTTP server sending a picture of cheese
We will run 3 deployments (one for each cheese)
We will create 3 services (one for each deployment)
Then we will create 3 ingress rules (one for each service)
We will route
<name-of-cheese>.A.B.C.D.nip.ioto the corresponding deployment
Running cheesy web servers
Run all three deployments:
kubectl create deployment cheddar --image=bretfisher/cheese:cheddarkubectl create deployment stilton --image=bretfisher/cheese:stiltonkubectl create deployment wensleydale --image=bretfisher/cheese:wensleydaleCreate a service for each of them:
kubectl expose deployment cheddar --port=80kubectl expose deployment stilton --port=80kubectl expose deployment wensleydale --port=80
What does an ingress resource look like?
Here is a minimal host-based ingress resource:
apiVersion: networking.k8s.io/v1beta1kind: Ingressmetadata: name: cheddarspec: rules: - host: cheddar.A.B.C.D.nip.io http: paths: - path: / backend: serviceName: cheddar servicePort: 80(It is in k8s/ingress.yaml.)
Creating our first ingress resources
Edit the file
~/container.training/k8s/ingress.yamlReplace A.B.C.D with the IP address of
node1Apply the file
(An image of a piece of cheese should show up.)
Creating the other ingress resources
Edit the file
~/container.training/k8s/ingress.yamlReplace
cheddarwithstilton(inname,host,serviceName)Apply the file
Check that
stilton.A.B.C.D.nip.ioworks correctlyRepeat for
wensleydale
Using multiple ingress controllers
You can have multiple ingress controllers active simultaneously
(e.g. Traefik and NGINX)
You can even have multiple instances of the same controller
(e.g. one for internal, another for external traffic)
The
kubernetes.io/ingress.classannotation can be used to tell which one to useIt's OK if multiple ingress controllers configure the same resource
(it just means that the service will be accessible through multiple paths)
Ingress: the good
The traffic flows directly from the ingress load balancer to the backends
it doesn't need to go through the
ClusterIPin fact, we don't even need a
ClusterIP(we can use a headless service)
The load balancer can be outside of Kubernetes
(as long as it has access to the cluster subnet)
This allows the use of external (hardware, physical machines...) load balancers
Annotations can encode special features
(rate-limiting, A/B testing, session stickiness, etc.)
Ingress: the bad
Aforementioned "special features" are not standardized yet
Some controllers will support them; some won't
Even relatively common features (stripping a path prefix) can differ:
This should eventually stabilize
(remember that ingresses are currently
apiVersion: networking.k8s.io/v1beta1)
Upgrading clusters
(automatically generated title slide)
Upgrading clusters
It's recommended to run consistent versions across a cluster
(mostly to have feature parity and latest security updates)
It's not mandatory
(otherwise, cluster upgrades would be a nightmare!)
Components can be upgraded one at a time without problems
Checking what we're running
- It's easy to check the version for the API server
Log into node
test1Check the version of kubectl and of the API server:
kubectl version
In a HA setup with multiple API servers, they can have different versions
Running the command above multiple times can return different values
Node versions
- It's also easy to check the version of kubelet
- Check node versions (includes kubelet, kernel, container engine):kubectl get nodes -o wide
Different nodes can run different kubelet versions
Different nodes can run different kernel versions
Different nodes can run different container engines
Control plane versions
- If the control plane is self-hosted (running in pods), we can check it
- Show image versions for all pods in
kube-systemnamespace:kubectl --namespace=kube-system get pods -o json \| jq -r '.items[]| [.spec.nodeName, .metadata.name]+(.spec.containers[].image | split(":"))| @tsv' \| column -t
What version are we running anyway?
When I say, "I'm running Kubernetes 1.15", is that the version of:
kubectl
API server
kubelet
controller manager
something else?
Other versions that are important
etcd
kube-dns or CoreDNS
CNI plugin(s)
Network controller, network policy controller
Container engine
Linux kernel
General guidelines
To update a component, use whatever was used to install it
If it's a distro package, update that distro package
If it's a container or pod, update that container or pod
If you used configuration management, update with that
Know where your binaries come from
Sometimes, we need to upgrade quickly
(when a vulnerability is announced and patched)
If we are using an installer, we should:
make sure it's using upstream packages
or make sure that whatever packages it uses are current
make sure we can tell it to pin specific component versions
Important questions
Should we upgrade the control plane before or after the kubelets?
Within the control plane, should we upgrade the API server first or last?
How often should we upgrade?
How long are versions maintained?
All the answers are in the documentation about version skew policy!
Let's review the key elements together ...
Kubernetes uses semantic versioning
Kubernetes versions look like MAJOR.MINOR.PATCH; e.g. in 1.17.2:
- MAJOR = 1
- MINOR = 17
- PATCH = 2
It's always possible to mix and match different PATCH releases
(e.g. 1.16.1 and 1.16.6 are compatible)
It is recommended to run the latest PATCH release
(but it's mandatory only when there is a security advisory)
Version skew
API server must be more recent than its clients (kubelet and control plane)
... Which means it must always be upgraded first
All components support a difference of one¹ MINOR version
This allows live upgrades (since we can mix e.g. 1.15 and 1.16)
It also means that going from 1.14 to 1.16 requires going through 1.15
¹Except kubelet, which can be up to two MINOR behind API server, and kubectl, which can be one MINOR ahead or behind API server.
Release cycle
There is a new PATCH relese whenever necessary
(every few weeks, or "ASAP" when there is a security vulnerability)
There is a new MINOR release every 3 months (approximately)
At any given time, three MINOR releases are maintained
... Which means that MINOR releases are maintained approximately 9 months
We should expect to upgrade at least every 3 months (on average)
In practice
We are going to update a few cluster components
We will change the kubelet version on one node
We will change the version of the API server
We will work with cluster
test(nodestest1,test2,test3)
Updating the API server
This cluster has been deployed with kubeadm
The control plane runs in static pods
These pods are started automatically by kubelet
(even when kubelet can't contact the API server)
They are defined in YAML files in
/etc/kubernetes/manifests(this path is set by a kubelet command-line flag)
kubelet automatically updates the pods when the files are changed
Changing the API server version
- We will edit the YAML file to use a different image version
Log into node
test1Check API server version:
kubectl versionEdit the API server pod manifest:
sudo vim /etc/kubernetes/manifests/kube-apiserver.yamlLook for the
image:line, and update it to e.g.v1.16.0
Checking what we've done
- The API server will be briefly unavailable while kubelet restarts it
- Check the API server version:kubectl version
Was that a good idea?
Was that a good idea?
No!
Was that a good idea?
No!
Remember the guideline we gave earlier:
To update a component, use whatever was used to install it.
This control plane was deployed with kubeadm
We should use kubeadm to upgrade it!
Updating the whole control plane
Let's make it right, and use kubeadm to upgrade the entire control plane
(note: this is possible only because the cluster was installed with kubeadm)
- Check what will be upgraded:sudo kubeadm upgrade plan
Note 1: kubeadm thinks that our cluster is running 1.16.0.
It is confused by our manual upgrade of the API server!
Note 2: kubeadm itself is still version 1.15.9.
It doesn't know how to upgrade do 1.16.X.
Upgrading kubeadm
- First things first: we need to upgrade kubeadm
Upgrade kubeadm:
sudo apt install kubeadmCheck what kubeadm tells us:
sudo kubeadm upgrade plan
Problem: kubeadm doesn't know know how to handle upgrades from version 1.15.
This is because we installed version 1.17 (or even later).
We need to install kubeadm version 1.16.X.
Downgrading kubeadm
- We need to go back to version 1.16.X (e.g. 1.16.6)
View available versions for package
kubeadm:apt show kubeadm -a | grep ^Version | grep 1.16Downgrade kubeadm:
sudo apt install kubeadm=1.16.6-00Check what kubeadm tells us:
sudo kubeadm upgrade plan
kubeadm should now agree to upgrade to 1.16.6.
Upgrading the cluster with kubeadm
Ideally, we should revert our
image:change(so that kubeadm executes the right migration steps)
Or we can try the upgrade anyway
- Perform the upgrade:sudo kubeadm upgrade apply v1.16.6
Updating kubelet
These nodes have been installed using the official Kubernetes packages
We can therefore use
aptorapt-get
Log into node
test3View available versions for package
kubelet:apt show kubelet -a | grep ^VersionUpgrade kubelet:
sudo apt install kubelet=1.16.6-00
Checking what we've done
Log into node
test1Check node versions:
kubectl get nodes -o wideCreate a deployment and scale it to make sure that the node still works
Was that a good idea?
Was that a good idea?
Almost!
Was that a good idea?
Almost!
Yes, kubelet was installed with distribution packages
However, kubeadm took care of configuring kubelet
(when doing
kubeadm join ...)We were supposed to run a special command before upgrading kubelet!
That command should be executed on each node
It will download the kubelet configuration generated by kubeadm
Upgrading kubelet the right way
We need to upgrade kubeadm, upgrade kubelet config, then upgrade kubelet
(after upgrading the control plane)
- Download the configuration on each node, and upgrade kubelet:for N in 1 2 3; dossh test$N "sudo apt install kubeadm=1.16.6-00 &&sudo kubeadm upgrade node &&sudo apt install kubelet=1.16.6-00"done
Checking what we've done
- All our nodes should now be updated to version 1.16.6
- Check nodes versions:kubectl get nodes -o wide
Skipping versions
This example worked because we went from 1.15 to 1.16
If you are upgrading from e.g. 1.14, you will have to go through 1.15 first
This means upgrading kubeadm to 1.15.X, then using it to upgrade the cluster
Then upgrading kubeadm to 1.16.X, etc.
Make sure to read the release notes before upgrading!
Backing up clusters
(automatically generated title slide)
Backing up clusters
Backups can have multiple purposes:
disaster recovery (servers or storage are destroyed or unreachable)
error recovery (human or process has altered or corrupted data)
cloning environments (for testing, validation...)
Let's see the strategies and tools available with Kubernetes!
Important
Kubernetes helps us with disaster recovery
(it gives us replication primitives)
Kubernetes helps us clone / replicate environments
(all resources can be described with manifests)
Kubernetes does not help us with error recovery
We still need to back up/snapshot our data:
with database backups (mysqldump, pgdump, etc.)
and/or snapshots at the storage layer
and/or traditional full disk backups
In a perfect world ...
The deployment of our Kubernetes clusters is automated
(recreating a cluster takes less than a minute of human time)
All the resources (Deployments, Services...) on our clusters are under version control
(never use
kubectl run; always apply YAML files coming from a repository)Stateful components are either:
stored on systems with regular snapshots
backed up regularly to an external, durable storage
outside of Kubernetes
Kubernetes cluster deployment
If our deployment system isn't fully automated, it should at least be documented
Litmus test: how long does it take to deploy a cluster...
for a senior engineer?
for a new hire?
Does it require external intervention?
(e.g. provisioning servers, signing TLS certs...)
Plan B
Full machine backups of the control plane can help
If the control plane is in pods (or containers), pay attention to storage drivers
(if the backup mechanism is not container-aware, the backups can take way more resources than they should, or even be unusable!)
If the previous sentence worries you:
automate the deployment of your clusters!
Managing our Kubernetes resources
Ideal scenario:
never create a resource directly on a cluster
push to a code repository
a special branch (
productionor evenmaster) gets automatically deployed
Some folks call this "GitOps"
(it's the logical evolution of configuration management and infrastructure as code)
GitOps in theory
What do we keep in version control?
For very simple scenarios: source code, Dockerfiles, scripts
For real applications: add resources (as YAML files)
For applications deployed multiple times: Helm, Kustomize...
(staging and production count as "multiple times")
GitOps tooling
Various tools exist (Weave Flux, GitKube...)
These tools are still very young
You still need to write YAML for all your resources
There is no tool to:
list all resources in a namespace
get resource YAML in a canonical form
diff YAML descriptions with current state
GitOps in practice
Start describing your resources with YAML
Leverage a tool like Kustomize or Helm
Make sure that you can easily deploy to a new namespace
(or even better: to a new cluster)
When tooling matures, you will be ready
Plan B
What if we can't describe everything with YAML?
What if we manually create resources and forget to commit them to source control?
What about global resources, that don't live in a namespace?
How can we be sure that we saved everything?
Backing up etcd
All objects are saved in etcd
etcd data should be relatively small
(and therefore, quick and easy to back up)
Two options to back up etcd:
snapshot the data directory
use
etcdctl snapshot
Making an etcd snapshot
The basic command is simple:
etcdctl snapshot save <filename>But we also need to specify:
an environment variable to specify that we want etcdctl v3
the address of the server to back up
the path to the key, certificate, and CA certificate
(if our etcd uses TLS certificates)
Snapshotting etcd on kubeadm
The following command will work on clusters deployed with kubeadm
(and maybe others)
It should be executed on a master node
docker run --rm --net host -v $PWD:/vol \ -v /etc/kubernetes/pki/etcd:/etc/kubernetes/pki/etcd:ro \ -e ETCDCTL_API=3 k8s.gcr.io/etcd:3.3.10 \ etcdctl --endpoints=https://[127.0.0.1]:2379 \ --cacert=/etc/kubernetes/pki/etcd/ca.crt \ --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt \ --key=/etc/kubernetes/pki/etcd/healthcheck-client.key \ snapshot save /vol/snapshot- It will create a file named
snapshotin the current directory
How can we remember all these flags?
Look at the static pod manifest for etcd
(in
/etc/kubernetes/manifests)The healthcheck probe is calling
etcdctlwith all the right flags 😉👍✌️Exercise: write the YAML for a batch job to perform the backup
Restoring an etcd snapshot
Execute exactly the same command, but replacingsavewithrestore(Believe it or not, doing that will not do anything useful!)
The
restorecommand does not load a snapshot into a running etcd serverThe
restorecommand creates a new data directory from the snapshot(it's an offline operation; it doesn't interact with an etcd server)
It will create a new data directory in a temporary container
(leaving the running etcd node untouched)
When using kubeadm
Create a new data directory from the snapshot:
sudo rm -rf /var/lib/etcddocker run --rm -v /var/lib:/var/lib -v $PWD:/vol \-e ETCDCTL_API=3 k8s.gcr.io/etcd:3.3.10 \etcdctl snapshot restore /vol/snapshot --data-dir=/var/lib/etcdProvision the control plane, using that data directory:
sudo kubeadm init \--ignore-preflight-errors=DirAvailable--var-lib-etcdRejoin the other nodes
The fine print
This only saves etcd state
It does not save persistent volumes and local node data
Some critical components (like the pod network) might need to be reset
As a result, our pods might have to be recreated, too
If we have proper liveness checks, this should happen automatically
More information about etcd backups
Kubernetes documentation about etcd backups
etcd documentation about snapshots and restore
A good blog post by elastisys explaining how to restore a snapshot
Another good blog post by consol labs on the same topic
Don't forget ...
Also back up the TLS information
(at the very least: CA key and cert; API server key and cert)
With clusters provisioned by kubeadm, this is in
/etc/kubernetes/pkiIf you don't:
you will still be able to restore etcd state and bring everything back up
you will need to redistribute user certificates
TLS information is highly sensitive!
Anyone who has it has full access to your cluster!
Stateful services
It's totally fine to keep your production databases outside of Kubernetes
Especially if you have only one database server!
Feel free to put development and staging databases on Kubernetes
(as long as they don't hold important data)
Using Kubernetes for stateful services makes sense if you have many
(because then you can leverage Kubernetes automation)
Snapshotting persistent volumes
Option 1: snapshot volumes out of band
(with the API/CLI/GUI of our SAN/cloud/...)
Option 2: storage system integration
(e.g. Portworx can create snapshots through annotations)
Option 3: snapshots through Kubernetes API
(now in alpha for a few storage providers: GCE, OpenSDS, Ceph, Portworx)
More backup tools
-
back up Kubernetes persistent volumes
-
cluster state management
Heptio ArkVelerofull cluster backup
-
simple scripts to save resource YAML to a git repository
-
Backup Interface for Volumes Attached to Containers
The Cloud Controller Manager
(automatically generated title slide)
The Cloud Controller Manager
Kubernetes has many features that are cloud-specific
(e.g. providing cloud load balancers when a Service of type LoadBalancer is created)
These features were initially implemented in API server and controller manager
Since Kubernetes 1.6, these features are available through a separate process:
the Cloud Controller Manager
The CCM is optional, but if we run in a cloud, we probably want it!
k8s/cloud-controller-manager.md
Cloud Controller Manager duties
Creating and updating cloud load balancers
Configuring routing tables in the cloud network (specific to GCE)
Updating node labels to indicate region, zone, instance type...
Obtain node name, internal and external addresses from cloud metadata service
Deleting nodes from Kubernetes when they're deleted in the cloud
Managing some volumes (e.g. ELBs, AzureDisks...)
(Eventually, volumes will be managed by the Container Storage Interface)
k8s/cloud-controller-manager.md
In-tree vs. out-of-tree
A number of cloud providers are supported "in-tree"
(in the main kubernetes/kubernetes repository on GitHub)
More cloud providers are supported "out-of-tree"
(with code in different repositories)
There is an ongoing effort to move everything to out-of-tree providers
k8s/cloud-controller-manager.md
In-tree providers
The following providers are actively maintained:
- Amazon Web Services
- Azure
- Google Compute Engine
- IBM Cloud
- OpenStack
- VMware vSphere
These ones are less actively maintained:
- Apache CloudStack
- oVirt
- VMware Photon
k8s/cloud-controller-manager.md
Out-of-tree providers
The list includes the following providers:
DigitalOcean
keepalived (not exactly a cloud; provides VIPs for load balancers)
Linode
Oracle Cloud Infrastructure
(And possibly others; there is no central registry for these.)
k8s/cloud-controller-manager.md
Audience questions
What kind of clouds are you using/planning to use?
What kind of details would you like to see in this section?
Would you appreciate details on clouds that you don't / won't use?
k8s/cloud-controller-manager.md
Cloud Controller Manager in practice
Write a configuration file
(typically
/etc/kubernetes/cloud.conf)Run the CCM process
(on self-hosted clusters, this can be a DaemonSet selecting the control plane nodes)
Start kubelet with
--cloud-provider=externalWhen using managed clusters, this is done automatically
There is very little documentation on writing the configuration file
(except for OpenStack)
k8s/cloud-controller-manager.md
Bootstrapping challenges
When a node joins the cluster, it needs to obtain a signed TLS certificate
That certificate must contain the node's addresses
These addresses are provided by the Cloud Controller Manager
(at least the external address)
To get these addresses, the node needs to communicate with the control plane
...Which means joining the cluster
(The problem didn't occur when cloud-specific code was running in kubelet: kubelet could obtain the required information directly from the cloud provider's metadata service.)
k8s/cloud-controller-manager.md
More information about CCM
CCM configuration and operation is highly specific to each cloud provider
(which is why this section remains very generic)
The Kubernetes documentation has some information:
configuration (mainly for OpenStack)
k8s/cloud-controller-manager.md
Namespaces
(automatically generated title slide)
Namespaces
We would like to deploy another copy of DockerCoins on our cluster
We could rename all our deployments and services:
hasher → hasher2, redis → redis2, rng → rng2, etc.
That would require updating the code
There has to be a better way!
Namespaces
We would like to deploy another copy of DockerCoins on our cluster
We could rename all our deployments and services:
hasher → hasher2, redis → redis2, rng → rng2, etc.
That would require updating the code
There has to be a better way!
As hinted by the title of this section, we will use namespaces
Identifying a resource
We cannot have two resources with the same name
(or can we...?)
Identifying a resource
We cannot have two resources with the same name
(or can we...?)
We cannot have two resources of the same kind with the same name
(but it's OK to have an
rngservice, anrngdeployment, and anrngdaemon set)
Identifying a resource
We cannot have two resources with the same name
(or can we...?)
We cannot have two resources of the same kind with the same name
(but it's OK to have an
rngservice, anrngdeployment, and anrngdaemon set)We cannot have two resources of the same kind with the same name in the same namespace
(but it's OK to have e.g. two
rngservices in different namespaces)
Identifying a resource
We cannot have two resources with the same name
(or can we...?)
We cannot have two resources of the same kind with the same name
(but it's OK to have an
rngservice, anrngdeployment, and anrngdaemon set)We cannot have two resources of the same kind with the same name in the same namespace
(but it's OK to have e.g. two
rngservices in different namespaces)Except for resources that exist at the cluster scope
(these do not belong to a namespace)
Uniquely identifying a resource
For namespaced resources:
the tuple (kind, name, namespace) needs to be unique
For resources at the cluster scope:
the tuple (kind, name) needs to be unique
- List resource types again, and check the NAMESPACED column:kubectl api-resources
Pre-existing namespaces
If we deploy a cluster with
kubeadm, we have three or four namespaces:default(for our applications)kube-system(for the control plane)kube-public(contains one ConfigMap for cluster discovery)kube-node-lease(in Kubernetes 1.14 and later; contains Lease objects)
If we deploy differently, we may have different namespaces
Creating namespaces
- Let's see two identical methods to create a namespace
We can use
kubectl create namespace:kubectl create namespace blueOr we can construct a very minimal YAML snippet:
kubectl apply -f- <<EOFapiVersion: v1kind: Namespacemetadata:name: blueEOF
Using namespaces
We can pass a
-nor--namespaceflag to mostkubectlcommands:kubectl -n blue get svcWe can also change our current context
A context is a (user, cluster, namespace) tuple
We can manipulate contexts with the
kubectl configcommand
Viewing existing contexts
- On our training environments, at this point, there should be only one context
- View existing contexts to see the cluster name and the current user:kubectl config get-contexts
The current context (the only one!) is tagged with a
*What are NAME, CLUSTER, AUTHINFO, and NAMESPACE?
What's in a context
NAME is an arbitrary string to identify the context
CLUSTER is a reference to a cluster
(i.e. API endpoint URL, and optional certificate)
AUTHINFO is a reference to the authentication information to use
(i.e. a TLS client certificate, token, or otherwise)
NAMESPACE is the namespace
(empty string =
default)
Switching contexts
We want to use a different namespace
Solution 1: update the current context
This is appropriate if we need to change just one thing (e.g. namespace or authentication).
Solution 2: create a new context and switch to it
This is appropriate if we need to change multiple things and switch back and forth.
Let's go with solution 1!
Updating a context
This is done through
kubectl config set-contextWe can update a context by passing its name, or the current context with
--current
Update the current context to use the
bluenamespace:kubectl config set-context --current --namespace=blueCheck the result:
kubectl config get-contexts
Using our new namespace
- Let's check that we are in our new namespace, then deploy a new copy of Dockercoins
- Verify that the new context is empty:kubectl get all
Deploying DockerCoins with YAML files
- The GitHub repository
jpetazzo/kubercoinscontains everything we need!
Clone the kubercoins repository:
cd ~git clone https://github.com/jpetazzo/kubercoinsCreate all the DockerCoins resources:
kubectl create -f kubercoins
If the argument behind -f is a directory, all the files in that directory are processed.
The subdirectories are not processed, unless we also add the -R flag.
Viewing the deployed app
- Let's see if this worked correctly!
Retrieve the port number allocated to the
webuiservice:kubectl get svc webuiPoint our browser to http://X.X.X.X:3xxxx
If the graph shows up but stays at zero, give it a minute or two!
Namespaces and isolation
Namespaces do not provide isolation
A pod in the
greennamespace can communicate with a pod in thebluenamespaceA pod in the
defaultnamespace can communicate with a pod in thekube-systemnamespaceCoreDNS uses a different subdomain for each namespace
Example: from any pod in the cluster, you can connect to the Kubernetes API with:
https://kubernetes.default.svc.cluster.local:443/
Isolating pods
Actual isolation is implemented with network policies
Network policies are resources (like deployments, services, namespaces...)
Network policies specify which flows are allowed:
between pods
from pods to the outside world
and vice-versa
Switch back to the default namespace
- Let's make sure that we don't run future exercises in the
bluenamespace
- Switch back to the original context:kubectl config set-context --current --namespace=
Note: we could have used --namespace=default for the same result.
Switching namespaces more easily
We can also use a little helper tool called
kubens:# Switch to namespace fookubens foo# Switch back to the previous namespacekubens -On our clusters,
kubensis calledknsinstead(so that it's even fewer keystrokes to switch namespaces)
kubens and kubectx
With
kubens, we can switch quickly between namespacesWith
kubectx, we can switch quickly between contextsBoth tools are simple shell scripts available from https://github.com/ahmetb/kubectx
On our clusters, they are installed as
knsandkctx(for brevity and to avoid completion clashes between
kubectxandkubectl)
kube-ps1
It's easy to lose track of our current cluster / context / namespace
kube-ps1makes it easy to track these, by showing them in our shell promptIt is installed on our training clusters, and when using shpod
It gives us a prompt looking like this one:
[123.45.67.89] (kubernetes-admin@kubernetes:default) docker@node1 ~(The highlighted part is
context:namespace, managed bykube-ps1)Highly recommended if you work across multiple contexts or namespaces!
Installing kube-ps1
It's a simple shell script available from https://github.com/jonmosco/kube-ps1
It needs to be installed in our profile/rc files
(instructions differ depending on platform, shell, etc.)
Once installed, it defines aliases called
kube_ps1,kubeon,kubeoff(to selectively enable/disable it when needed)
Pro-tip: install it on your machine during the next break!
Controlling a Kubernetes cluster remotely
(automatically generated title slide)
Controlling a Kubernetes cluster remotely
kubectlcan be used either on cluster instances or outside the clusterHere, we are going to use
kubectlfrom our local machine
Requirements
The exercises in this chapter should be done on your local machine.
kubectlis officially available on Linux, macOS, Windows(and unofficially anywhere we can build and run Go binaries)
You may skip these exercises if you are following along from:
a tablet or phone
a web-based terminal
an environment where you can't install and run new binaries
Installing kubectl
- If you already have
kubectlon your local machine, you can skip this
Note: if you are following along with a different platform (e.g. Linux on an architecture different from amd64, or with a phone or tablet), installing kubectl might be more complicated (or even impossible) so feel free to skip this section.
Testing kubectl
Check that
kubectlworks correctly(before even trying to connect to a remote cluster!)
- Ask
kubectlto show its version number:kubectl version --client
The output should look like this:
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.0",GitCommit:"e8462b5b5dc2584fdcd18e6bcfe9f1e4d970a529", GitTreeState:"clean",BuildDate:"2019-06-19T16:40:16Z", GoVersion:"go1.12.5", Compiler:"gc",Platform:"darwin/amd64"}Preserving the existing ~/.kube/config
If you already have a
~/.kube/configfile, rename it(we are going to overwrite it in the following slides!)
If you never used
kubectlon your machine before: nothing to do!
Make a copy of
~/.kube/config; if you are using macOS or Linux, you can do:cp ~/.kube/config ~/.kube/config.before.trainingIf you are using Windows, you will need to adapt this command
Copying the configuration file from node1
The
~/.kube/configfile that is onnode1contains all the credentials we needLet's copy it over!
Copy the file from
node1; if you are using macOS or Linux, you can do:scp USER@X.X.X.X:.kube/config ~/.kube/config# Make sure to replace X.X.X.X with the IP address of node1,# and USER with the user name used to log into node1!If you are using Windows, adapt these instructions to your SSH client
Updating the server address
There is a good chance that we need to update the server address
To know if it is necessary, run
kubectl config viewLook for the
server:address:if it matches the public IP address of
node1, you're good!if it is anything else (especially a private IP address), update it!
To update the server address, run:
kubectl config set-cluster kubernetes --server=https://X.X.X.X:6443# Make sure to replace X.X.X.X with the IP address of node1!
What if we get a certificate error?
Generally, the Kubernetes API uses a certificate that is valid for:
kuberneteskubernetes.defaultkubernetes.default.svckubernetes.default.svc.cluster.local- the ClusterIP address of the
kubernetesservice - the hostname of the node hosting the control plane (e.g.
node1) - the IP address of the node hosting the control plane
On most clouds, the IP address of the node is an internal IP address
... And we are going to connect over the external IP address
... And that external IP address was not used when creating the certificate!
Working around the certificate error
We need to tell
kubectlto skip TLS verification(only do this with testing clusters, never in production!)
The following command will do the trick:
kubectl config set-cluster kubernetes --insecure-skip-tls-verify
Checking that we can connect to the cluster
- We can now run a couple of trivial commands to check that all is well
Check the versions of the local client and remote server:
kubectl versionView the nodes of the cluster:
kubectl get nodes
We can now utilize the cluster exactly as if we're logged into a node, except that it's remote.
Accessing internal services
(automatically generated title slide)
Accessing internal services
When we are logged in on a cluster node, we can access internal services
(by virtue of the Kubernetes network model: all nodes can reach all pods and services)
When we are accessing a remote cluster, things are different
(generally, our local machine won't have access to the cluster's internal subnet)
How can we temporarily access a service without exposing it to everyone?
Accessing internal services
When we are logged in on a cluster node, we can access internal services
(by virtue of the Kubernetes network model: all nodes can reach all pods and services)
When we are accessing a remote cluster, things are different
(generally, our local machine won't have access to the cluster's internal subnet)
How can we temporarily access a service without exposing it to everyone?
kubectl proxy: gives us access to the API, which includes a proxy for HTTP resourceskubectl port-forward: allows forwarding of TCP ports to arbitrary pods, services, ...
Suspension of disbelief
The exercises in this section assume that we have set up kubectl on our
local machine in order to access a remote cluster.
We will therefore show how to access services and pods of the remote cluster, from our local machine.
You can also run these exercises directly on the cluster (if you haven't
installed and set up kubectl locally).
Running commands locally will be less useful
(since you could access services and pods directly),
but keep in mind that these commands will work anywhere as long as you have
installed and set up kubectl to communicate with your cluster.
kubectl proxy in theory
Running
kubectl proxygives us access to the entire Kubernetes APIThe API includes routes to proxy HTTP traffic
These routes look like the following:
/api/v1/namespaces/<namespace>/services/<service>/proxyWe just add the URI to the end of the request, for instance:
/api/v1/namespaces/<namespace>/services/<service>/proxy/index.htmlWe can access
servicesandpodsthis way
kubectl proxy in practice
- Let's access the
webuiservice throughkubectl proxy
Run an API proxy in the background:
kubectl proxy &Access the
webuiservice:curl localhost:8001/api/v1/namespaces/default/services/webui/proxy/index.htmlTerminate the proxy:
kill %1
kubectl port-forward in theory
What if we want to access a TCP service?
We can use
kubectl port-forwardinsteadIt will create a TCP relay to forward connections to a specific port
(of a pod, service, deployment...)
The syntax is:
kubectl port-forward service/name_of_service local_port:remote_portIf only one port number is specified, it is used for both local and remote ports
kubectl port-forward in practice
- Let's access our remote Redis server
Forward connections from local port 10000 to remote port 6379:
kubectl port-forward svc/redis 10000:6379 &Connect to the Redis server:
telnet localhost 10000Issue a few commands, e.g.
INFO serverthenQUIT
- Terminate the port forwarder:kill %1
Accessing the API with kubectl proxy
(automatically generated title slide)
Accessing the API with kubectl proxy
The API requires us to authenticate¹
There are many authentication methods available, including:
TLS client certificates
(that's what we've used so far)HTTP basic password authentication
(from a static file; not recommended)various token mechanisms
(detailed in the documentation)
¹OK, we lied. If you don't authenticate, you are considered to
be user system:anonymous, which doesn't have any access rights by default.
Accessing the API directly
- Let's see what happens if we try to access the API directly with
curl
Retrieve the ClusterIP allocated to the
kubernetesservice:kubectl get svc kubernetesReplace the IP below and try to connect with
curl:curl -k https://10.96.0.1/
The API will tell us that user system:anonymous cannot access this path.
Authenticating to the API
If we wanted to talk to the API, we would need to:
extract our TLS key and certificate information from
~/.kube/config(the information is in PEM format, encoded in base64)
use that information to present our certificate when connecting
(for instance, with
openssl s_client -key ... -cert ... -connect ...)figure out exactly which credentials to use
(once we start juggling multiple clusters)
change that whole process if we're using another authentication method
🤔 There has to be a better way!
Using kubectl proxy for authentication
kubectl proxyruns a proxy in the foregroundThis proxy lets us access the Kubernetes API without authentication
(
kubectl proxyadds our credentials on the fly to the requests)This proxy lets us access the Kubernetes API over plain HTTP
This is a great tool to learn and experiment with the Kubernetes API
... And for serious uses as well (suitable for one-shot scripts)
For unattended use, it's better to create a service account
Trying kubectl proxy
- Let's start
kubectl proxyand then do a simple request withcurl!
Start
kubectl proxyin the background:kubectl proxy &Access the API's default route:
curl localhost:8001
- Terminate the proxy:kill %1
The output is a list of available API routes.
OpenAPI (fka Swagger)
The Kubernetes API serves an OpenAPI Specification
(OpenAPI was formerly known as Swagger)
OpenAPI has many advantages
(generate client library code, generate test code ...)
For us, this means we can explore the API with Swagger UI
(for instance with the Swagger UI add-on for Firefox)
kubectl proxy is intended for local use
By default, the proxy listens on port 8001
(But this can be changed, or we can tell
kubectl proxyto pick a port)By default, the proxy binds to
127.0.0.1(Making it unreachable from other machines, for security reasons)
By default, the proxy only accepts connections from:
^localhost$,^127\.0\.0\.1$,^\[::1\]$This is great when running
kubectl proxylocallyNot-so-great when you want to connect to the proxy from a remote machine
Running kubectl proxy on a remote machine
If we wanted to connect to the proxy from another machine, we would need to:
bind to
INADDR_ANYinstead of127.0.0.1accept connections from any address
This is achieved with:
kubectl proxy --port=8888 --address=0.0.0.0 --accept-hosts=.*
Do not do this on a real cluster: it opens full unauthenticated access!
Security considerations
Running
kubectl proxyopenly is a huge security riskIt is slightly better to run the proxy where you need it
(and copy credentials, e.g.
~/.kube/config, to that place)It is even better to use a limited account with reduced permissions
Good to know ...
kubectl proxyalso gives access to all internal servicesSpecifically, services are exposed as such:
/api/v1/namespaces/<namespace>/services/<service>/proxyWe can use
kubectl proxyto access an internal service in a pinch(or, for non HTTP services,
kubectl port-forward)This is not very useful when running
kubectldirectly on the cluster(since we could connect to the services directly anyway)
But it is very powerful as soon as you run
kubectlfrom a remote machine
The Container Network Interface
(automatically generated title slide)
The Container Network Interface
Allows us to decouple network configuration from Kubernetes
Implemented by plugins
Plugins are executables that will be invoked by kubelet
Plugins are responsible for:
allocating IP addresses for containers
configuring the network for containers
Plugins can be combined and chained when it makes sense
Combining plugins
Interface could be created by e.g.
vlanorbridgepluginIP address could be allocated by e.g.
dhcporhost-localpluginInterface parameters (MTU, sysctls) could be tweaked by the
tuningplugin
The reference plugins are available here.
Look in each plugin's directory for its documentation. k8s/cni.md
How does kubelet know which plugins to use?
The plugin (or list of plugins) is set in the CNI configuration
The CNI configuration is a single file in
/etc/cni/net.dIf there are multiple files in that directory, the first one is used
(in lexicographic order)
That path can be changed with the
--cni-conf-dirflag of kubelet
CNI configuration in practice
When we set up the "pod network" (like Calico, Weave...) it ships a CNI configuration
(and sometimes, custom CNI plugins)
Very often, that configuration (and plugins) is installed automatically
(by a DaemonSet featuring an initContainer with hostPath volumes)
Examples:
Calico CNI config and volume
kube-router CNI config and volume
Conf vs conflist
There are two slightly different configuration formats
Basic configuration format:
- holds configuration for a single plugin
- typically has a
.confname suffix - has a
typestring field in the top-most structure - examples
Configuration list format:
- can hold configuration for multiple (chained) plugins
- typically has a
.conflistname suffix - has a
pluginslist field in the top-most structure - examples
How plugins are invoked
Parameters are given through environment variables, including:
CNI_COMMAND: desired operation (ADD, DEL, CHECK, or VERSION)
CNI_CONTAINERID: container ID
CNI_NETNS: path to network namespace file
CNI_IFNAME: what the network interface should be named
The network configuration must be provided to the plugin on stdin
(this avoids race conditions that could happen by passing a file path)
In practice: kube-router
We are going to set up a new cluster
For this new cluster, we will use kube-router
kube-router will provide the "pod network"
(connectivity with pods)
kube-router will also provide internal service connectivity
(replacing kube-proxy)
How kube-router works
Very simple architecture
Does not introduce new CNI plugins
(uses the
bridgeplugin, withhost-localfor IPAM)Pod traffic is routed between nodes
(no tunnel, no new protocol)
Internal service connectivity is implemented with IPVS
Can provide pod network and/or internal service connectivity
kube-router daemon runs on every node
What kube-router does
Connect to the API server
Obtain the local node's
podCIDRInject it into the CNI configuration file
(we'll use
/etc/cni/net.d/10-kuberouter.conflist)Obtain the addresses of all nodes
Establish a full mesh BGP peering with the other nodes
Exchange routes over BGP
What's BGP?
BGP (Border Gateway Protocol) is the protocol used between internet routers
It scales pretty well (it is used to announce the 700k CIDR prefixes of the internet)
It is spoken by many hardware routers from many vendors
It also has many software implementations (Quagga, Bird, FRR...)
Experienced network folks generally know it (and appreciate it)
It also used by Calico (another popular network system for Kubernetes)
Using BGP allows us to interconnect our "pod network" with other systems
The plan
We'll work in a new cluster (named
kuberouter)We will run a simple control plane (like before)
... But this time, the controller manager will allocate
podCIDRsubnets(so that we don't have to manually assign subnets to individual nodes)
We will create a DaemonSet for kube-router
We will join nodes to the cluster
The DaemonSet will automatically start a kube-router pod on each node
Logging into the new cluster
Log into node
kuberouter1Clone the workshop repository:
git clone https://github.com/BretFisher/kubernetes-masteryMove to this directory:
cd container.training/compose/kube-router-k8s-control-plane
Checking the CNI configuration
- By default, kubelet gets the CNI configuration from
/etc/cni/net.d
- Check the content of
/etc/cni/net.d
(On most machines, at this point, /etc/cni/net.d doesn't even exist).)
Our control plane
We will use a Compose file to start the control plane
It is similar to the one we used with the
kubenetclusterThe API server is started with
--allow-privileged(because we will start kube-router in privileged pods)
The controller manager is started with extra flags too:
--allocate-node-cidrsand--cluster-cidrWe need to edit the Compose file to set the Cluster CIDR
Starting the control plane
Our cluster CIDR will be
10.C.0.0/16(where
Cis our cluster number)
Edit the Compose file to set the Cluster CIDR:
vim docker-compose.yamlStart the control plane:
docker-compose up
The kube-router DaemonSet
In the same directory, there is a
kuberouter.yamlfileIt contains the definition for a DaemonSet and a ConfigMap
Before we load it, we also need to edit it
We need to indicate the address of the API server
(because kube-router needs to connect to it to retrieve node information)
Creating the DaemonSet
The address of the API server will be
http://A.B.C.D:8080(where
A.B.C.Dis the public address ofkuberouter1, running the control plane)
Edit the YAML file to set the API server address:
vim kuberouter.yamlCreate the DaemonSet:
kubectl create -f kuberouter.yaml
Note: the DaemonSet won't create any pods (yet) since there are no nodes (yet).
Generating the kubeconfig for kubelet
- This is similar to what we did for the
kubenetcluster
- Generate the kubeconfig file (replacing
X.X.X.Xwith the address ofkuberouter1):kubectl config set-cluster cni --server http://X.X.X.X:8080kubectl config set-context cni --cluster cnikubectl config use-context cnicp ~/.kube/config ~/kubeconfig
Distributing kubeconfig
- We need to copy that kubeconfig file to the other nodes
- Copy
kubeconfigto the other nodes:for N in 2 3; doscp ~/kubeconfig kuberouter$N:done
Starting kubelet
We don't need the
--pod-cidroption anymore(the controller manager will allocate these automatically)
We need to pass
--network-plugin=cni
Join the first node:
sudo kubelet --kubeconfig ~/kubeconfig --network-plugin=cniOpen more terminals and join the other nodes:
ssh kuberouter2 sudo kubelet --kubeconfig ~/kubeconfig --network-plugin=cnissh kuberouter3 sudo kubelet --kubeconfig ~/kubeconfig --network-plugin=cni
Checking the CNI configuration
At this point, kuberouter should have installed its CNI configuration
(in
/etc/cni/net.d)
- Check the content of
/etc/cni/net.d
There should be a file created by kuberouter
The file should contain the node's podCIDR
Setting up a test
- Let's create a Deployment and expose it with a Service
Create a Deployment running a web server:
kubectl create deployment web --image=jpetazzo/httpenvScale it so that it spans multiple nodes:
kubectl scale deployment web --replicas=5Expose it with a Service:
kubectl expose deployment web --port=8888
Checking that everything works
Get the ClusterIP address for the service:
kubectl get svc webSend a few requests there:
curl X.X.X.X:8888
Note that if you send multiple requests, they are load-balanced in a round robin manner.
This shows that we are using IPVS (vs. iptables, which picked random endpoints).
Troubleshooting
- What if we need to check that everything is working properly?
Check the IP addresses of our pods:
kubectl get pods -o wideCheck our routing table:
route -nip route
We should see the local pod CIDR connected to kube-bridge, and the other nodes' pod CIDRs having individual routes, with each node being the gateway.
More troubleshooting
We can also look at the output of the kube-router pods
(with
kubectl logs)kube-router also comes with a special shell that gives lots of useful info
(we can access it with
kubectl exec)But with the current setup of the cluster, these options may not work!
Why?
Trying kubectl logs / kubectl exec
Try to show the logs of a kube-router pod:
kubectl -n kube-system logs ds/kube-routerOr try to exec into one of the kube-router pods:
kubectl -n kube-system exec kube-router-xxxxx bash
These commands will give an error message that includes:
dial tcp: lookup kuberouterX on 127.0.0.11:53: no such hostWhat does that mean?
Internal name resolution
To execute these commands, the API server needs to connect to kubelet
By default, it creates a connection using the kubelet's name
(e.g.
http://kuberouter1:...)This requires our nodes names to be in DNS
We can change that by setting a flag on the API server:
--kubelet-preferred-address-types=InternalIP
Another way to check the logs
We can also ask the logs directly to the container engine
First, get the container ID, with
docker psor like this:CID=$(docker ps -q \--filter label=io.kubernetes.pod.namespace=kube-system \--filter label=io.kubernetes.container.name=kube-router)Then view the logs:
docker logs $CID
Other ways to distribute routing tables
We don't need kube-router and BGP to distribute routes
The list of nodes (and associated
podCIDRsubnets) is available through the APIThis shell snippet generates the commands to add all required routes on a node:
NODES=$(kubectl get nodes -o name | cut -d/ -f2)for DESTNODE in $NODES; do if [ "$DESTNODE" != "$HOSTNAME" ]; then echo $(kubectl get node $DESTNODE -o go-template=" route add -net {{.spec.podCIDR}} gw {{(index .status.addresses 0).address}}") fidoneThis could be useful for embedded platforms with very limited resources
(or lab environments for learning purposes)
Interconnecting clusters
(automatically generated title slide)
Interconnecting clusters
We assigned different Cluster CIDRs to each cluster
This allows us to connect our clusters together
We will leverage kube-router BGP abilities for that
We will peer each kube-router instance with a route reflector
As a result, we will be able to ping each other's pods
Disclaimers
There are many methods to interconnect clusters
Depending on your network implementation, you will use different methods
The method shown here only works for nodes with direct layer 2 connection
We will often need to use tunnels or other network techniques
The plan
Someone will start the route reflector
(typically, that will be the person presenting these slides!)
We will update our kube-router configuration
We will add a peering with the route reflector
(instructing kube-router to connect to it and exchange route information)
We should see the routes to other clusters on our nodes
(in the output of e.g.
route -norip route show)We should be able to ping pods of other nodes
Starting the route reflector
Only do this slide if you are doing this on your own
There is a Compose file in the
compose/frr-route-reflectordirectoryBefore continuing, make sure that you have the IP address of the route reflector
Configuring kube-router
This can be done in two ways:
with command-line flags to the
kube-routerprocesswith annotations to Node objects
We will use the command-line flags
(because it will automatically propagate to all nodes)
Note: with Calico, this is achieved by creating a BGPPeer CRD.
Updating kube-router configuration
- We need to pass two command-line flags to the kube-router process
Edit the
kuberouter.yamlfileAdd the following flags to the kube-router arguments:
- "--peer-router-ips=X.X.X.X"- "--peer-router-asns=64512"(Replace
X.X.X.Xwith the route reflector address)Update the DaemonSet definition:
kubectl apply -f kuberouter.yaml
Restarting kube-router
The DaemonSet will not update the pods automatically
(it is using the default
updateStrategy, which isOnDelete)We will therefore delete the pods
(they will be recreated with the updated definition)
- Delete all the kube-router pods:kubectl delete pods -n kube-system -l k8s-app=kube-router
Note: the other updateStrategy for a DaemonSet is RollingUpdate.
For critical services, we might want to precisely control the update process.
Checking peering status
We can see informative messages in the output of kube-router:
time="2019-04-07T15:53:56Z" level=info msg="Peer Up"Key=X.X.X.X State=BGP_FSM_OPENCONFIRM Topic=PeerWe should see the routes of the other clusters show up
For debugging purposes, the reflector also exports a route to 1.0.0.2/32
That route will show up like this:
1.0.0.2 172.31.X.Y 255.255.255.255 UGH 0 0 0 eth0We should be able to ping the pods of other clusters!
If we wanted to do more ...
kube-router can also export ClusterIP addresses
(by adding the flag
--advertise-cluster-ip)They are exported individually (as /32)
This would allow us to easily access other clusters' services
(without having to resolve the individual addresses of pods)
Even better if it's combined with DNS integration
(to facilitate name → ClusterIP resolution)
Network policies
(automatically generated title slide)
Network policies
Namespaces help us to organize resources
Namespaces do not provide isolation
By default, every pod can contact every other pod
By default, every service accepts traffic from anyone
If we want this to be different, we need network policies
What's a network policy?
A network policy is defined by the following things.
A pod selector indicating which pods it applies to
e.g.: "all pods in namespace
bluewith the labelzone=internal"A list of ingress rules indicating which inbound traffic is allowed
e.g.: "TCP connections to ports 8000 and 8080 coming from pods with label
zone=dmz, and from the external subnet 4.42.6.0/24, except 4.42.6.5"A list of egress rules indicating which outbound traffic is allowed
A network policy can provide ingress rules, egress rules, or both.
How do network policies apply?
A pod can be "selected" by any number of network policies
If a pod isn't selected by any network policy, then its traffic is unrestricted
(In other words: in the absence of network policies, all traffic is allowed)
If a pod is selected by at least one network policy, then all traffic is blocked ...
... unless it is explicitly allowed by one of these network policies
Traffic filtering is flow-oriented
Network policies deal with connections, not individual packets
Example: to allow HTTP (80/tcp) connections to pod A, you only need an ingress rule
(You do not need a matching egress rule to allow response traffic to go through)
This also applies for UDP traffic
(Allowing DNS traffic can be done with a single rule)
Network policy implementations use stateful connection tracking
Pod-to-pod traffic
Connections from pod A to pod B have to be allowed by both pods:
pod A has to be unrestricted, or allow the connection as an egress rule
pod B has to be unrestricted, or allow the connection as an ingress rule
As a consequence: if a network policy restricts traffic going from/to a pod,
the restriction cannot be overridden by a network policy selecting another podThis prevents an entity managing network policies in namespace A (but without permission to do so in namespace B) from adding network policies giving them access to namespace B
The rationale for network policies
In network security, it is generally considered better to "deny all, then allow selectively"
(The other approach, "allow all, then block selectively" makes it too easy to leave holes)
As soon as one network policy selects a pod, the pod enters this "deny all" logic
Further network policies can open additional access
Good network policies should be scoped as precisely as possible
In particular: make sure that the selector is not too broad
(Otherwise, you end up affecting pods that were otherwise well secured)
Our first network policy
This is our game plan:
run a web server in a pod
create a network policy to block all access to the web server
create another network policy to allow access only from specific pods
Running our test web server
- Let's use the
nginximage:kubectl create deployment testweb --image=nginx
Find out the IP address of the pod with one of these two commands:
kubectl get pods -o wide -l app=testwebIP=$(kubectl get pods -l app=testweb -o json | jq -r .items[0].status.podIP)Check that we can connect to the server:
curl $IP
The curl command should show us the "Welcome to nginx!" page.
Adding a very restrictive network policy
The policy will select pods with the label
app=testwebIt will specify an empty list of ingress rules (matching nothing)
Apply the policy in this YAML file:
kubectl apply -f ~/container.training/k8s/netpol-deny-all-for-testweb.yamlCheck if we can still access the server:
curl $IP
The curl command should now time out.
Looking at the network policy
This is the file that we applied:
kind: NetworkPolicyapiVersion: networking.k8s.io/v1metadata: name: deny-all-for-testwebspec: podSelector: matchLabels: app: testweb ingress: []Allowing connections only from specific pods
We want to allow traffic from pods with the label
run=testcurlReminder: this label is automatically applied when we do
kubectl run testcurl ...
- Apply another policy:kubectl apply -f ~/container.training/k8s/netpol-allow-testcurl-for-testweb.yaml
Looking at the network policy
This is the second file that we applied:
kind: NetworkPolicyapiVersion: networking.k8s.io/v1metadata: name: allow-testcurl-for-testwebspec: podSelector: matchLabels: app: testweb ingress: - from: - podSelector: matchLabels: run: testcurlTesting the network policy
- Let's create pods with, and without, the required label
Try to connect to testweb from a pod with the
run=testcurllabel:kubectl run testcurl --rm -i --image=centos -- curl -m3 $IPTry to connect to testweb with a different label:
kubectl run testkurl --rm -i --image=centos -- curl -m3 $IP
The first command will work (and show the "Welcome to nginx!" page).
The second command will fail and time out after 3 seconds.
(The timeout is obtained with the -m3 option.)
An important warning
Some network plugins only have partial support for network policies
For instance, Weave added support for egress rules in version 2.4 (released in July 2018)
But only recently added support for ipBlock in version 2.5 (released in Nov 2018)
Unsupported features might be silently ignored
(Making you believe that you are secure, when you're not)
Network policies, pods, and services
Network policies apply to pods
A service can select multiple pods
(And load balance traffic across them)
It is possible that we can connect to some pods, but not some others
(Because of how network policies have been defined for these pods)
In that case, connections to the service will randomly pass or fail
(Depending on whether the connection was sent to a pod that we have access to or not)
Network policies and namespaces
A good strategy is to isolate a namespace, so that:
all the pods in the namespace can communicate together
other namespaces cannot access the pods
external access has to be enabled explicitly
Let's see what this would look like for the DockerCoins app!
Network policies for DockerCoins
We are going to apply two policies
The first policy will prevent traffic from other namespaces
The second policy will allow traffic to the
webuipodsThat's all we need for that app!
Blocking traffic from other namespaces
This policy selects all pods in the current namespace.
It allows traffic only from pods in the current namespace.
(An empty podSelector means "all pods.")
kind: NetworkPolicyapiVersion: networking.k8s.io/v1metadata: name: deny-from-other-namespacesspec: podSelector: {} ingress: - from: - podSelector: {}Allowing traffic to webui pods
This policy selects all pods with label app=webui.
It allows traffic from any source.
(An empty from field means "all sources.")
kind: NetworkPolicyapiVersion: networking.k8s.io/v1metadata: name: allow-webuispec: podSelector: matchLabels: app: webui ingress: - from: []Applying both network policies
- Both network policies are declared in the file
k8s/netpol-dockercoins.yaml
Apply the network policies:
kubectl apply -f ~/container.training/k8s/netpol-dockercoins.yamlCheck that we can still access the web UI from outside
(and that the app is still working correctly!)Check that we can't connect anymore to
rngorhasherthrough their ClusterIP
Note: using kubectl proxy or kubectl port-forward allows us to connect
regardless of existing network policies. This allows us to debug and
troubleshoot easily, without having to poke holes in our firewall.
Cleaning up our network policies
The network policies that we have installed block all traffic to the default namespace
We should remove them, otherwise further exercises will fail!
- Remove all network policies:kubectl delete networkpolicies --all
Protecting the control plane
Should we add network policies to block unauthorized access to the control plane?
(etcd, API server, etc.)
Protecting the control plane
Should we add network policies to block unauthorized access to the control plane?
(etcd, API server, etc.)
At first, it seems like a good idea ...
Protecting the control plane
Should we add network policies to block unauthorized access to the control plane?
(etcd, API server, etc.)
At first, it seems like a good idea ...
But it shouldn't be necessary:
not all network plugins support network policies
the control plane is secured by other methods (mutual TLS, mostly)
the code running in our pods can reasonably expect to contact the API
(and it can do so safely thanks to the API permission model)
If we block access to the control plane, we might disrupt legitimate code
...Without necessarily improving security
Further resources
As always, the Kubernetes documentation is a good starting point
The API documentation has a lot of detail about the format of various objects:
And two resources by Ahmet Alp Balkan:
a very good talk about network policies at KubeCon North America 2017
a repository of ready-to-use recipes for network policies
Authentication and authorization
(automatically generated title slide)
Authentication and authorization
And first, a little refresher!
Authentication = verifying the identity of a person
On a UNIX system, we can authenticate with login+password, SSH keys ...
Authorization = listing what they are allowed to do
On a UNIX system, this can include file permissions, sudoer entries ...
Sometimes abbreviated as "authn" and "authz"
In good modular systems, these things are decoupled
(so we can e.g. change a password or SSH key without having to reset access rights)
Authentication in Kubernetes
When the API server receives a request, it tries to authenticate it
(it examines headers, certificates... anything available)
Many authentication methods are available and can be used simultaneously
(we will see them on the next slide)
It's the job of the authentication method to produce:
- the user name
- the user ID
- a list of groups
The API server doesn't interpret these; that'll be the job of authorizers
Authentication methods
TLS client certificates
(that's what we've been doing with
kubectlso far)Bearer tokens
(a secret token in the HTTP headers of the request)
-
(carrying user and password in an HTTP header)
Authentication proxy
(sitting in front of the API and setting trusted headers)
Anonymous requests
If any authentication method rejects a request, it's denied
(
401 UnauthorizedHTTP code)If a request is neither rejected nor accepted by anyone, it's anonymous
the user name is
system:anonymousthe list of groups is
[system:unauthenticated]
By default, the anonymous user can't do anything
(that's what you get if you just
curlthe Kubernetes API)
Authentication with TLS certificates
This is enabled in most Kubernetes deployments
The user name is derived from the
CNin the client certificatesThe groups are derived from the
Ofields in the client certificateFrom the point of view of the Kubernetes API, users do not exist
(i.e. they are not stored in etcd or anywhere else)
Users can be created (and added to groups) independently of the API
The Kubernetes API can be set up to use your custom CA to validate client certs
Viewing our admin certificate
- Let's inspect the certificate we've been using all this time!
- This command will show the
CNandOfields for our certificate:kubectl config view \--raw \-o json \| jq -r .users[0].user[\"client-certificate-data\"] \| openssl base64 -d -A \| openssl x509 -text \| grep Subject:
Let's break down that command together! 😅
Breaking down the command
kubectl config viewshows the Kubernetes user configuration--rawincludes certificate information (which shows as REDACTED otherwise)-o jsonoutputs the information in JSON format| jq ...extracts the field with the user certificate (in base64)| openssl base64 -d -Adecodes the base64 format (now we have a PEM file)| openssl x509 -textparses the certificate and outputs it as plain text| grep Subject:shows us the line that interests us
→ We are user kubernetes-admin, in group system:masters.
(We will see later how and why this gives us the permissions that we have.)
User certificates in practice
The Kubernetes API server does not support certificate revocation
(see issue #18982)
As a result, we don't have an easy way to terminate someone's access
(if their key is compromised, or they leave the organization)
Option 1: re-create a new CA and re-issue everyone's certificates
→ Maybe OK if we only have a few users; no way otherwiseOption 2: don't use groups; grant permissions to individual users
→ Inconvenient if we have many users and teams; error-proneOption 3: issue short-lived certificates (e.g. 24 hours) and renew them often
→ This can be facilitated by e.g. Vault or by the Kubernetes CSR API
Authentication with tokens
Tokens are passed as HTTP headers:
Authorization: Bearer and-then-here-comes-the-tokenTokens can be validated through a number of different methods:
static tokens hard-coded in a file on the API server
bootstrap tokens (special case to create a cluster or join nodes)
OpenID Connect tokens (to delegate authentication to compatible OAuth2 providers)
service accounts (these deserve more details, coming right up!)
Service accounts
A service account is a user that exists in the Kubernetes API
(it is visible with e.g.
kubectl get serviceaccounts)Service accounts can therefore be created / updated dynamically
(they don't require hand-editing a file and restarting the API server)
A service account is associated with a set of secrets
(the kind that you can view with
kubectl get secrets)Service accounts are generally used to grant permissions to applications, services...
(as opposed to humans)
Token authentication in practice
We are going to list existing service accounts
Then we will extract the token for a given service account
And we will use that token to authenticate with the API
Listing service accounts
- The resource name is
serviceaccountorsafor short:kubectl get sa
There should be just one service account in the default namespace: default.
Finding the secret
- List the secrets for the
defaultservice account:kubectl get sa default -o yamlSECRET=$(kubectl get sa default -o json | jq -r .secrets[0].name)
It should be named default-token-XXXXX.
Extracting the token
- The token is stored in the secret, wrapped with base64 encoding
View the secret:
kubectl get secret $SECRET -o yamlExtract the token and decode it:
TOKEN=$(kubectl get secret $SECRET -o json \| jq -r .data.token | openssl base64 -d -A)
Using the token
- Let's send a request to the API, without and with the token
Find the ClusterIP for the
kubernetesservice:kubectl get svc kubernetesAPI=$(kubectl get svc kubernetes -o json | jq -r .spec.clusterIP)Connect without the token:
curl -k https://$APIConnect with the token:
curl -k -H "Authorization: Bearer $TOKEN" https://$API
Results
In both cases, we will get a "Forbidden" error
Without authentication, the user is
system:anonymousWith authentication, it is shown as
system:serviceaccount:default:defaultThe API "sees" us as a different user
But neither user has any rights, so we can't do nothin'
Let's change that!
Authorization in Kubernetes
There are multiple ways to grant permissions in Kubernetes, called authorizers:
Node Authorization (used internally by kubelet; we can ignore it)
Attribute-based access control (powerful but complex and static; ignore it too)
Webhook (each API request is submitted to an external service for approval)
Role-based access control (associates permissions to users dynamically)
The one we want is the last one, generally abbreviated as RBAC
Role-based access control
RBAC allows to specify fine-grained permissions
Permissions are expressed as rules
A rule is a combination of:
verbs like create, get, list, update, delete...
resources (as in "API resource," like pods, nodes, services...)
resource names (to specify e.g. one specific pod instead of all pods)
in some case, subresources (e.g. logs are subresources of pods)
From rules to roles to rolebindings
A role is an API object containing a list of rules
Example: role "external-load-balancer-configurator" can:
- [list, get] resources [endpoints, services, pods]
- [update] resources [services]
A rolebinding associates a role with a user
Example: rolebinding "external-load-balancer-configurator":
- associates user "external-load-balancer-configurator"
- with role "external-load-balancer-configurator"
Yes, there can be users, roles, and rolebindings with the same name
It's a good idea for 1-1-1 bindings; not so much for 1-N ones
Cluster-scope permissions
API resources Role and RoleBinding are for objects within a namespace
We can also define API resources ClusterRole and ClusterRoleBinding
These are a superset, allowing us to:
specify actions on cluster-wide objects (like nodes)
operate across all namespaces
We can create Role and RoleBinding resources within a namespace
ClusterRole and ClusterRoleBinding resources are global
Pods and service accounts
A pod can be associated with a service account
by default, it is associated with the
defaultservice accountas we saw earlier, this service account has no permissions anyway
The associated token is exposed to the pod's filesystem
(in
/var/run/secrets/kubernetes.io/serviceaccount/token)Standard Kubernetes tooling (like
kubectl) will look for it thereSo Kubernetes tools running in a pod will automatically use the service account
In practice
We are going to create a service account
We will use a default cluster role (
view)We will bind together this role and this service account
Then we will run a pod using that service account
In this pod, we will install
kubectland check our permissions
Creating a service account
We will call the new service account
viewer(note that nothing prevents us from calling it
view, like the role)
Create the new service account:
kubectl create serviceaccount viewerList service accounts now:
kubectl get serviceaccounts
Binding a role to the service account
Binding a role = creating a rolebinding object
We will call that object
viewercanview(but again, we could call it
view)
- Create the new role binding:kubectl create rolebinding viewercanview \--clusterrole=view \--serviceaccount=default:viewer
It's important to note a couple of details in these flags...
Roles vs Cluster Roles
We used
--clusterrole=viewWhat would have happened if we had used
--role=view?we would have bound the role
viewfrom the local namespace
(instead of the cluster roleview)the command would have worked fine (no error)
but later, our API requests would have been denied
This is a deliberate design decision
(we can reference roles that don't exist, and create/update them later)
Users vs Service Accounts
We used
--serviceaccount=default:viewerWhat would have happened if we had used
--user=default:viewer?we would have bound the role to a user instead of a service account
again, the command would have worked fine (no error)
...but our API requests would have been denied later
What's about the
default:prefix?that's the namespace of the service account
yes, it could be inferred from context, but...
kubectlrequires it
Testing
- We will run an
alpinepod and installkubectlthere
Run a one-time pod:
kubectl run eyepod --rm -ti --restart=Never \--serviceaccount=viewer \--image alpineInstall
curl, then use it to installkubectl:apk add --no-cache curlURLBASE=https://storage.googleapis.com/kubernetes-release/releaseKUBEVER=$(curl -s $URLBASE/stable.txt)curl -LO $URLBASE/$KUBEVER/bin/linux/amd64/kubectlchmod +x kubectl
Running kubectl in the pod
- We'll try to use our
viewpermissions, then to create an object
Check that we can, indeed, view things:
./kubectl get allBut that we can't create things:
./kubectl create deployment testrbac --image=nginxExit the container with
exitor^D
Testing directly with kubectl
We can also check for permission with
kubectl auth can-i:kubectl auth can-i list nodeskubectl auth can-i create podskubectl auth can-i get pod/name-of-podkubectl auth can-i get /url-fragment-of-api-request/kubectl auth can-i '*' servicesAnd we can check permissions on behalf of other users:
kubectl auth can-i list nodes \--as some-userkubectl auth can-i list nodes \--as system:serviceaccount:<namespace>:<name-of-service-account>
Where does this view role come from?
Kubernetes defines a number of ClusterRoles intended to be bound to users
cluster-admincan do everything (thinkrooton UNIX)admincan do almost everything (except e.g. changing resource quotas and limits)editis similar toadmin, but cannot view or edit permissionsviewhas read-only access to most resources, except permissions and secrets
In many situations, these roles will be all you need.
You can also customize them!
Customizing the default roles
If you need to add permissions to these default roles (or others),
you can do it through the ClusterRole Aggregation mechanismThis happens by creating a ClusterRole with the following labels:
metadata:labels:rbac.authorization.k8s.io/aggregate-to-admin: "true"rbac.authorization.k8s.io/aggregate-to-edit: "true"rbac.authorization.k8s.io/aggregate-to-view: "true"This ClusterRole permissions will be added to
admin/edit/viewrespectivelyThis is particulary useful when using CustomResourceDefinitions
(since Kubernetes cannot guess which resources are sensitive and which ones aren't)
Where do our permissions come from?
When interacting with the Kubernetes API, we are using a client certificate
We saw previously that this client certificate contained:
CN=kubernetes-adminandO=system:mastersLet's look for these in existing ClusterRoleBindings:
kubectl get clusterrolebindings -o yaml |grep -e kubernetes-admin -e system:masters(
system:mastersshould show up, but notkubernetes-admin.)Where does this match come from?
The system:masters group
If we eyeball the output of
kubectl get clusterrolebindings -o yaml, we'll find out!It is in the
cluster-adminbinding:kubectl describe clusterrolebinding cluster-adminThis binding associates
system:masterswith the cluster rolecluster-adminAnd the
cluster-adminis, basically,root:kubectl describe clusterrole cluster-admin
Figuring out who can do what
For auditing purposes, sometimes we want to know who can perform an action
There are a few tools to help us with that
kubectl-who-can by Aqua Security
Both are available as standalone programs, or as plugins for
kubectl(
kubectlplugins can be installed and managed withkrew)
Pod Security Policies
(automatically generated title slide)
Pod Security Policies
By default, our pods and containers can do everything
(including taking over the entire cluster)
We are going to show an example of a malicious pod
Then we will explain how to avoid this with PodSecurityPolicies
We will enable PodSecurityPolicies on our cluster
We will create a couple of policies (restricted and permissive)
Finally we will see how to use them to improve security on our cluster
Setting up a namespace
For simplicity, let's work in a separate namespace
Let's create a new namespace called "green"
Create the "green" namespace:
kubectl create namespace greenChange to that namespace:
kns green
Creating a basic Deployment
- Just to check that everything works correctly, deploy NGINX
Create a Deployment using the official NGINX image:
kubectl create deployment web --image=nginxConfirm that the Deployment, ReplicaSet, and Pod exist, and that the Pod is running:
kubectl get all
One example of malicious pods
We will now show an escalation technique in action
We will deploy a DaemonSet that adds our SSH key to the root account
(on each node of the cluster)
The Pods of the DaemonSet will do so by mounting
/rootfrom the host
Check the file
k8s/hacktheplanet.yamlwith a text editor:vim ~/container.training/k8s/hacktheplanet.yamlIf you would like, change the SSH key (by changing the GitHub user name)
Deploying the malicious pods
- Let's deploy our "exploit"!
Create the DaemonSet:
kubectl create -f ~/container.training/k8s/hacktheplanet.yamlCheck that the pods are running:
kubectl get podsConfirm that the SSH key was added to the node's root account:
sudo cat /root/.ssh/authorized_keys
Cleaning up
- Before setting up our PodSecurityPolicies, clean up that namespace
Remove the DaemonSet:
kubectl delete daemonset hacktheplanetRemove the Deployment:
kubectl delete deployment web
Pod Security Policies in theory
To use PSPs, we need to activate their specific admission controller
That admission controller will intercept each pod creation attempt
It will look at:
who/what is creating the pod
which PodSecurityPolicies they can use
which PodSecurityPolicies can be used by the Pod's ServiceAccount
Then it will compare the Pod with each PodSecurityPolicy one by one
If a PodSecurityPolicy accepts all the parameters of the Pod, it is created
Otherwise, the Pod creation is denied and it won't even show up in
kubectl get pods
Pod Security Policies fine print
With RBAC, using a PSP corresponds to the verb
useon the PSP(that makes sense, right?)
If no PSP is defined, no Pod can be created
(even by cluster admins)
Pods that are already running are not affected
If we create a Pod directly, it can use a PSP to which we have access
If the Pod is created by e.g. a ReplicaSet or DaemonSet, it's different:
the ReplicaSet / DaemonSet controllers don't have access to our policies
therefore, we need to give access to the PSP to the Pod's ServiceAccount
Pod Security Policies in practice
We are going to enable the PodSecurityPolicy admission controller
At that point, we won't be able to create any more pods (!)
Then we will create a couple of PodSecurityPolicies
...And associated ClusterRoles (giving
useaccess to the policies)Then we will create RoleBindings to grant these roles to ServiceAccounts
We will verify that we can't run our "exploit" anymore
Enabling Pod Security Policies
To enable Pod Security Policies, we need to enable their admission plugin
This is done by adding a flag to the API server
On clusters deployed with
kubeadm, the control plane runs in static podsThese pods are defined in YAML files located in
/etc/kubernetes/manifestsKubelet watches this directory
Each time a file is added/removed there, kubelet creates/deletes the corresponding pod
Updating a file causes the pod to be deleted and recreated
Updating the API server flags
- Let's edit the manifest for the API server pod
Have a look at the static pods:
ls -l /etc/kubernetes/manifestsEdit the one corresponding to the API server:
sudo vim /etc/kubernetes/manifests/kube-apiserver.yaml
Adding the PSP admission plugin
There should already be a line with
--enable-admission-plugins=...Let's add
PodSecurityPolicyon that line
Locate the line with
--enable-admission-plugins=Add
PodSecurityPolicyIt should read:
--enable-admission-plugins=NodeRestriction,PodSecurityPolicySave, quit
Waiting for the API server to restart
The kubelet detects that the file was modified
It kills the API server pod, and starts a new one
During that time, the API server is unavailable
- Wait until the API server is available again
Check that the admission plugin is active
- Normally, we can't create any Pod at this point
- Try to create a Pod directly:kubectl run testpsp1 --image=nginx --restart=Never
Try to create a Deployment:
kubectl run testpsp2 --image=nginxLook at existing resources:
kubectl get all
We can get hints at what's happening by looking at the ReplicaSet and Events.
Introducing our Pod Security Policies
We will create two policies:
privileged (allows everything)
restricted (blocks some unsafe mechanisms)
For each policy, we also need an associated ClusterRole granting use
Creating our Pod Security Policies
We have a couple of files, each defining a PSP and associated ClusterRole:
- k8s/psp-privileged.yaml: policy
privileged, rolepsp:privileged - k8s/psp-restricted.yaml: policy
restricted, rolepsp:restricted
- k8s/psp-privileged.yaml: policy
- Create both policies and their associated ClusterRoles:kubectl create -f ~/container.training/k8s/psp-restricted.yamlkubectl create -f ~/container.training/k8s/psp-privileged.yaml
The privileged policy comes from the Kubernetes documentation
The restricted policy is inspired by that same documentation page
Check that we can create Pods again
We haven't bound the policy to any user yet
But
cluster-admincan implicitlyuseall policies
Check that we can now create a Pod directly:
kubectl run testpsp3 --image=nginx --restart=NeverCreate a Deployment as well:
kubectl run testpsp4 --image=nginxConfirm that the Deployment is not creating any Pods:
kubectl get all
What's going on?
We can create Pods directly (thanks to our root-like permissions)
The Pods corresponding to a Deployment are created by the ReplicaSet controller
The ReplicaSet controller does not have root-like permissions
We need to either:
- grant permissions to the ReplicaSet controller
or
- grant permissions to our Pods' ServiceAccount
The first option would allow anyone to create pods
The second option will allow us to scope the permissions better
Binding the restricted policy
Let's bind the role
psp:restrictedto ServiceAccountgreen:default(aka the default ServiceAccount in the green Namespace)
This will allow Pod creation in the green Namespace
(because these Pods will be using that ServiceAccount automatically)
- Create the following RoleBinding:kubectl create rolebinding psp:restricted \--clusterrole=psp:restricted \--serviceaccount=green:default
Trying it out
The Deployments that we created earlier will eventually recover
(the ReplicaSet controller will retry to create Pods once in a while)
If we create a new Deployment now, it should work immediately
Create a simple Deployment:
kubectl create deployment testpsp5 --image=nginxLook at the Pods that have been created:
kubectl get all
Trying to hack the cluster
- Let's create the same DaemonSet we used earlier
Create a hostile DaemonSet:
kubectl create -f ~/container.training/k8s/hacktheplanet.yamlLook at the state of the namespace:
kubectl get all
What's in our restricted policy?
The restricted PSP is similar to the one provided in the docs, but:
it allows containers to run as root
it doesn't drop capabilities
Many containers run as root by default, and would require additional tweaks
Many containers use e.g.
chown, which requires a specific capability(that's the case for the NGINX official image, for instance)
We still block: hostPath, privileged containers, and much more!
The case of static pods
If we list the pods in the
kube-systemnamespace,kube-apiserveris missingHowever, the API server is obviously running
(otherwise,
kubectl get pods --namespace=kube-systemwouldn't work)The API server Pod is created directly by kubelet
(without going through the PSP admission plugin)
Then, kubelet creates a "mirror pod" representing that Pod in etcd
That "mirror pod" creation goes through the PSP admission plugin
And it gets blocked!
This can be fixed by binding
psp:privilegedto groupsystem:nodes
Before moving on...
Our cluster is currently broken
(we can't create pods in namespaces kube-system, default, ...)
We need to either:
disable the PSP admission plugin
allow use of PSP to relevant users and groups
For instance, we could:
bind
psp:restrictedto the groupsystem:authenticatedbind
psp:privilegedto the ServiceAccountkube-system:default
Fixing the cluster
- Let's disable the PSP admission plugin
Edit the Kubernetes API server static pod manifest
Remove the PSP admission plugin
This can be done with this one-liner:
sudo sed -i s/,PodSecurityPolicy// /etc/kubernetes/manifests/kube-apiserver.yaml
The CSR API
(automatically generated title slide)
The CSR API
The Kubernetes API exposes CSR resources
We can use these resources to issue TLS certificates
First, we will go through a quick reminder about TLS certificates
Then, we will see how to obtain a certificate for a user
We will use that certificate to authenticate with the cluster
Finally, we will grant some privileges to that user
Reminder about TLS
TLS (Transport Layer Security) is a protocol providing:
encryption (to prevent eavesdropping)
authentication (using public key cryptography)
When we access an https:// URL, the server authenticates itself
(it proves its identity to us; as if it were "showing its ID")
But we can also have mutual TLS authentication (mTLS)
(client proves its identity to server; server proves its identity to client)
Authentication with certificates
To authenticate, someone (client or server) needs:
a private key (that remains known only to them)
a public key (that they can distribute)
a certificate (associating the public key with an identity)
A message encrypted with the private key can only be decrypted with the public key
(and vice versa)
If I use someone's public key to encrypt/decrypt their messages,
I can be certain that I am talking to them / they are talking to meThe certificate proves that I have the correct public key for them
Certificate generation workflow
This is what I do if I want to obtain a certificate.
Create public and private keys.
Create a Certificate Signing Request (CSR).
(The CSR contains the identity that I claim and a public key.)
Send that CSR to the Certificate Authority (CA).
The CA verifies that I can claim the identity in the CSR.
The CA generates my certificate and gives it to me.
The CA (or anyone else) never needs to know my private key.
The CSR API
The Kubernetes API has a CertificateSigningRequest resource type
(we can list them with e.g.
kubectl get csr)We can create a CSR object
(= upload a CSR to the Kubernetes API)
Then, using the Kubernetes API, we can approve/deny the request
If we approve the request, the Kubernetes API generates a certificate
The certificate gets attached to the CSR object and can be retrieved
Using the CSR API
We will show how to use the CSR API to obtain user certificates
This will be a rather complex demo
... And yet, we will take a few shortcuts to simplify it
(but it will illustrate the general idea)
The demo also won't be automated
(we would have to write extra code to make it fully functional)
General idea
We will create a Namespace named "users"
Each user will get a ServiceAccount in that Namespace
That ServiceAccount will give read/write access to one CSR object
Users will use that ServiceAccount's token to submit a CSR
We will approve the CSR (or not)
Users can then retrieve their certificate from their CSR object
...And use that certificate for subsequent interactions
Resource naming
For a user named jean.doe, we will have:
ServiceAccount
jean.doein NamespaceusersCertificateSigningRequest
users:jean.doeClusterRole
users:jean.doegiving read/write access to that CSRClusterRoleBinding
users:jean.doebinding ClusterRole and ServiceAccount
Creating the user's resources
If you want to use another name than jean.doe, update the YAML file!
Create the global namespace for all users:
kubectl create namespace usersCreate the ServiceAccount, ClusterRole, ClusterRoleBinding for
jean.doe:kubectl apply -f ~/container.training/k8s/users:jean.doe.yaml
Extracting the user's token
Let's obtain the user's token and give it to them
(the token will be their password)
List the user's secrets:
kubectl --namespace=users describe serviceaccount jean.doeShow the user's token:
kubectl --namespace=users describe secret jean.doe-token-xxxxx
Configure kubectl to use the token
- Let's create a new context that will use that token to access the API
Add a new identity to our kubeconfig file:
kubectl config set-credentials token:jean.doe --token=...Add a new context using that identity:
kubectl config set-context jean.doe --user=token:jean.doe --cluster=kubernetes
Access the API with the token
- Let's check that our access rights are set properly
Try to access any resource:
kubectl get pods(This should tell us "Forbidden")
Try to access "our" CertificateSigningRequest:
kubectl get csr users:jean.doe(This should tell us "NotFound")
Create a key and a CSR
There are many tools to generate TLS keys and CSRs
Let's use OpenSSL; it's not the best one, but it's installed everywhere
(many people prefer cfssl, easyrsa, or other tools; that's fine too!)
- Generate the key and certificate signing request:openssl req -newkey rsa:2048 -nodes -keyout key.pem \-new -subj /CN=jean.doe/O=devs/ -out csr.pem
The command above generates:
- a 2048-bit RSA key, without encryption, stored in key.pem
- a CSR for the name
jean.doein groupdevs
Inside the Kubernetes CSR object
The Kubernetes CSR object is a thin wrapper around the CSR PEM file
The PEM file needs to be encoded to base64 on a single line
(we will use
base64 -w0for that purpose)The Kubernetes CSR object also needs to list the right "usages"
(these are flags indicating how the certificate can be used)
Sending the CSR to Kubernetes
- Generate and create the CSR resource:kubectl apply -f - <<EOFapiVersion: certificates.k8s.io/v1beta1kind: CertificateSigningRequestmetadata:name: users:jean.doespec:request: $(base64 -w0 < csr.pem)usages:- digital signature- key encipherment- client authEOF
Adjusting certificate expiration
By default, the CSR API generates certificates valid 1 year
We want to generate short-lived certificates, so we will lower that to 1 hour
Fow now, this is configured through an experimental controller manager flag
Edit the static pod definition for the controller manager:
sudo vim /etc/kubernetes/manifests/kube-controller-manager.yamlIn the list of flags, add the following line:
- --experimental-cluster-signing-duration=1h
Verifying and approving the CSR
- Let's inspect the CSR, and if it is valid, approve it
Switch back to
cluster-admin:kctx -Inspect the CSR:
kubectl describe csr users:jean.doeApprove it:
kubectl certificate approve users:jean.doe
Obtaining the certificate
Switch back to the user's identity:
kctx -Retrieve the updated CSR object and extract the certificate:
kubectl get csr users:jean.doe \-o jsonpath={.status.certificate} \| base64 -d > cert.pemInspect the certificate:
openssl x509 -in cert.pem -text -noout
Using the certificate
Add the key and certificate to kubeconfig:
kubectl config set-credentials cert:jean.doe --embed-certs \--client-certificate=cert.pem --client-key=key.pemUpdate the user's context to use the key and cert to authenticate:
kubectl config set-context jean.doe --user cert:jean.doeConfirm that we are seen as
jean.doe(but don't have permissions):kubectl get pods
What's missing?
We have just shown, step by step, a method to issue short-lived certificates for users.
To be usable in real environments, we would need to add:
a kubectl helper to automatically generate the CSR and obtain the cert
(and transparently renew the cert when needed)
a Kubernetes controller to automatically validate and approve CSRs
(checking that the subject and groups are valid)
a way for the users to know the groups to add to their CSR
(e.g.: annotations on their ServiceAccount + read access to the ServiceAccount)
Is this realistic?
Larger organizations typically integrate with their own directory
The general principle, however, is the same:
users have long-term credentials (password, token, ...)
they use these credentials to obtain other, short-lived credentials
This provides enhanced security:
the long-term credentials can use long passphrases, 2FA, HSM...
the short-term credentials are more convenient to use
we get strong security and convenience
Systems like Vault also have certificate issuance mechanisms
OpenID Connect
(automatically generated title slide)
OpenID Connect
The Kubernetes API server can perform authentication with OpenID connect
This requires an OpenID provider
(external authorization server using the OAuth 2.0 protocol)
We can use a third-party provider (e.g. Google) or run our own (e.g. Dex)
We are going to give an overview of the protocol
We will show it in action (in a simplified scenario)
Workflow overview
We want to access our resources (a Kubernetes cluster)
We authenticate with the OpenID provider
we can do this directly (e.g. by going to https://accounts.google.com)
or maybe a kubectl plugin can open a browser page on our behalf
After authenticating us, the OpenID provider gives us:
an id token (a short-lived signed JSON Web Token, see next slide)
a refresh token (to renew the id token when needed)
We can now issue requests to the Kubernetes API with the id token
The API server will verify that token's content to authenticate us
JSON Web Tokens
A JSON Web Token (JWT) has three parts:
a header specifying algorithms and token type
a payload (indicating who issued the token, for whom, which purposes...)
a signature generated by the issuer (the issuer = the OpenID provider)
Anyone can verify a JWT without contacting the issuer
(except to obtain the issuer's public key)
Pro tip: we can inspect a JWT with https://jwt.io/
How the Kubernetes API uses JWT
Server side
enable OIDC authentication
indicate which issuer (provider) should be allowed
indicate which audience (or "client id") should be allowed
optionally, map or prefix user and group names
Client side
obtain JWT as described earlier
pass JWT as authentication token
renew JWT when needed (using the refresh token)
Demo time!
We will use Google Accounts as our OpenID provider
We will use the Google OAuth Playground as the "audience" or "client id"
We will obtain a JWT through Google Accounts and the OAuth Playground
We will enable OIDC in the Kubernetes API server
We will use the JWT to authenticate
If you can't or won't use a Google account, you can try to adapt this to another provider.
Checking the API server logs
The API server logs will be particularly useful in this section
(they will indicate e.g. why a specific token is rejected)
Let's keep an eye on the API server output!
- Tail the logs of the API server:kubectl logs kube-apiserver-node1 --follow --namespace=kube-system
Authenticate with the OpenID provider
We will use the Google OAuth Playground for convenience
In a real scenario, we would need our own OAuth client instead of the playground
(even if we were still using Google as the OpenID provider)
Open the Google OAuth Playground:
https://developers.google.com/oauthplayground/Enter our own custom scope in the text field:
https://www.googleapis.com/auth/userinfo.emailClick on "Authorize APIs" and allow the playground to access our email address
Obtain our JSON Web Token
The previous step gave us an "authorization code"
We will use it to obtain tokens
- Click on "Exchange authorization code for tokens"
The JWT is the very long
id_tokenthat shows up on the right hand side(it is a base64-encoded JSON object, and should therefore start with
eyJ)
Using our JSON Web Token
We need to create a context (in kubeconfig) for our token
(if we just add the token or use
kubectl --token, our certificate will still be used)
Create a new authentication section in kubeconfig:
kubectl config set-credentials myjwt --token=eyJ...Try to use it:
kubectl --user=myjwt get nodes
We should get an Unauthorized response, since we haven't enabled OpenID Connect in the API server yet. We should also see invalid bearer token in the API server log output.
Enabling OpenID Connect
We need to add a few flags to the API server configuration
These two are mandatory:
--oidc-issuer-url→ URL of the OpenID provider--oidc-client-id→ app requesting the authentication
(in our case, that's the ID for the Google OAuth Playground)This one is optional:
--oidc-username-claim→ which field should be used as user name
(we will use the user's email address instead of an opaque ID)See the API server documentation for more details about all available flags
Updating the API server configuration
The instructions below will work for clusters deployed with kubeadm
(or where the control plane is deployed in static pods)
If your cluster is deployed differently, you will need to adapt them
Edit
/etc/kubernetes/manifests/kube-apiserver.yamlAdd the following lines to the list of command-line flags:
- --oidc-issuer-url=https://accounts.google.com- --oidc-client-id=407408718192.apps.googleusercontent.com- --oidc-username-claim=email
Restarting the API server
The kubelet monitors the files in
/etc/kubernetes/manifestsWhen we save the pod manifest, kubelet will restart the corresponding pod
(using the updated command line flags)
After making the changes described on the previous slide, save the file
Issue a simple command (like
kubectl version) until the API server is back up(it might take between a few seconds and one minute for the API server to restart)
Restart the
kubectl logscommand to view the logs of the API server
Using our JSON Web Token
- Now that the API server is set up to recognize our token, try again!
- Try an API command with our token:kubectl --user=myjwt get nodeskubectl --user=myjwt get pods
We should see a message like:
Error from server (Forbidden): nodes is forbidden: User "[email protected]"cannot list resource "nodes" in API group "" at the cluster scope→ We were successfully authenticated, but not authorized.
Authorizing our user
As an extra step, let's grant read access to our user
We will use the pre-defined ClusterRole
view
Create a ClusterRoleBinding allowing us to view resources:
kubectl create clusterrolebinding i-can-view \--user=[email protected] --clusterrole=view(make sure to put your Google email address there)
Confirm that we can now list pods with our token:
kubectl --user=myjwt get pods
From demo to production
This was a very simplified demo! In a real deployment...
We wouldn't use the Google OAuth Playground
We probably wouldn't even use Google at all
(it doesn't seem to provide a way to include groups!)
Some popular alternatives:
We would use a helper (like the kubelogin plugin) to automatically obtain tokens
Service Account tokens
The tokens used by Service Accounts are JWT tokens as well
They are signed and verified using a special service account key pair
Extract the token of a service account in the current namespace:
kubectl get secrets -o jsonpath={..token} | base64 -dCopy-paste the token to a verification service like https://jwt.io
Notice that it says "Invalid Signature"
Verifying Service Account tokens
JSON Web Tokens embed the URL of the "issuer" (=OpenID provider)
The issuer provides its public key through a well-known discovery endpoint
(similar to https://accounts.google.com/.well-known/openid-configuration)
There is no such endpoint for the Service Account key pair
But we can provide the public key ourselves for verification
Verifying a Service Account token
On clusters provisioned with kubeadm, the Service Account key pair is:
/etc/kubernetes/pki/sa.key(used by the controller manager to generate tokens)/etc/kubernetes/pki/sa.pub(used by the API server to validate the same tokens)
Display the public key used to sign Service Account tokens:
sudo cat /etc/kubernetes/pki/sa.pubCopy-paste the key in the "verify signature" area on https://jwt.io
It should now say "Signature Verified"
Securing the control plane
(automatically generated title slide)
Securing the control plane
Many components accept connections (and requests) from others:
API server
etcd
kubelet
We must secure these connections:
to deny unauthorized requests
to prevent eavesdropping secrets, tokens, and other sensitive information
Disabling authentication and/or authorization is strongly discouraged
(but it's possible to do it, e.g. for learning / troubleshooting purposes)
Authentication and authorization
Authentication (checking "who you are") is done with mutual TLS
(both the client and the server need to hold a valid certificate)
Authorization (checking "what you can do") is done in different ways
the API server implements a sophisticated permission logic (with RBAC)
some services will defer authorization to the API server (through webhooks)
some services require a certificate signed by a particular CA / sub-CA
In practice
We will review the various communication channels in the control plane
We will describe how they are secured
When TLS certificates are used, we will indicate:
which CA signs them
what their subject (CN) should be, when applicable
We will indicate how to configure security (client- and server-side)
etcd peers
Replication and coordination of etcd happens on a dedicated port
(typically port 2380; the default port for normal client connections is 2379)
Authentication uses TLS certificates with a separate sub-CA
(otherwise, anyone with a Kubernetes client certificate could access etcd!)
The etcd command line flags involved are:
--peer-client-cert-auth=trueto activate it--peer-cert-file,--peer-key-file,--peer-trusted-ca-file
etcd clients
The only¹ thing that connects to etcd is the API server
Authentication uses TLS certificates with a separate sub-CA
(for the same reasons as for etcd inter-peer authentication)
The etcd command line flags involved are:
--client-cert-auth=trueto activate it--trusted-ca-file,--cert-file,--key-fileThe API server command line flags involved are:
--etcd-cafile,--etcd-certfile,--etcd-keyfile
¹Technically, there is also the etcd healthcheck. Let's ignore it for now.
API server clients
The API server has a sophisticated authentication and authorization system
For connections coming from other components of the control plane:
authentication uses certificates (trusting the certificates' subject or CN)
authorization uses whatever mechanism is enabled (most oftentimes, RBAC)
The relevant API server flags are:
--client-ca-file,--tls-cert-file,--tls-private-key-fileEach component connecting to the API server takes a
--kubeconfigflag(to specify a kubeconfig file containing the CA cert, client key, and client cert)
Yes, that kubeconfig file follows the same format as our
~/.kube/configfile!
Kubelet and API server
Communication between kubelet and API server can be established both ways
Kubelet → API server:
kubelet registers itself ("hi, I'm node42, do you have work for me?")
connection is kept open and re-established if it breaks
that's how the kubelet knows which pods to start/stop
API server → kubelet:
- used to retrieve logs, exec, attach to containers
Kubelet → API server
Kubelet is started with
--kubeconfigwith API server informationThe client certificate of the kubelet will typically have:
CN=system:node:<nodename>and groupsO=system:nodesNothing special on the API server side
(it will authenticate like any other client)
API server → kubelet
Kubelet is started with the flag
--client-ca-file(typically using the same CA as the API server)
API server will use a dedicated key pair when contacting kubelet
(specified with
--kubelet-client-certificateand--kubelet-client-key)Authorization uses webhooks
(enabled with
--authorization-mode=Webhookon kubelet)The webhook server is the API server itself
(the kubelet sends back a request to the API server to ask, "can this person do that?")
Scheduler
The scheduler connects to the API server like an ordinary client
The certificate of the scheduler will have
CN=system:kube-scheduler
Controller manager
The controller manager is also a normal client to the API server
Its certificate will have
CN=system:kube-controller-managerIf we use the CSR API, the controller manager needs the CA cert and key
(passed with flags
--cluster-signing-cert-fileand--cluster-signing-key-file)We usually want the controller manager to generate tokens for service accounts
These tokens deserve some details (on the next slide!)
Service account tokens
Each time we create a service account, the controller manager generates a token
These tokens are JWT tokens, signed with a particular key
These tokens are used for authentication with the API server
(and therefore, the API server needs to be able to verify their integrity)
This uses another keypair:
the private key (used for signature) is passed to the controller manager
(using flags--service-account-private-key-fileand--root-ca-file)the public key (used for verification) is passed to the API server
(using flag--service-account-key-file)
kube-proxy
kube-proxy is "yet another API server client"
In many clusters, it runs as a Daemon Set
In that case, it will have its own Service Account and associated permissions
It will authenticate using the token of that Service Account
Webhooks
We mentioned webhooks earlier; how does that really work?
The Kubernetes API has special resource types to check permissions
One of them is SubjectAccessReview
To check if a particular user can do a particular action on a particular resource:
we prepare a SubjectAccessReview object
we send that object to the API server
the API server responds with allow/deny (and optional explanations)
Using webhooks for authorization = sending SAR to authorize each request
Subject Access Review
Here is an example showing how to check if jean.doe can get some pods in kube-system:
kubectl -v9 create -f- <<EOFapiVersion: authorization.k8s.io/v1beta1kind: SubjectAccessReviewspec: user: jean.doe group: - foo - bar resourceAttributes: #group: blah.k8s.io namespace: kube-system resource: pods verb: get #name: web-xyz1234567-pqr89EOF
Next steps
(automatically generated title slide)
Next steps
Alright, how do I get started and containerize my apps?
Next steps
Alright, how do I get started and containerize my apps?
Suggested containerization checklist:
- write a Dockerfile for one service in one app
- write Dockerfiles for the other (buildable) services
- write a Compose file for that whole app
- make sure that devs are empowered to run the app in containers
- set up automated builds of container images from the code repo
- set up a CI pipeline using these container images
- set up a CD pipeline (for staging/QA) using these images
And then it is time to look at orchestration!
Options for our first production cluster
Get a managed cluster from a major cloud provider (AKS, EKS, GKE...)
(price: $, difficulty: medium)
Hire someone to deploy it for us
(price: $$, difficulty: easy)
Do it ourselves
(price: $-$$$, difficulty: hard)
One big cluster vs. multiple small ones
Yes, it is possible to have prod+dev in a single cluster
(and implement good isolation and security with RBAC, network policies...)
But it is not a good idea to do that for our first deployment
Start with a production cluster + at least a test cluster
Implement and check RBAC and isolation on the test cluster
(e.g. deploy multiple test versions side-by-side)
Make sure that all our devs have usable dev clusters
(whether it's a local minikube or a full-blown multi-node cluster)
Namespaces
Namespaces let you run multiple identical stacks side by side
Two namespaces (e.g.
blueandgreen) can each have their ownredisserviceEach of the two
redisservices has its ownClusterIPCoreDNS creates two entries, mapping to these two
ClusterIPaddresses:redis.blue.svc.cluster.localandredis.green.svc.cluster.localPods in the
bluenamespace get a search suffix ofblue.svc.cluster.localAs a result, resolving
redisfrom a pod in thebluenamespace yields the "local"redis
This does not provide isolation! That would be the job of network policies.
Relevant sections
-
(covers permissions model, user and service accounts management ...)
Stateful services (databases etc.)
As a first step, it is wiser to keep stateful services outside of the cluster
Exposing them to pods can be done with multiple solutions:
ExternalNameservices
(redis.blue.svc.cluster.localwill be aCNAMErecord)ClusterIPservices with explicitEndpoints
(instead of letting Kubernetes generate the endpoints from a selector)Ambassador services
(application-level proxies that can provide credentials injection and more)
Stateful services (second take)
If we want to host stateful services on Kubernetes, we can use:
a storage provider
persistent volumes, persistent volume claims
stateful sets
Good questions to ask:
what's the operational cost of running this service ourselves?
what do we gain by deploying this stateful service on Kubernetes?
Relevant sections: Volumes | Stateful Sets | Persistent Volumes
Excellent blog post tackling the question: “Should I run Postgres on Kubernetes?”
HTTP traffic handling
Services are layer 4 constructs
HTTP is a layer 7 protocol
It is handled by ingresses (a different resource kind)
Ingresses allow:
- virtual host routing
- session stickiness
- URI mapping
- and much more!
This section shows how to expose multiple HTTP apps using Træfik
Logging
Logging is delegated to the container engine
Logs are exposed through the API
Logs are also accessible through local files (
/var/log/containers)Log shipping to a central platform is usually done through these files
(e.g. with an agent bind-mounting the log directory)
This section shows how to do that with Fluentd and the EFK stack
Metrics
The kubelet embeds cAdvisor, which exposes container metrics
(cAdvisor might be separated in the future for more flexibility)
It is a good idea to start with Prometheus
(even if you end up using something else)
Starting from Kubernetes 1.8, we can use the Metrics API
Heapster was a popular add-on
(but is being deprecated starting with Kubernetes 1.11)
Managing the configuration of our applications
Two constructs are particularly useful: secrets and config maps
They allow to expose arbitrary information to our containers
Avoid storing configuration in container images
(There are some exceptions to that rule, but it's generally a Bad Idea)
Never store sensitive information in container images
(It's the container equivalent of the password on a post-it note on your screen)
This section shows how to manage app config with config maps (among others)
Managing stack deployments
Applications are made of many resources
(Deployments, Services, and much more)
We need to automate the creation / update / management of these resources
There is no "absolute best" tool or method; it depends on:
- the size and complexity of our stack(s)
- how often we change it (i.e. add/remove components)
- the size and skills of our team
Cluster federation
Cluster federation

Cluster federation
Sorry Star Trek fans, this is not the federation you're looking for!
Cluster federation
Sorry Star Trek fans, this is not the federation you're looking for!
(If I add "Your cluster is in another federation" I might get a 3rd fandom wincing!)
Cluster federation
Kubernetes master operation relies on etcd
etcd uses the Raft protocol
Raft recommends low latency between nodes
What if our cluster spreads to multiple regions?
Cluster federation
Kubernetes master operation relies on etcd
etcd uses the Raft protocol
Raft recommends low latency between nodes
What if our cluster spreads to multiple regions?
Break it down in local clusters
Regroup them in a cluster federation
Synchronize resources across clusters
Discover resources across clusters
Links and resources
(automatically generated title slide)
Links and resources
All things Kubernetes:
- Kubernetes Community - Slack, Google Groups, meetups
- Kubernetes on StackOverflow
- Play With Kubernetes Hands-On Labs
All things Docker:
Everything else:
These slides (and future updates) are on → http://container.training/
